自然语言处理(NLP):08 PyTorch深度学习之TextCNN短文本分类
本章节主要研究内容:基于PyTorch 深度学习工具来完成短文本分类
知识点
- 业务需求
- 文本分类应用场景、技术方案以及挑战
- 技术架构
- 文本分析
- 词向量
- CNN 原理
- tensorboardX 可视化
- 项目实战: 基于TextCNN短文本分类,主要从数据预处理、构建此表、Embedding、模型训练、tensorboardX可视化以及在线服务几个重要的环境进行学习
文本分类应用场景
文章分类服务对文章内容进行深度分析,输出文章的主题一级分类、主题二级分类及对应的置信度,该技术在个性化推荐、文章聚合、文本内容分析等场景具有广泛的应用价值.
- 新闻分类
根据文本描述的内容方向,针对新闻媒体的文章做自动分类,例如军事类、农业类、体育类、娱乐类等多种类别方向
- 文本审核
定制训练文本审核的分类模型,如判断文本中是否有交易、涉黄涉赌小广告等违规描述类型的内容
- 电商评论分类
电商业务可根据用户对商品的评价内容维度,做物流类、服务类、产品类等问题描述方向的自动分类
- 舆情监控
通过对需要舆情监控的实时文字数据流进行情感倾向性分析,把握用户对热点信息的情感倾向性变化
下面时在整个新闻个性化推荐领域 文本分类的数据内容
那么,我们接下来就一个真实的案例给大家介绍如何通过深度学习来对新闻文本进行分类
文本分类技术方案以及挑战
文本分类作为文本理解的基本任务、能够服务于大量应用(如文本摘要、情感分析、推荐系统等等),更是长期以来学术界与工业界关注的焦点.
(1)文本分类处理方案:
采取人设定特征(词袋、词性标注、树核等)或者ML/DNN对文本进行表达(朴素贝叶斯 、SVM)。
(2)具体来说分为以下几种:
- 词嵌入向量化:Word2vec、FastText等;
- 卷积神经网络特征提取:Test-CNN、Char-CNN等;
- 上下文机制:Text-RNN、BiRNN、RCNN等;
- 记忆存储机制:EntNet、DMN等;
- 注意力机制:HAN等
(3)短文本处理难点
短文本由于内容简短,易于阅读和传播,被民众广泛使用,在新闻标题、社交媒体信息和短信中随处可见,但是内容简短、缺失会引起数据稀疏,与段落或者文章不同,短文本并不总能观察出句法,且短文本存在的多义和错误往往使内容不清楚,难以理解语义,导致模型分类没有足够特征进行类别判断,分类任务困难
import numpy as np
import pandas as pd
import torch
import jieba
print('numpy.version = ',np.__version__)
print('pandas.version = ',pd.__version__)
print('torch.version = ',torch.__version__)
print('jieba.version = ',jieba.__version__)
numpy.version = 1.16.2
pandas.version = 0.23.4
torch.version = 1.0.1.post2
jieba.version = 0.39
技术方案选型
运行环境准备
-
GPU显存:16G(GPU环境下训练深度学习模型非常快)/CPU环境:12G (训练模型慢)
-
Python版本:3.7
-
依赖库:
numpy 1.13.3
jieba 0.39
torch 1.x
pandas 0.23x
tqdm
sklearn
分类器选择
对于多分类问题,可以使用softmax函数作为分类器,最小化交叉熵(Cross Entropy)
-
传统机器学习文本分类算法
-
深度学习文本分类算法
特征提取
基于深度学习方法 (基于word2vec):
- 将所有词(或词频>阈值的词)组成一个词表,得到word2index字典和index2word字典;
- 将词映射为index,并且进行padding,然后通过词对应的index对词向量矩阵进行Lookup,得到当前文本对应的word2vec;
- 使用FastText、CNN、等模型在word2vec的基础上进行特征提取。
深度学习工具
这里基于PyTorch深度学习工具,TextCNN 模型训练
模型在线预测
对于大型项目在线服务功能,我们需要使用JAVA或者C++、Go 进行Web 服务部署,对于我们中小型项目我们采用Flask Web 框架进行部署
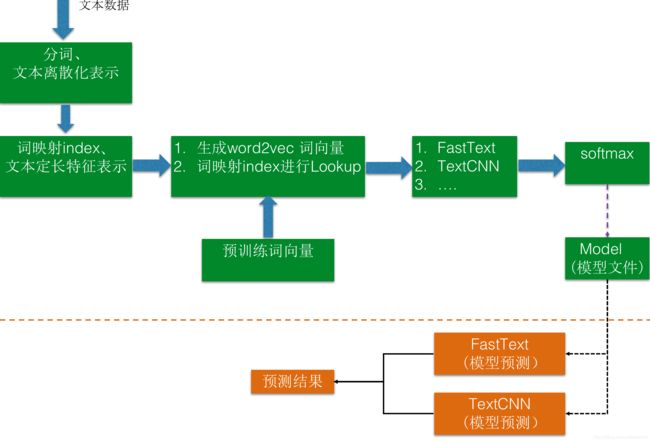
处理流程
- 原始文本数据分析以及可视化图表展示
- 文本预处理:分词、数据离散化表示
- 构建词表:构建
- Embedding : 根据词index 获取词向量、随机或者预训练词向量初始化单词的Embedding 向量
- 模型训练:CNN、效果评估
- 分类器:softmax 获取文本对应类别最大概率
- 在线服务部署-多模型投票
多模型融合: 预测时,将多个模型的预测值的均值作为最终的预测结果
在线服务预测
http://127.0.0.1:5000/v1/p?q=昆明拟规定乘地铁禁止手机外放声音
文本数据分析
- 词云展示
- 关键词提取
- 中文文本分类方法
词向量介绍
引入外部向量
训练自己业务向量
CNN 文本分类原理
《Convolutional Neural Networks for Sentence Classification》
CNN 论文模型
CNN 论文优化以及实验
TextCNN 架构以及工作机制
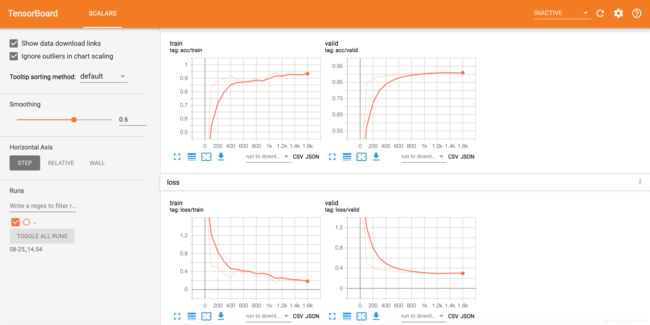
tensorboardX 分类效果
- TextCNN
$tensorboard --logdir 08-25_14.54
项目实战
文本分类项目主要 基于深度学习来完成。这里采用CNN完成短文本的分类,采用PyTorch 深度学习工具。
$ tree -L 2
.
├── api.py
├── config_file
├── data
│ ├── ckpts
│ ├── data
│ ├── log
├── data_processing.py
├── dataset.py
├── docs
├── images
├── main.py
├── models
│ ├── TextCNN.py
├── notebook
├── static
│ ├── css
│ ├── img
│ └── js
├── templates
│ └── index.htm
└── utils.py
- data 训练数据、模型存储以及日志记录、词向量
- data_processing.py 数据预处理
- notebook 技术方案、数据分析jupyter-notebook 文件以及词向量生成
- dataset.py 自定义PyTorch数据集类
- docs 深度学习文本分类论文以及课件
- notebook 数据分析
- config_file 训练参数文件
- models 定义模型文件,例如:TextCNN,RCNN 等
- main.py 程序入口
- api.py static,templates 在线服务程序
预处理
构建词表
Embedding
模型训练
### tensorboardX 可视化
### 在线服务