spark streaming
5、 Spark Streaming
Spark streaming是Spark核心API的一个扩展,它对实时流式数据的处理具有可扩展性、高吞吐量、可容错性等特点。我们可以从kafka、flume、Twitter、 ZeroMQ、Kinesis等源获取数据,也可以通过由 高阶函数map、reduce、join、window等组成的复杂算法计算出数据。最后,处理后的数据可以推送到文件系统、数据库、实时仪表盘中。事实上,你可以将处理后的数据应用到Spark的机器学习算法、 图处理算法中去。

在内部,它的工作原理如下图所示。Spark Streaming接收实时的输入数据流,然后将这些数据切分为批数据供Spark引擎处理,Spark引擎将数据生成最终的结果数据。

Spark Streaming支持一个高层的抽象,叫做离散流( discretized stream )或者 DStream ,它代表连续的数据流。DStream既可以利用从Kafka, Flume和Kinesis等源获取的输入数据流创建,也可以 在其他DStream的基础上通过高阶函数获得。在内部,DStream是由一系列RDDs组成。
注意:Spark 1.2已经为Spark Streaming引入了Python API。它的所有DStream transformations和几乎所有的输出操作可以在scala和java接口中使用。然而,它只支持基本的源如文本文件或者套接字上 的文本数据。诸如flume、kafka等外部的源的API会在将来引入。
5.1 一个快速的例子
在我们进入如何编写Spark Streaming程序的细节之前,让我们快速地浏览一个简单的例子。在这个例子中,程序从监听TCP套接字的数据服务器获取文本数据,然后计算文本中包含的单词数。做法如下:
首先,我们导入Spark Streaming的相关类以及一些从StreamingContext获得的隐式转换到我们的环境中,为我们所需的其他类(如DStream)提供有用的方法。StreamingContext 是Spark所有流操作的主要入口。然后,我们创建了一个具有两个执行线程以及1秒批间隔时间(即以秒为单位分割数据流)的本地StreamingContext。
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._ // not necessary in Spark 1.3+
// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent from a starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
利用这个上下文,我们能够创建一个DStream,它表示从TCP源(主机位localhost,端口为9999)获取的流式数据。
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)
这个 lines 变量是一个DStream,表示即将从数据服务器获得的流数据。这个DStream的每条记录都代表一行文本。下一步,我们需要将DStream中的每行文本都切分为单词。
// Split each line into words
val words = lines.flatMap(_.split(" "))
flatMap 是一个一对多的DStream操作,它通过把源DStream的每条记录都生成多条新记录来创建一个新的DStream。在这个例子中,每行文本都被切分成了多个单词,我们把切分 的单词流用 words 这个DStream表示。下一步,我们需要计算单词的个数。
import org.apache.spark.streaming.StreamingContext._ // not necessary in Spark 1.3+
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
words 这个DStream被mapper(一对一转换操作)成了一个新的DStream,它由(word,1)对组成。然后,我们就可以用这个新的DStream计算每批数据的词频。最后,我们用 wordCounts.print() 打印每秒计算的词频。
注意:当以上这些代码被执行时,Spark Streaming仅仅准备好了它要执行的计算,实际上并没有真正开始执行。在
这些转换操作准备好之后,要真正执行计算,需要调用如下的方法
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
完整的例子可以在NetworkWordCount中找到。
如果你已经下载和构建了Spark环境,你就能够用如下的方法运行这个例子。首先,你需要运行Netcat作为数据服务器
$ nc -lk 9999
然后,在不同的终端,你能够用如下方式运行例子
$ ./bin/run-example streaming.NetworkWordCount localhost 9999
然后,打在netcat server上面的一些行将会被计算和打印在每一秒。如下所示
TERMINAL 1:Running Netcat
$ nc -lk 9999
hello world
...
TERMINAL 2: RUNNING NetworkWordCount
$ ./bin/run-example streaming.NetworkWordCount localhost 9999
...
-------------------------------------------
Time: 1357008430000 ms
-------------------------------------------
(hello,1)
(world,1)
...
5.2 基本概念
在了解简单的例子的基础上,下面将介绍编写Spark Streaming应用程序必需的一些基本概念。
5.2.1 Linking
与Spark类似,Spark Streaming也可以利用maven仓库。编写你自己的Spark Streaming程序,你需要引入下面的依赖到你的SBT或者Maven项目中
org.apache.spark
spark-streaming_2.10
1.3.0
为了从Kafka, Flume和Kinesis这些不在Spark核心API中提供的源获取数据,我们需要添加相关的模块 spark-streaming-xyz_2.10 到依赖中。例如,一些通用的组件如下表所示:
| Source | Artifact |
| Kafka | spark-streaming-kafka_2.10 |
| Flume | spark-streaming-flume_2.10 |
| Kinesis | spark-streaming-kinesis-asl_2.10 [Amazon Software License] |
| spark-streaming-twitter_2.10 | |
| ZeroMQ | spark-streaming-zeromq_2.10 |
| MQTT | spark-streaming-mqtt_2.10 |
5.2.2 初始化StreamingContext
为了初始化Spark Streaming程序,一个StreamingContext对象必需被创建,它是Spark Streaming所有流操作的主要入口。一个StreamingContext 对象可以用SparkConf对象创建。
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
appName 表示你的应用程序显示在集群UI上的名字, master 是一个Spark、Mesos、YARN集群URL 或者一个特殊字符串“local[*]”,它表示程序用本地模式运行。当程序运行在集群中时,你并不希望在程序中硬编码 master ,而是希望用 sparksubmit启动应用程序,并从 spark-submit 中得到 master 的值。对于本地测试或者单元测试,你可以传递“local”字符串在同一个进程内运行Spark Streaming。需要注意的是,它在内部创建了一个SparkContext对象,你可以通过 ssc.sparkContext访问这个SparkContext对象。
批时间片需要根据你的程序的潜在需求以及集群的可用资源来设定,你可以在性能调优那一节获取详细的信息。
也可以利用已经存在的 SparkContext 对象创建 StreamingContext 对象。
import org.apache.spark.streaming._
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))
当一个上下文(context)定义之后,你必须按照以下几步进行操作
- 定义输入源,通过创建输入Dstream
- 定义流计算,通过应用transformation 和output 操作到Dstreams
- 使用streamingContext.start()开启接收数据和处理数据
- 使用streamingContext.awaitTermination()等待进程停止(手动或由于错误)。
- 进程能被手动停止使用streamingContext.stop()。
几点需要注意的地方:
- 一旦一个context已经启动,就不能有新的流算子建立或者是添加到context中。
- 一旦一个context已经停止,它就不能再重新启动
- 在JVM中,同一时间只能有一个StreamingContext处于活跃状态
- 在StreamingContext上调用 stop() 方法,也会关闭SparkContext对象。如果只想仅关闭StreamingContext对象,设置 stop() 的可选参数为false
- 一个SparkContext对象可以重复利用去创建多个StreamingContext对象,前提条件是前面的StreamingContext在后面StreamingContext创建之前关闭(不关闭SparkContext)。
5.2.3 离散流(Dstreams)
离散流或者DStreams是Spark Streaming提供的基本的抽象,它代表一个连续的数据流。它要么是从源中获取的输入流,要么是输入流通过转换算子生成的处理后的数据流。在内部,DStreams由一系列连续的 RDD组成。DStreams中的每个RDD都包含确定时间间隔内的数据,如下图所示:

任何对DStreams的操作都转换成了对DStreams隐含的RDD的操作。在前面的例子中, flatMap 操作应用于 lines 这个DStreams的每个RDD,生成 words 这个DStreams的 RDD。过程如下图所示:

通过Spark引擎计算这些隐含RDD的转换算子。DStreams操作隐藏了大部分的细节,并且为了更便捷,为开发者提供了更高层的API。下面几节将具体讨论这些操作的细节。
5.2.4 Input DStreams and Receivers
输入DStreams表示从数据源获取输入数据流的DStreams。在快速例子中, lines 表示输入DStream,它代表从netcat服务器获取的数据流。每一个输入流DStream 和一个 Receiver 对象相关联,这个 Receiver 从源中获取数据,并将数据存入内存中用于处理。
输入DStreams表示从数据源获取的原始数据流。Spark Streaming拥有两类数据源
- 基本源(Basic sources):这些源在StreamingContext API中直接可用。例如文件系统、套接字连接、Akka的actor等。
- 高级源(Advanced sources):这些源包括Kafka,Flume,Kinesis,Twitter等等。它们需要通过额外的类来使用。我们在关联那一节讨论了类依赖。
需要注意的是,如果你想在一个流应用中并行地创建多个输入DStream来接收多个数据流,你能够创建多个输入流(这将在性能调优那一节介绍) 。它将创建多个Receiver同时接收多个数据流。但是, receiver 作为一个长期运行的任务运行在Spark worker或executor中。因此,它占有一个核,这个核是分配给Spark Streaming应用程序的所有核中的一个。所以,为Spark Streaming应用程序分配足够的核(如果是本地运行,那么是线程) 用以处理接收的数据并且运行 receiver 是非常重要的。
几点需要注意的地方:
- 当运行在集群模式时,如果分配给应用程序的核的数量少于或者等于输入DStreams或者receivers的数量,系统只能够接收数据而不能处理它们。
- 当运行在本地,如果你的master URL被设置成了“local”,这样就只有一个核运行任务。这对程序来说是不足的,因为作为 receiver 的输入DStream将会占用这个核,这样就没有剩余的核来处理数据了。
5.2.4.1 基本源(Basic Sources)
我们已经在快速例子中看到, ssc.socketTextStream(…) 方法用来把从TCP套接字获取的文本数据创建成DStream。除了套接字,StreamingContext API也支持把文件以及Akka actors作为输入源创建DStream。
文件流(File Streams):从任何与HDFS API兼容的文件系统中读取数据,一个DStream可以通过如下方式创建
streamingContext.fileStream[keyClass,valueClass,inputFormatClass] (dataDirectory)
Spark Streaming将会监控 dataDirectory 目录,并且处理目录下生成的任何文件(嵌套目录不被支持)。需要注意一下三点:
1. 所有文件必须具有相同的数据格式
2. 所有文件必须在`dataDirectory`目录下创建,文件是自动的移动和重命名到数据目录下
3. 一旦移动,文件必须被修改。所以如果文件被持续的附加数据,新的数据不会被读取。
对于简单的文本文件,有一个更简单的方法 streamingContext.textFileStream(dataDirectory) 可以被调用。文件流不需要运行一个receiver,所以不需要分配核。
在Spark1.3.0中, fileStream 在Python API中不可用,只有 textFileStream 可用。
- 基于自定义actor的流:DStream可以调用streamingContext.actorStream(actorProps, actor-name)方法从Akka actors获取的数据流来创建
- RDD队列作为数据流:为了用测试数据测试Spark Streaming应用程序,人们也可以调用streamingContext.queueStream(queueOfRDDs) 方法基于RDD队列创建DStreams。每个push到队列的RDD都被当做DStream的批数据,像流一样处理。
5.2.4.2 高级源(Advanced Sources)
Python API:高级数据源中,在Python中仅仅可以获得Kafka。
这类源需要非Spark库接口,并且它们中的部分还需要复杂的依赖(例如kafka和flume)。为了减少依赖的版本冲突问题,从这些源创建DStream的功能已经被移到了独立的库中。例如,如果你想用来自推特的流数据创建
DStream,你需要按照如下步骤操作:
1. 关联:添加 spark-streaming-twitter_2.10 到SBT或maven项目的依赖中
2. 编写:导入 TwitterUtils 类,用 TwitterUtils.createStream 方法创建DStream,如下所示:
import org.apache.spark.streaming.twitter._
TwitterUtils.createStream(ssc, None)
3. 部署:将编写的程序以及其所有的依赖(包括spark-streaming-twitter_2.10的依赖以及它的传递依赖)打为jar包,然后部署
注意:高级源不能在Spark shell中获取,因此基于高级源的应用不能在shell中应用。如果想用Spark shell,必须下载相应的maven artifact’s JAR包,并配置classpath。
下面是部分高级源:
- Kafka:Spark Streaming 1.3.0 兼容Kafka 0.8.1.1
- Flume:Spark Streaming 1.3.0 兼容Flume 1.4.0
- Kinesis
- Twitter:Twitter:Spark Streaming利用 Twitter4j 3.0.3 获取公共的推文流,这些推文通过推特流API获得。认证信息可以通过Twitter4J库支持的 任何方法提供。你既能够得到公共流,也能够得到基于关键字过滤后的流。
5.2.4.3 自定义源(Custom Sources)
Python API:Python暂不支持
输入DStream也可以通过自定义源创建,你需要做的是实现用户自定义的 receiver ,这个 receiver 可以从自定义源接收数据以及将数据推到Spark中。
5.2.4.4 Receiver可靠性(Receiver Reliability)
基于可靠性有两类数据源。源(如kafka、flume)允许。如果从这些可靠的源获取数据的系统能够正确的应答所接收的数据,它就能够确保在任何情况下不丢失数据。这样,就有两种类型的receiver:
- Reliable Receiver:一个可靠的receiver正确的应答一个可靠的源,数据已经收到并且被正确地复制到了Spark中。
- Unreliable Receiver :这些receivers不支持应答。即使对于一个可靠的源,开发者可能实现一个非可靠的receiver,这个receiver不会正确应答。
5.2.5 Transformations on DStreams
和RDD类似,transformation允许从输入DStream来的数据被修改。DStreams支持很多在RDD中可用的transformation算子。一些常用的算子如下所示:
| Transformation | Meaning |
| map(func) | Return a new DStream by passing each element of the source DStream through a function func. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items. |
| filter(func) | Return a new DStream by selecting only the records of the source DStream on which func returns true. |
| repartition(numPartitions) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| union(otherStream) | Return a new DStream that contains the union of the elements in the source DStream and otherDStream. |
| count() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
| reduce(func) | Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative so that it can be computed in parallel. |
| countByValue() | When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
| reduceByKey(func, [numTasks]) | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. Note: By default, this uses Spark’s default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| join(otherStream, [numTasks]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| cogroup(otherStream, [numTasks]) | When called on DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| transform(func) | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| updateStateByKey(func) | Return a new “state” DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
5.2.5.1 UpdateStateByKey操作
updateStateByKey操作允许不断用新信息更新它的同时保持任意状态。你需要通过两步来使用它:
- 定义状态-状态可以是任何的数据类型
- 定义状态更新函数-怎样利用更新前的状态和从输入流里面获取的新值更新状态
让我们举个例子说明。在例子中,你想保持一个文本数据流中每个单词的运行次数,运行次数用一个state表示,它的类型是整数。下面是更新函数定义:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}
这个函数被用到了DStream包含的单词(像上面例子,pairs DStream包含(word,1))上。
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)
这个更新函数将会被每一个单词调用,newValues 有一个1的序列(来自(word,1)对),runningCount有一个之前的计数。对于完全的Scala代码,看实例StatefulNetworkWordCount.scala.
注意:使用 updateStateByKey 需要配置 checkpoint 目录,这被讨论在checkpointing 部分。
5.2.5.2 Transform 操作
transform 操作(以及它的变化形式如 transformWith )允许在DStream运行任何RDD-to-RDD函数。它能够被用来应用任何没在DStream API中提供的RDD操作。例如,连接数据流中的每个批(batch)和另外一个数据集的功能并没有在DStream API中提供,然而你可以简单的利用 transform 方法做到。如果你想通过连接带有预先计算的垃圾邮件信息的输入数据流来清理实时数据,然后过滤它们,你可以按如下方法来做:
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform(rdd => {
rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
...
})
事实上,你也可以使用 机器学习 和 图计算 在transform 方法中。
5.2.5.3 Window 操作
Spark Streaming 也提供了 Window 计算,那允许你应用transformations到一个sliding window的数据。下图是对滑动窗口的说明。
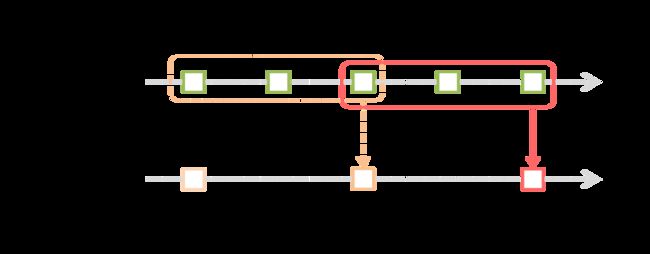
像上图所示,每次窗口在源DStream滑动,落在窗口内的源RDD被组合和操作产生窗口化DStream 的RDDs。在这个具体的例子中,操作至少应用到3个数据的时间单元,滑动间隔为2个时间单元。这说明了任何window 操作需要指定两个参数。
- window length – 窗口持续时间(在图中为3)
- sliding interval – 窗口操作执行的时间间隔(图中为2)
这两个参数必须是源DStream批间隔的倍数。
下面举例说明窗口操作。例如,你想扩展前面的例子用来计算过去30秒的词频,间隔时间是10秒。为了达到这个目的,我们必须在过去30秒的 pairs DStream上应用 reduceByKey 操作。用方法 reduceByKeyAndWindow 实现。
// Reduce last 30 seconds of data, every 10 seconds
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
一些通用的窗口操作如下所示,所有这些操作都有上面提到的两个参数:windowLength 和 slideInterval。
| Transformation | Meaning |
| window(windowLength, slideInterval) | Return a new DStream which is computed based on windowed batches of the source DStream. |
| countByWindow(windowLength, slideInterval) | Return a sliding window count of elements in the stream. |
| reduceByWindow(func, windowLength, slideInterval) | Return a new single-element stream, created by aggregating elements in the stream over a sliding interval using func. The function should be associative so that it can be computed correctly in parallel. |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function func over batches in a sliding window. Note: By default, this uses Spark’s default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | A more efficient version of the above reduceByKeyAndWindow() where the reduce value of each window is calculated incrementally using the reduce values of the previous window. This is done by reducing the new data that enter the sliding window, and “inverse reducing” the old data that leave the window. An example would be that of “adding” and “subtracting” counts of keys as the window slides. However, it is applicable to only “invertible reduce functions”, that is, those reduce functions which have a corresponding “inverse reduce” function (taken as parameter invFunc. Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. Note that [checkpointing](#checkpointing) must be enabled for using this operation. |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the value of each key is its frequency within a sliding window. Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. |
5.2.5.4 Join 操作
最后,在 Spark Streaming中,实现不同种类的joins非常容易,值得关注。
Stream-stream joins
流可以非常容易和其他流进行join。
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)
这里,在每一个批间隔,stream1会和stream2进行join操作,你也可以使用leftOuterJoin,rightOuterJoin,fullOuterJoin。除此之外,连接基于stream的windows也是非常有用的,那也是非常容易的。
val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)
Stream-dataset joins
这已经在之前被展示当解释DStream.transform操作的时候。这是其他的一个实例,将一个window Stream 和 数据集进行join操作。
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }
在事实上,你可以动态的改变数据集(你想join)。这个功能提供了transform 在每一个批间隔被评估,因此你可以使用当前数据集(dataset指向的参考点)
5.2.6 DStreams 输出操作
输出操作允许DStream的数据推到外部系统像数据库或者文件系统。因为输出操作实际上是允许外部系统消费转换后的数据,它们触发的实际操作是DStream转换(相似于RDD的action)。当前,下面输出操作被定义:
| Output Operation | Meaning |
| print() | Prints first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. Python API: This is called pprint() in the Python API. |
| saveAsTextFiles(prefix, [suffix]) | Save this DStream’s contents as a text files. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream’s contents as a SequenceFile of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. Python API:This is not available in the Python API. |
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream’s contents as a Hadoop file. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. Python API: This is not available in the Python API. |
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to a external system, like saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
5.2.6.1 使用foreachRDD的设计模式
dstream.foreachRDD是一个强大的原语,允许数据发送到外部系统中。然而,明白如何高效和正确的使用此原语是很重要的。下面介绍如何避免一般错误。
经常写数据到外部系统需要创建一个连接对象(例:TCP连接到远程对象),使用它发送数据到远程系统。为了达到这个目的,开发人员可能不经意的在Spark驱动中创建一个连接对象,而且在Spark worker中尝试调用这个连接对象保存记录到RDD中,如下:
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach { record =>
connection.send(record) // executed at the worker
}
}
这是不正确的,因为这需要先序列化连接对象,然后将它从driver发送到worker中。这样的连接对象在机器之间不能传送。它可能表现为序列化错误(连接对象不可序列化)或者初始化错误(连接对象应该 在worker中初始化)等等。正确的解决办法是在worker中创建连接对象。
然而,这会造成另外一个常见的错误-为每一个记录创建了一个连接对象。例如:
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
通常,创建一个连接对象有资源和时间的开支。因此,为每个记录创建和销毁连接对象会导致非常高的开支,明显的减少系统的整体吞吐量。一个更好的解决办法是利用 rdd.foreachPartition 方法。为RDD的partition创建一个连接对象,用这个两件对象发送partition中的所有记录。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
这就将连接对象的创建开销分摊到了partition的所有记录上了。
最后,可以通过在多个RDD或者批数据间重用连接对象做更进一步的优化。开发者可以保有一个静态的连接对象池,重复使用池中的对象将多批次的RDD推送到外部系统,以进一步节省开支。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
需要注意的是,池中的连接对象应该根据需要延迟创建,并且在空闲一段时间后自动超时。这样就获取了最有效的方式发生数据到外部系统。
其他需注意地方:
- 输出操作通过懒执行的方式操作DStreams,正如RDD action通过懒执行的方式操作RDD。具体地看,RDD actions和DStreams输出操作接收数据的处理。因此,如果你的应用程序没有任何输出操作或者用于输出操作 dstream.foreachRDD() ,但是没有任何RDD action操作在 dstream.foreachRDD() 里面,那么什么也不会执行。系统仅仅会接收输入,然后丢弃它们。
- 默认情况下,DStreams输出操作是一次性的,它们按照应用程序的定义顺序按序执行。
5.2.7 DataFrames 和 SQL 操作
你可以容易的使用DataFrames 和 SQL 操作在流数据中。你必须使用SparkContext(StreamingContext 正在使用的)创建一个SQLContext。除此之外,这必须可以重启当driver失败后。这被做通过创建一个懒得初始化SQLContext单列实例。这些被展示在下面实例中,它修改之前的word count实例,使用DataFrames 和 SQL产生word 数量。每一个RDD被转化为DataFrame,注册为临时表,然后使用SQL查询。
/** Lazily instantiated singleton instance of SQLContext */
object SQLContextSingleton {
@transient private var instance: SQLContext = null
// Instantiate SQLContext on demand
def getInstance(sparkContext: SparkContext): SQLContext = synchronized {
if (instance == null) {
instance = new SQLContext(sparkContext)
}
instance
}
}
...
/** Case class for converting RDD to DataFrame */
case class Row(word: String)
...
/** DataFrame operations inside your streaming program */
val words: DStream[String] = ...
words.foreachRDD { rdd =>
// Get the singleton instance of SQLContext
val sqlContext = SQLContextSingleton.getInstance(rdd.sparkContext)
import sqlContext.implicits._
// Convert RDD[String] to RDD[case class] to DataFrame
val wordsDataFrame = rdd.map(w => Row(w)).toDF()
// Register as table
wordsDataFrame.registerTempTable("words")
// Do word count on DataFrame using SQL and print it
val wordCountsDataFrame =
sqlContext.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}
看全部源码
你也可以使用不同的线程(异步运行StreamingContext)运行查询在表(被定义基于流数据)。仅仅确认你设置的StreamingContext 记录充足的流数据(查询能运行)。否则,StreamingContext不会感觉到任何的异步SQL查询,将会删除老的数据在查询完成之前。例如,如果你想查询最后批数据,但是你的查询花费了5分钟运行,然后调用streamingContext.remember(Minutes(5))。
5.2.8 MLlib 操作
你也可以使用mllib提供的机器学习算法。首先,有流机器学习算法(流线形回归,流聚类等),他们能连续的从流数据学习,并将模型应用于流数据。除此之外,对于大部分机器学习算法,你可以离线学习一个模型(使用历史数据),然后在线应用模型在流数据上。
5.2.9 缓存或持久化操作
和RDD相似,DStreams也允许开发者持久化流数据到内存中。在DStream上使用 persist() 方法可以自动地持久化DStream中的RDD到内存中。如果DStream中的数据需要计算多次,这是非常有用的。像 reduceByWindow 和 reduceByKeyAndWindow 这种窗口操作、 updateStateByKey 这种基于状态的操作,持久化是默认的,不需要开发者调用 persist() 方法。
通过网络(如kafka,flume,socket等)获取的输入数据流,默认的持久化策略是复制数据到两个不同的节点以容错。
注意,与RDD不同的是,DStreams默认持久化级别是存储序列化数据到内存中,这将在性能调优章节介绍。更多的信息请看rdd持久化。
5.2.10 Checkpointing
一个流应用程序必须24/7运行,所有必须有弹性对应用程序逻辑无关的故障(如系统错误,JVM崩溃等)。为了使这成为可能,Spark Streaming需要checkpoint足够的信息到容错存储系统中, 以使系统从故障中恢复。有两种checkpointing 数据类型。
- Metadata checkpointing: 保存流计算的定义信息到容错存储系统如HDFS中。这用来恢复应用程序中运行driver的节点的故障。元数据包括:
- Configuration :创建Spark Streaming应用程序的配置信息
- DStream operations :定义Streaming应用程序的操作集合
- Incomplete batches:操作存在队列中的未完成的批
- Data checkpointing : 保存生成的RDD到可靠的存储系统中,这在有状态transformation(如结合跨多个批次的数据)中是必须的。在这样一个transformation中,生成的RDD依赖于之前 批的RDD,随着时间的推移,这个依赖链的长度会持续增长。在恢复的过程中,为了避免这种无限增长。有状态的transformation的中间RDD将会定时地存储到可靠存储系统中,以截断这个依赖链。
元数据checkpoint主要是为了从driver故障中恢复数据。如果transformation操作被用到了,数据checkpoint即使在简单的操作中都是必须的。
5.2.10.1 何时启动Checkpointing
应用程序在任何下面需求下必须开启checkpoint:
- 使用有状态的transformation – 如果在应用程序中用到了 updateStateByKey 或者 reduceByKeyAndWindow,checkpoint目录必需提供用以定期checkpoint RDD。
- 从运行应用程序的driver的故障中恢复过来–Metadata checkpoints被用来恢复处理信息
注意:没有前述的有状态的transformation的简单流应用程序在运行时可以不开启checkpoint。在这种情况下,从driver故障的恢复将是部分恢复(接收到了但是还没有处理的数据将会丢失)。 这通常是可以接受的,许多运行的Spark Streaming应用程序都是这种方式。
5.2.10.2 如何配置Checkpointing
Checkpointing可以被启动通过设置一个目录在一个容错的、可靠的文件系统(HDFS,S3等)来保存信息。可以坐这通过使用streamingContext.checkpoint(checkpointDirectory)。这将会允许你使用上述的转台转换。除此之外,如果你想从driver故障中恢复,你应该以下面的方式重写你的Streaming应用程序。
- 当应用程序是第一次启动,新建一个StreamingContext,启动所有Stream,然后调用 start() 方法
- 当应用程序因为故障重新启动,它将会从checkpoint目录的checkpoint数据重新创建StreamingContext
这种行为通过使用StreamingContext.getOrCreate可以简单实现,如下所示:
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams
...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc
}
// Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// Do additional setup on context that needs to be done,
// irrespective of whether it is being started or restarted
context. ...
// Start the context
context.start()
context.awaitTermination()
如果 checkpointDirectory 存在,上下文将会利用checkpoint数据重新创建。如果这个目录不存在,将会调用 functionToCreateContext 函数创建一个新的上下文,建立DStreams。
除了使用 getOrCreate ,开发者必须保证在故障发生时,driver处理自动重启。只能通过部署运行应用程序的基础设施来达到该目的。在部署章节将有更进一步的讨论。
注意: RDDs的checkpointing 会引起可靠存储成本的花费。这会导致批数据(包含的RDD被checkpoint)的处理时间增加。因此,checkpointing 的时间间隔必须小心设置。在最小的批容量(包含1秒的数据)情况下,checkpoint每批数据会显著的减少操作的吞吐量。相反,checkpointing 太少,会引起血统(lineage)和任务量增加,这可能产生有害的影响。对于状态转换要求的RDD checkpointing,默认的间隔是批间隔时间的倍数,至少为10秒。它可以通过dstream.checkpoint(checkpointInterval)设置。一个Dstream滑动间隔的5-10倍的checkpoint 间隔是一个好的尝试。
5.2.11 部署应用程序
5.2.11.1 Requirements
运行一个Spark Streaming应用程序,有下面一些步骤:
- 有管理器的集群–这是任何Spark应用程序都需要的需求
- 将应用程序打为jar包–你必须编译你的应用程序为jar包。如果你用spark-submit启动应用程序,你不需要将Spark和Spark Streaming打包进这个jar包。 如果你的应用程序用到了高级源(如kafka,flume),你需要将它们关联的外部artifact以及它们的依赖打包进需要部署的应用程序jar包中。例如,一个应用程序用到了 TwitterUtils ,那么就需要将 sparkstreaming-twitter_2.10 以及它的所有依赖打包到应用程序jar中。
- 为executors配置足够的内存–因为接收的数据必须存储在内存中,executors必须配置足够的内存用来保存接收的数据。注意,如果你正在做10分钟的窗口操作,系统的内存要至少能保存10分钟的数据。所以,应用程序的内存需求依赖于使用它的操作。
- 配置checkpointing–如果stream应用程序需要checkpointing,然后一个与Hadoop API兼容的容错存储目录(hdfs,s3)必须配置为检查点的目录,流应用程序将checkpoint信息写入该目录用于错误恢复。
配置应用程序driver的自动重启–为了自动从driver故障中恢复,运行流应用程序的部署设施必须能监控driver进程,如果失败了能够重启它。不同的集群管理器,有不同的工具得到该功能。
- Spark Standalone:一个Spark应用程序driver可以提交到Spark独立集群运行,也就是说driver运行在一个worker节点上。进一步来看,独立的集群管理器能够被指示用来监控driver,并且在driver失败(或者是由于非零的退出代码如exit(1),或者由于运行driver的节点的故障)的情况下重启driver。看集群模式和监督更多细节在Spark Standalone guide
- YARN:YARN为自动重启应用程序提供了类似的机制。
- Mesos: Mesos可以用Marathon提供该功能。
【从Spark 1.2开始】配置write ahead logs–为了获得极强的容错保证,我们引入了一个新的实验性的特性-预写日志(write ahead logs)。如果该特性开启,从receiver获取的所有数据会将预写日志写入配置的checkpoint目录。 这可以防止driver故障丢失数据,从而保证零数据丢失。这个功能可以通过设置配置参数 spark.streaming.receiver.writeAheadLogs.enable 为true来开启。然而,这些较强的语义可能以receiver的接收吞吐量为代价。这可以通过 并行运行多个receiver增加吞吐量来解决。另外,当预写日志开启时,Spark中的复制数据的功能推荐不用,因为该日志已经存储在了一个副本在存储系统中。可以通过设置输入DStream的存储级别
为 StorageLevel.MEMORY_AND_DISK_SER 获得该功能。
5.2.11.2 更新应用程序代码
如果运行的Spark Streaming应用程序需要更新新的应用程序代码,有两种可能的方法:
- 启动升级的应用程序,使其与未升级的应用程序并行运行。一旦新的程序(与就程序接收相同的数据)已经热身和准备就绪,旧的应用程序就可以关闭。这种方法支持将数据发送到两个不同的目的地(新程序一个,旧程序一个)
- 现有的应用程序优雅的关闭(看StreamingContext.stop(…) 或者JavaStreamingContext.stop(…)对优雅关闭选项),这确保接收到的数据在关闭前被完全处理。然后,就可以启动升级的应用程序,升级的应用程序会接着旧应用程序的点开始处理。注意,这种方法仅仅支持源端具有缓存功能的输入源(Flume,Kafka),当旧的应用程序关闭,新的应用程序未启动时,数据需要被缓存。重新开始从较早的升级前没有处理的checkpoint 信息。checkpoint 本质上包含序列化Scala/Python对象,尝试反序列化对象使用新的修改的类可能导致错误。在这种情况下,或者开始更新应用程序使用一个不同的checkpoint 目录,或者删除过去的checkpoint 目录。
5.2.11.3 其他考虑
如果数据接收比处理速度快,你能限制比例通过设置配置参数spark.streaming.receiver.maxRate.
5.2.12 监控应用程序
除了Spark的监控功能,Spark Streaming增加了一些专有的功能。应用StreamingContext的时候,Spark web UI 显示添加的 Streaming 菜单,用以显示运行的receivers(receivers是否是存活状态、接收的记录数、receiver错误等)和完成的批的统计信息(批处理时间、队列等待等待)。这可以用来监控 流应用程序的处理过程。
下面两个在web UI上的度量指标是非常重要的:
- 处理时间:每批数据处理的时间。
- 调度延迟:批在队列中等待前一个批处理完成的时间
如果批处理时间比批间隔时间持续更长或者队列等待时间持续增加,这就预示系统无法以批数据产生的速度处理这些数据,整个处理过程滞后了。在这种情况下,考虑减少批处理时间。
Spark Streaming程序的处理过程也可以通过StreamingListener接口来监控,,这 个接口允许你获得receiver状态和处理时间。注意,这个接口是开发者API,它有可能在未来提供更多的信息。
5.3 性能调优
集群中的Spark Streaming应用程序获得最好的性能需要一些调整。这章将介绍几个参数和配置,提高Spark Streaming应用程序的性能。你需要考虑两件事情:
- 高效地利用集群资源减少批数据的处理时间
- 设置正确的批容量(size),使数据的处理速度能够赶上数据的接收速度
5.3.1 减少批处理时间
在Spark中有几个优化可以减少批处理的时间。这些在优化指南中做了详细介绍。这节重点讨论几个重要的。
数据接收的并行水平
接收数据通过网络(如kafka,flume,socket等)需要这些数据反序列化并被保存到Spark中。如果接收数据变成系统的瓶颈,考虑并行数据接收。注意,每一个输入Dstream创建一个单独的receiver(运行在一个worker机器中)接收单个数据流。创建多个输入DStream并配置它们可以从源中接收不同分区的数据流,从而实现多数据流接收。例如,一个单一kafka输入Dstreams接收两个数据主题,可以分割成两个kafka输入Dstreams,每一个接收仅仅一个主题。这将会运行两个receivers在workers,因此运行数据被并行的接收,提高整体吞吐量。多个DStream可以被合并生成单个DStream。这样运用在单个输入DStream的transformation操作可以运用在统一的Dstream上。实例如下:
val numStreams = 5
val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) }
val unifiedStream = streamingContext.union(kafkaStreams)
unifiedStream.print()
另外一个需要考虑的参数是 receiver 的阻塞间隔。这被决定通过配置参数中的spark.streaming.blockInterval。对于大部分receivers,接收到的数据被合并成数据块,在存储到spark内存之前。在每一批中块的数目决定了任务的个数,这些任务是用来处理接收数据用像map的transformation操作。每批每个接收器的任务数量可以估算(批间隔/块间隔)。例如,2秒的批间隔和200毫秒的块间隔将会产生10个任务。任务数量过少(少于每台机器可用核数),所有可以获得的核不能充分使用来处理数据。为了增加给定批间隔任务的数量,降低块间隔。然而,推荐最小的块间隔为50毫秒,低于这个数值,任务发生开销就会是一个问题。
多输入streams/receivers接收数据的一个替代方案是明确的重新分片输入数据流(使用inputStream.repartition())。这分布接收批数据到集群指定数量机器上,在更多处理之前。
数据处理的并行水平
如果运行在计算stage上的并发任务数不足够大,就不会充分利用集群的资源。例如,对于分布式reduce操作,像 reduceByKey 和 reduceByKeyAndWindow ,默认的并发任务数通过配置属性来确定(configuration properties)spark.default.parallelism 。你可以通过参数( PairDStreamFunctions)传递并行度,或者设置参数spark.default.parallelism 修改默认值。
数据序列化
数据序列化的开销可以降低通过调整序列化格式。在流中,有两种数据需要被序列化:
- 输入数据: 默认,receivers接收到的数据需要存储在executors内存里,以StorageLevel.MEMORY_AND_DISK_SER_2的方式。数据被序列化减少了GC的开销,副本可以用来executor故障恢复。数据首先保存在内存里,如果内存不足够存储所有计算需要的数据,则写入硬盘中。序列化显然也有开销,receiver必须反序列化接收到的数据,然后重新序列化它使用spark序列化格式。
- 持久化流操作产生的RDDs:流计算产生的RDDs可能被保存在内存里。例如,窗口操作需要持久化多个时间批数据到内存。然而,不像spark,默认的RDDs以 StorageLevel.MEMORY_ONLY_SER方式持久化到内存中,减少了GC的开销。
在上面两种情形中,使用Kryo序列化能降低CPU和内存的开销。
在特定情况下,流应用程序需要存储的数据量不大,持久化数据作为反序列化对象不会引起大量的GC开销。例如,如果使用几秒的批间隔和不使用窗口操作,你可以尝试不使用序列化存储数据,这将会减少CPU的开销,提高了性能,仅仅增大了不是很多的GC开销。
发送任务开销
如果每秒发送任务比较多(比如 每秒50或者更多),发送任务到slave的花费明显,这使请求很难获得亚秒(sub-second)级别的延迟。花销可以降低通过下面改变:
- 任务序列化: 使用Kryo序列化任务可以减小任务的大小,因此可以减小发送任务到slave的时间。
- 执行模式: 在Standalone模式下或者粗粒度的Mesos模式下运行Spark可以在比细粒度Mesos模式下运行Spark获得更短的任务启动时间。
5.3.2 设置正确的批间隔
为了Spark Streaming应用程序能够在集群中稳定运行,系统应该能够以足够的速度处理接收的数据(即处理速度应该大于或等于接收数据的速度)。这可以通过流的网络UI观察得到。批处理时间应该小于批间隔时间。
根据流计算的性质,批间隔时间可能显著的影响数据处理速率,这个速率可以通过应用程序维持。可以考虑 WordCountNetwork 这个例子,对于一个特定的数据处理速率,系统可能可以每2秒打印一次单词计数 (批间隔时间为2秒),但无法每500毫秒打印一次单词计数。所以,为了在生产环境中维持期望的数据处理速率,就应该设置合适的批间隔时间(即批数据的容量)。
找出正确的批容量的一个好的办法是用一个保守的批间隔时间(5-10,秒)和低数据速率来测试你的应用程序。为了验证你的系统是否能满足数据处理速率,你可以通过检查端到端的延迟值来判断(可以在 Spark驱动程序的log4j日志中查看”Total
delay”或者利用StreamingListener接口)。如果延迟维持稳定,那么系统是稳定的。如果延迟持续增长,那么系统无法跟上数据处理速率,是不稳定的。 你能够尝试着增加数据处理速率或者减少批容量来作进一步的测试。注意,因为瞬间的数据处
理速度增加导致延迟瞬间的增长可能是正常的,只要延迟能重新回到了低值(小于批容量)。
5.3.3 内存调优
调整内存的使用以及Spark应用程序的垃圾回收行为已经在Spark优化指南中详细介绍。强烈建议拜读一下。在这一部分,我们特别的讨论几个参数调整,在spark流应用程序上下文中。
spark流应用程序需求的内存严重依赖使用的转换类型。例如,如果你想使用窗口操作在十分钟的数据上,那么你的集群应该有足够内存可以保存10分钟的数据。或者如果你想使用updateStateByKey 在一个大量keys值数据集上,那么需要的内存将会很高。相反,如果你想做一个简单的map-filter-store操作,这需要内存很少。
通常,由于receiver接收到的数据以StorageLevel.MEMORY_AND_DISK_SER_2方式存储,不适合存储在内存的数据将写入硬盘中。这可能会降低流应用程序的性能,因此,建议流应用程序应该提供足够的内存。最好尝试和观察内存使用状况在小数据集上,然后评估。
内存调优的另一方面是垃圾回收。对一个要求低延迟的流应用程序,不愿被看到因为JVM垃圾回收引起大量中断
有一些参数可以帮助你调整内存使用和GC回收。
- Dstream持久化水平: 输入数据和RDDs默认被序列化为字节。这降低了内存使用和GC开销,和反序列持久化相比。使用Kryo序列化可以更大程度降低序列化大小和内存使用。更多的降低内存的使用可以使用压缩( spark.rdd.compress配置参数),以牺牲CPU时间为代价。
- 清理旧数据:默认情况下,所有输入数据和转换产生的持久化RDDs会被自动清理,spark流决定什么时候清楚数据基于转换被使用。例如,如果你正在用10分钟的窗口操作,spark streaming将会保留最后十分钟的数据,主动地扔掉旧数据。数据可以被保留更长的时间(例如,交互请求旧数据)通过设置streamingContext.remember。
- CMS垃圾收集器:使用并发的标记–清除GC被强烈建议使用,来保存GC相关的停顿一直比较低。尽管并发的GC减少了系统的整体吞吐量,它仍然被建议使用来获得更加稳定的批处理时间。确保你设置CMS GC在driver(在spark-submit下使用–driver-java-options)和executors(使用配置文件配置spark.executor.extraJavaOptions)上。
- 其他技巧: 为了更多的减少GC开销,下面技巧可以来尝试。
- 使用Tachyon,对堆外存储持久化RDDs。可以参考spark程序向导
- 使用更多的executors和更小的堆大小。这将会减少GC在每一个JVM堆的压力。
5.4 容错语义
在这一小节,我们将会讨论spark流应用程序在故障时间中的行为。
5.4.1 背景
为了理解spark流提供的语义,让我们记住spark RDDs的基本容错语义。
- 一个RDD是不变的、确定可重复计算的、分布式的数据集。每一个RDD记住确定操作的血统(lineage),血统被用在一个容错的输入数据集上,可以重建数据集。
- 如果RDD的任何一个分区由于节点故障而丢失,这个分区可以被重新计算使用操作的血统(lineage)从原始容错数据集。
- 假设所有的RDD转换操作是确定的,在最后转换RDDs的数据始终是相同的,与spark集群上的故障无关。
spark操作数据容错文件系统像HDFS或者S3。因此,任何从容错数据产生的RDDs也是容错的。然而,这不是Spark流的实例,因为最多情况下流数据是通过网络(除非filestream被使用)得到的。为了得到相同的容错属性对所有产生的RDDs,接收到的数据会在集群worker节点上的多个executors进行复制(默认复制因子是2)。这导致了系统中的两种数据需要被恢复从故障时间中:
- Data received and replicated:单worker节点故障,数据会保存下来,因为数据的一个副本存在于另外一个节点上。
- Data received but buffered for replication:由于数据没有副本,仅有的恢复数据的方法是从源中重新获取数据。
除此之外,有两种故障我们应该关注:
- worker节点故障:任何运行executors的worker节点可能发生故障,在这些节点内存的数据都会丢失,如果receivers运行在故障节点,它们的缓存数据会丢失。
- driver节点故障:如果driver节点运行spark流应用程序故障,显然地,sparkcontext会丢失,所有的executors和它们内存中的数据会丢失。
通过这些基本的知识,让我们理解spark流的容错语义。
5.4.2 定义
流系统的语义经常被定义依据每个记录被处理多少次。有三种类型的保证,一个系统可以提供所有可能的操作条件(尽管失败)。
- At most once:每个记录或者被处理一次或者一次都不处理。
- At least once:每个记录处理一次或者多次。这是强健的比at most once因它确保没有数据为丢失。而且可能会重复。
- Exactly once:每一个记录确保处理一次,没有数据会丢失,没有数据被处理多次。这是三个中最强健的保证。
5.4.3 基本语义
在任何流处理系统,一般来说,有三步处理数据。
- Receiving the data:数据接收从源使用receivers或者其他
- Transforming the data:接收的数据被转换使用Dstream或者RDD转换
- Pushing out the data:最终的转换数据被推出到外部系统像文件系统、数据库、仪表盘,等等。
如果一个流应用程序必须实现端到端的exactly-once保证,那么每一步必须提供exactly-once保证。这就是说,每一个记录必须被接收正好一次,同时推送到下游系统正好一次。让我们理解spark流上下文中这些步骤的语义。
- Receiving the data:不同的输入源提供不同的保证。这在下一小部分将会讨论。
- Transforming the data:所有接收的数据将会处理仅仅一次,由于RDD提供的担保。即使有故障发生,只要接收到的输入数据可以访问,最后的转换RDDs总是有相同的内容。
- Pushing out the data:输出操作默认确保最少一次语义,因为这依赖于输出操作类型(幂等与否)和下游系统(支持事务与否)的语义。但是用户可以实现自己的事务机制来实现 exactly-once 语义。这在之后部分进行详细讨论。
5.4.4 接收数据语义
不同数据源提供不同的保证,从至少一次到正好一次。
基于文件
如果所有的输入数据已经存在容错文件系统像HDFS,spark流总是能恢复从任何故障,并处理所有数据。这给 exactly-once 语义,所有的数据将会被处理正好一次无论什么故障。
基于receiver的源
对基于receivers的输入源,容错语义依赖于故障场景和receiver类型。像我们之前讨论的,有两种类型的receivers:
- Reliable Receiver:这些receivers应答可靠源,仅仅在确认接受的数据被复制之后。如果这样一个receiver发送故障,缓存的数据不会对数据源应答确认。如果receiver重启,数据源将会重新发送数据,因此没有数据因为故障丢失。
- Unreliable Receiver : receivers可能丢失数据由于worker或者driver故障引起的失败。
依赖于使用什么类型的receivers,我们可以获得下面的语义。如果一个worker节点失败,reliable receivers没有数据丢失。使用unreliable receivers,接收但是没有被复制的数据可能丢失。如果driver节点故障,除了上面介绍的数据丢失之外,所有过去接收和复制到内存中的数据也会丢失。这将会影响有状态转换的结果。
为了避免过去接收数据的丢失,spark1.2 引进了预写日志,那保存接收到的数据到容错存储。使用write ahead logs enabled 和 reliable receivers,可以保证零数据丢失。根据这些语义,它至少提供了至少一次的保证。
下面的表总结了故障状况下的语义:
| Deployment Scenario | Worker Failure | Driver Failure |
| Spark 1.1 or earlier, OR Spark 1.2 or later without write ahead logs | Buffered data lost with unreliable receivers Zero data loss with reliable receivers At-least once semantics | Buffered data lost with unreliable receivers Past data lost with all receivers Undefined semantics |
| Spark 1.2 or later with write ahead logs | Zero data loss with reliable receivers At-least once semantics | Zero data loss with reliable receivers and files At-least once semantics |
5.4.5 使用kafka direct api
在spark1.3,我们引进了一个新的kafka direct api,这能确保kafka数据能被spark流恰好一次。根据这,如果你实现exactly-once 输出操作,你能获得端到端到的exactly-once保证。这个方法(spark1.3 试验)更多的讨论在kafka集成向导。
5.4.6 输出操作语义
输出操作(像foreachRDD)有at-least once 语义,这就是说,在worker节点故障时,转换数据可能写到外部实体超过一次。然而使用saveAs***Files操作(文件简单的被重写使用相同的数据)保存到文件系统是可以接受的,为了获得 exactly-once 语义需要其它的一些额外努力。有两种方法。
- Idempotent updates:多次尝试总是写相同的数据。例如,saveAs***Files总是写相同的数据来产生文件。
- Transactional updates:所有的更新是事务性的,以便updates被制作成原子性的exactly once。做这的一种方法如下所示:
- 使用批时间(在foreachRDD中获得)和转换RDD的分区索引创建一个表示符。这个标识符独一无二的标识流应用程序的一个数据块。
- 使用这个标识符,事务性( exactly once, atomically)的更新带有blob的外部系统,更新外部系统。这就是说,如果标识符还没有被提交,原子性地提交分区数据和标识符。或者如果这已经被提交,跳过这个更新。