【干货】mmdetection使用coco格式的CrowdHuman数据集进行训练及测试(附调参过程)
注:从mmdetection使用coco数据集在faster rcnn训练和测试,到了解crowdhuman数据集标注格式,再到crowdhuman的标注格式转换成coco数据集标注格式,现在就到了最终目的了:训练转换后的Crowd Human数据集。
以下是博主这一过程中整理的记录:
- 【干货】用mmdetection,在COCO数据集上跑通faster R-CNN(测试、训练)
- COCO数据集标注格式详解----object instances
- CrowdHuman数据集格式 ——odgt文件格式
- 【干货】CrowdHuman数据集标注格式odgt转COCO数据集标注格式json(附详细代码)
参考博客:
- mmdetection使用自定义的coco格式数据集进行训练及测试
- mmdetection的configs中的各项参数具体解释
- CrowdHuman: A Benchmark for Detecting Human in a Crowd
训练CrowdHuman数据集是实验室师兄安排给我的任务,因为刚接触目标检测,所以,片面的以为,训练CrowdHuman数据集(已经转换成coco标注格式),就是跟参考博客中的第一篇博客一样,简单设置一下,直接训练。训练的模型真真惨不忍睹。
看一下我的数据集格式:
crowdhuman数据集放在mmdetection文件夹下的data里。

odgt文件是crowdhuman数据集的原标注文件,两个json文件是本次要用的标注文件,是将crowdhuman数据集的odgt文件转换成coco数据标注格式后的json文件。转换过程记录和代码可看上面的第四篇博客。

错误的CrowdHuman训练记录:
这次记录是完全参考第一篇博客的训练过程。当然博主并不是说这篇博客写得有误。错误是针对于CrowdHuman这个数据集而言的。
错误的原因是:博主相当于将crowdhuman的数据集当成了普通数据集处理了,使得训练后验证的量化结果,跟论文所给的实验结论数据相差甚大。
正确的是应该参考论文中的实验细节,根据它的要求,来进行调整参数。
这是我的test的结果,可以看得出来,AP值很低(AP 应该是IoU=0.5那行)。
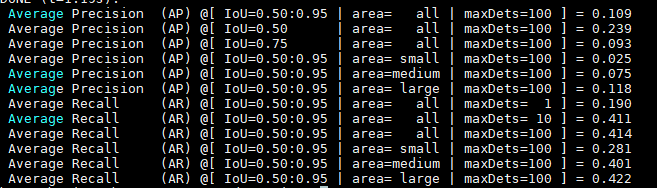
这是论文中给的实验数据。

这是训练的模型进行测试一张图片的结果,效果也是极差。(测试代码 这篇博客里有)

对比一下coco数据集训练的模型,跑上面图片的结果:

上面训练的模型,博主只改动了以下几处:
首先说明的是我的数据集类别一共只有2个,分别是:‘person’, ‘mask’, 。且我跑的模型是’configs/faster_rcnn_r50_fpn_1x.py’。
1.定义数据种类,需要修改的地方在mmdetection/mmdet/datasets/coco.py。把CLASSES的那个tuple改为自己数据集对应的种类tuple即可。例如:
CLASSES = ('person', 'mask')
2、接着在mmdetection/mmdet/core/evaluation/class_names.py修改coco_classes数据集类别,这个关系到后面test的时候结果图中显示的类别名称。例如:
def coco_classes():
return [
'person', 'mask'
]
3、修改configs/faster_rcnn_r50_fpn_1x.py中的model字典中的num_classes、data字典中的img_scale和optimizer中的lr(学习率)。例如:
num_classes=2,#类别数+1,虽然是两个类别,但其实只跑了person这一类而已
img_scale=(640,478), #输入图像尺寸的最大边与最小边(train、val三处都要修改)
optimizer = dict(type='SGD', lr=0.0025, momentum=0.9, weight_decay=0.0001) #当gpu数量为8时,lr=0.02;当gpu数量为4时,lr=0.01;我只要一个gpu,所以设置lr=0.0025
ok,以上就是修改的过程,据博主卑微的经验,这样的修改,应该是初级的,也就是说,适用于所有自定义的coco格式的数据集训练,具体的改进调优,则是在这基础之上再进行修改。
正确的CrowdHuman训练记录:
在Crowdhuman的论文中,实验的细节原文是这样说的:
We use the same setting of anchor scales as [15] and [16]. For all the experiments related to full body detection, we modify the height v.s. width ratios of anchors as {1 : 1,1.5 : 1,2 : 1,2.5 : 1,3 : 1} in consideration of the human body shape. While for visible body detection and human head detection, the ratios are set to {1 : 2,1 : 1,2 : 1}, in comparison with the original papers. The input image sizes of Caltech and CityPersons are set to 2× and 1× of the original images according to [31]. As the images of CrowdHuman and MSCOCO are both collected from the Internet with various sizes, we resize the input so that their short edge is at 800 pixels while the long edge should be no more than 1400 pixels at the same time. The input sizes of Brainwash is set as 640 × 480.
We train all datasets with 600k and 750k iterations for FPN and RetinaNet, respectively. The base learning rate is set to 0.02 and decreased by a factor of 10 after 150k and 450k for FPN, and 180k and 560k for RetinaNet. The Stochastic Gradient Descent (SGD) solver is adopted to optimize the networks on 8 GPUs. A mini-batch involves 2 images per GPU, except for CityPersons where a mini-batch involves only 1 image due to the physical limitation of GPU memory. Weight decay and momentum are set to 0.0001 and 0.9. We do not finetune the batch normalization [11] layers. Multi-scale training/testing are not applied to ensure fair comparisons.
中文翻译:
我们使用[15]和[16]中相同的锚尺度设置。对于所有与整体人体检测相关的试验,我们修正锚窗的高宽比为{1:1, 1.5:1, 2:1, 2.5:1, 3:1},以适应人体形状。而对于可见人体检测和头部检测,比例设置为{1:2, 1:1, 2:1}。根据[31],Caltech和CityPersons的输入图像尺寸设置为原图像的2倍和1倍。因为CrowdHuman和MSCOCO的图像都是从互联网上收集的,尺寸不一,我们改变图像尺寸,使其短边为800像素,同时长边不应超过1400像素。Brainwash的输入大小设置为640×480。
对于FPN和RetinaNet,我们训练所有的数据集迭代次数分别为60万次和75万次。基准学习速率为0.02,对于FPN,在15万次和45万次后除以10,对于RetinaNet在18万次和56万次后除以10。采用SGD在8GPU上优化网络。Mini-batch大小为每GPU 2幅图像,在CityPersons上是个例外,由于GPU内存的限制所以为每GPU 1幅图像。权值衰减和动量设置为0.0001和0.9。我们没有精调批归一化层[11]。公平起见,没有进行多尺度训练/测试。
针对论文所说的,我的configs/faster_rcnn_r50_fpn_1x.py文件内容如下(后文有具体的修改过解析):
# model settings
model = dict(
type='FasterRCNN', #model类型
pretrained='modelzoo://resnet50', #预训练模型
backbone=dict(
type='ResNet', #backbone类型
depth=50, #网络层数
num_stages=4, #resnet的stage数量
out_indices=(0, 1, 2, 3), #输出的stage序号
frozen_stages=1, # 冻结的stage数量,即该stage不更新参数,-1表示所有的stage都更新参数
style='pytorch'), # 网络风格:如果设置pytorch,则stride为2的层是conv3x3的卷积层;如果设置caffe,则stride为2的层是第一个conv1x1的卷积层
neck=dict(
type='FPN', # neck类型
in_channels=[256, 512, 1024, 2048],# 输入的各个stage的通道数
out_channels=256, # 输出的特征层的通道数
num_outs=5), # 输出的特征层的数量
rpn_head=dict(
type='RPNHead', # RPN网络类型
in_channels=256, # RPN网络的输入通道数
feat_channels=256, # 特征层的通道数
anchor_scales=[8], # 生成的anchor的baselen,baselen = sqrt(w*h),w和h为anchor的宽和高
anchor_ratios=[1.0, 1.5, 2.0,2.5,3.0], #anchor的宽高比,根据CrowdHuman论文修改锚窗比例
anchor_strides=[4, 8, 16, 32, 64], #在每个特征层上的anchor的步长(对应于原图)
target_means=[.0, .0, .0, .0], # 均值
target_stds=[1.0, 1.0, 1.0, 1.0], # 方差
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),
bbox_roi_extractor=dict(
type='SingleRoIExtractor', # RoIExtractor类型
roi_layer=dict(type='RoIAlign', out_size=7, sample_num=2),# ROI具体参数:ROI类型为ROIalign,输出尺寸为7,sample数为2
out_channels=256, # 输出通道数
featmap_strides=[4, 8, 16, 32]), # 特征图的步长
bbox_head=dict(
type='SharedFCBBoxHead', # 全连接层类型
num_fcs=2, #全连接层数量?
in_channels=256, # 输入通道数
fc_out_channels=1024, # 输出通道数
roi_feat_size=7, # ROI特征层尺寸
num_classes=2, #原来是81,81是coco数据集的类别数+1,现在2是crowdhuman的识别的类别数+1
target_means=[0., 0., 0., 0.], # 均值
target_stds=[0.1, 0.1, 0.2, 0.2], # 方差
reg_class_agnostic=False, # 是否采用class_agnostic的方式来预测,class_agnostic表示输出bbox时只考虑其是否为前景,后续分类的时候再根据该bbox在网络中的类别得分来分类,也就是说一个框可以对应多个类别
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)))
# model training and testing settings
train_cfg = dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner', # RPN网络的正负样本划分
pos_iou_thr=0.7, # 正样本的iou阈值
neg_iou_thr=0.3, # 负样本的iou阈值
min_pos_iou=0.3, # 正样本的iou最小值。如果assign给ground truth的anchors中最大的IOU低于0.3,则忽略所有的anchors,否则保留最大IOU的anchor
ignore_iof_thr=-1), # 忽略bbox的阈值,当ground truth中包含需要忽略的bbox时使用,-1表示不忽略
sampler=dict(
type='RandomSampler', # 正负样本提取器类型
num=256, # 需提取的正负样本数量
pos_fraction=0.5, # 正样本比例
neg_pos_ub=-1, # 最大负样本比例,大于该比例的负样本忽略,-1表示不忽略
add_gt_as_proposals=False), # 把ground truth加入proposal作为正样本
allowed_border=0, # 允许在bbox周围外扩一定的像素
pos_weight=-1, # 正样本权重,-1表示不改变原始的权重
debug=False), # debug模式
rpn_proposal=dict(
nms_across_levels=False,
nms_pre=2000,
nms_post=2000,
max_num=2000,
nms_thr=0.7,
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner', # RCNN网络正负样本划分
pos_iou_thr=0.5, # 正样本的iou阈值
neg_iou_thr=0.5, # 负样本的iou阈值
min_pos_iou=0.5, # 正样本的iou最小值。如果assign给ground truth的anchors中最大的IOU低于0.3,则忽略所有的anchors,否则保留最大IOU的anchor
ignore_iof_thr=-1), # 忽略bbox的阈值,当ground truth中包含需要忽略的bbox时使用,-1表示不忽略
sampler=dict(
type='RandomSampler', # 正负样本提取器类型
num=512, # 需提取的正负样本数量
pos_fraction=0.25, # 正样本比例
neg_pos_ub=-1, # 最大负样本比例,大于该比例的负样本忽略,-1表示不忽略
add_gt_as_proposals=True), # 把ground truth加入proposal作为正样本
pos_weight=-1, # 正样本权重,-1表示不改变原始的权重
debug=False)) # debug模式
test_cfg = dict(
rpn=dict( # 推断时的RPN参数
nms_across_levels=False, # 在所有的fpn层内做nms
nms_pre=1000, # 在nms之前保留的的得分最高的proposal数量
nms_post=1000, # 在nms之后保留的的得分最高的proposal数量
max_num=1000, # 在后处理完成之后保留的proposal数量
nms_thr=0.7, # nms阈值
min_bbox_size=0), # 最小bbox尺寸
rcnn=dict(
score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=100)
# max_per_img表示最终输出的det bbox数量
# soft-nms is also supported for rcnn testing
# e.g., nms=dict(type='soft_nms', iou_thr=0.5, min_score=0.05)
)
# dataset settings
dataset_type = 'CocoDataset' # 数据集类型
data_root = 'data/crowdhuman/' # 数据集根目录
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
# 输入图像初始化,减去均值mean并处以方差std,to_rgb表示将bgr转为rgb
data = dict(
imgs_per_gpu=2, # 每个gpu计算的图像数量
workers_per_gpu=2, # 每个gpu分配的线程数
train=dict(
type=dataset_type, # 数据集类型
ann_file=data_root + 'crowdhuman2coco_train.json',# 数据集annotation路径
img_prefix=data_root + 'Images/', # 数据集的图片路径
img_scale=(1400, 800), #改变图像尺寸,使其短边为800像素,同时长边不应超过1400像素
img_norm_cfg=img_norm_cfg, # 图像初始化参数
size_divisor=32, # 对图像进行resize时的最小单位,32表示所有的图像都会被resize成32的倍数
flip_ratio=0.5, # 图像的随机左右翻转的概率
with_mask=False, # 训练时附带mask
with_crowd=True, # 训练时附带difficult的样本
with_label=True), # 训练时附带label
val=dict(
type=dataset_type,
ann_file=data_root + 'crowdhuman2coco_val.json',
img_prefix=data_root + 'Images/',
img_scale=(1400, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0,
with_mask=False,
with_crowd=True,
with_label=True),
test=dict(
type=dataset_type,
ann_file=data_root + 'crowdhuman2coco_val.json',
img_prefix=data_root + 'Images/',
img_scale=(1400, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0,
with_mask=False,
with_label=False,
test_mode=True))
# optimizer
optimizer = dict(type='SGD', lr=0.0025, momentum=0.9, weight_decay=0.0001)
# 优化参数,lr为学习率,momentum为动量因子,weight_decay为权重衰减因子
#当gpu数量为8时,lr=0.02;当gpu数量为4时,lr=0.01;我只要一个gpu,所以设置lr=0.0025,修改前是0.02
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))# 梯度均衡参数
# learning policy
lr_config = dict( # 基准学习速率为0.02,对于FPN,在15万次和45万次后除以10
policy='step', # 优化策略
warmup='linear', # 初始的学习率增加的策略,linear为线性增加
warmup_iters=500, # 在初始的500次迭代中学习率逐渐增加
warmup_ratio=1.0 / 3, # 起始的学习率
step=[20, 60]) # 在第20和60个epoch时降低学习率
checkpoint_config = dict(interval=8)
#间隔8epoch,存储一次模型
# yapf:disable
log_config = dict(
interval=50, # 每50个batch输出一次信息
hooks=[
dict(type='TextLoggerHook'), # 控制台输出信息的风格
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
# runtime settings
total_epochs = 80 # 最大epoch数。60万/7500次,7500 = 15000/2
dist_params = dict(backend='nccl') # 分布式参数
log_level = 'INFO' # 输出信息的完整度级别
work_dir = './work_dirs/faster_rcnn_r50_fpn_1x'# log文件和模型文件存储路径
load_from = None # 加载模型的路径,None表示从预训练模型加载
resume_from = None # 恢复训练模型的路径
workflow = [('train', 1)] # 当前工作区名称
根据论文修改的几个参数:
- anchor_ratios=[1.0, 1.5, 2.0,2.5,3.0],这是论文中要求的宽高比,以适应人体形状
- num_classes=2,本数据集中只有两个类别,但其实只识别一个,即person,所以就1+1 = 2
- data_root = ‘data/crowdhuman/’ 根据自己的数据路径修改,没得说,但是dataset_type = 'CocoDataset’这个不能改,我们训练的数据集格式还是coco的。
- ann_file=data_root + ‘crowdhuman2coco_train.json’ ,json标注文件的路径,这是博主转换后的新json文件 (train、val三个地方都要修改)
- img_prefix=data_root + ‘Images/’, 数据集的图片路径(train、val三个地方都要修改)
- img_scale=(1400, 800), 这是论文中要求的大小(train、val三个地方都要修改)
- optimizer 字典中的 lr=0.0025,因为博主用一个GPU跑。8个GPU对应的
lr是0.02,几个GPU就自己算一下咯。 - step=[20, 60]) # 在第20和60个epoch时降低学习率
这20和60怎么计算来的呢?
我们的数据集(CrowdHuman)训练图片是15000张,每次imgs_per_gpu=2 ,也就是7500次的迭代,一个epoch对应的是7500次迭代,对于FPN,在15万次和45万次处降低学习率,所以就是15万/7500 = 20;45万/7500 = 60。 - checkpoint_config = dict(interval=8) 这个看自己设定了,我是8个epoch存储一个模型
- total_epochs = 80
上面所说,一次epoch是7500次迭代,论文中要求,对于FPN来说,所有的数据集迭代次数分别为60万次,也就是60万/7500 = 80epoch,总共是80个epoch,
以上就是关于configs/faster_rcnn_r50_fpn_1x.py文件几处修改。
相应的,还要修改以下两处文件(具体的修改参考上面的错误的训练记录)
- 定义数据种类,需要修改的地方在mmdetection/mmdet/datasets/coco.py
- 接着在mmdetection/mmdet/core/evaluation/class_names.py修改coco_classes数据集类别,这个关系到后面test的时候结果图中显示的类别名称。
到此,训练这个模型之前的相关参数已经修改完毕,博主也是刚学习不久,可能有些地方理解不够深或者误解的,难免有错误的地方,还请告知,相互学习。
输入以下命令,训练:
python tools/train.py configs/faster_rcnn_r50_fpn_1x.py
测试:
python tools/test.py configs/faster_rcnn_r50_fpn_1x.py work_dirs/epoch_80.pth --out ./result/result_100.pkl --eval bbox
本次的训练的结果还没出来,80个epoch,60万迭代,估计要两天,这次的训练结果,博主自己估计,肯定会比第一次训练出来的结果要好吧。