前言
之前我们介绍了交换类排序中的冒泡排序,这次我们介绍另一种交换类排序叫做快速排序。快速排序的优点是原地排序,不占用额外空间,时间复杂度是O(nlogn)。
当然,对于快速排序来说,它也是有缺点的,它对于含有大量重复元素的数组排序效率是非常低的,时间复杂度会降为O(n^2)。此时需要使用改进的快速排序—双路快速排序,在双路快速排序的基础上,我们又进一步优化得到了三路快速排序。
快速排序
快速排序的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快速排序的步骤如下:
- 把第一个元素作为分界的标定点,用
l指向它。
- 遍历右边元素,在遍历的过程中,我们整理数组,一部分小于
v,一部分大于v,用j指向小于v和大于v的分界点,用i指向当前访问的元素e,此时,数组arr[l+1...j]arr[j+1...i-1]>v。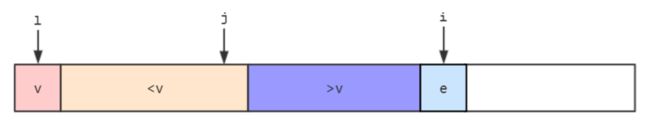
- 若
e>v,那么直接将e合并在大于v那么部分的后面,然后i++继续比较后面的元素。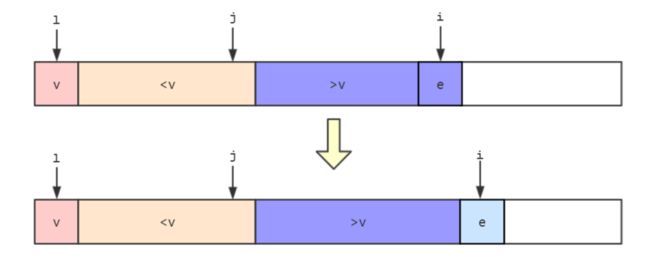
- 若
ee移动到j所指向元素的后一个元素,接着j++,然后i++继续比较后面的元素。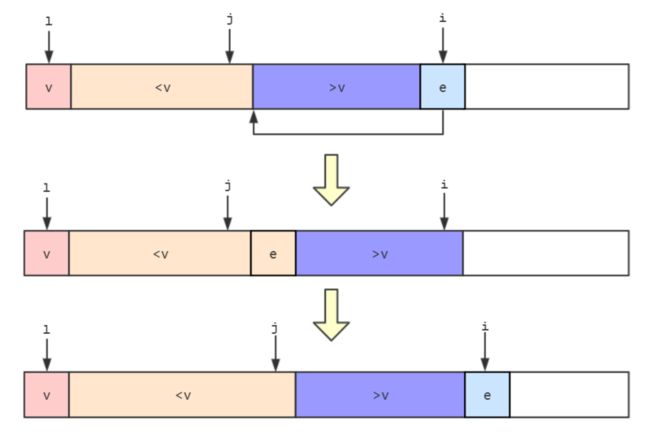
- 使用这种方式对整个数组进行一次遍历,遍历完后数组被分成三部分,左边部分是
v,中间部分是>v,右边部分是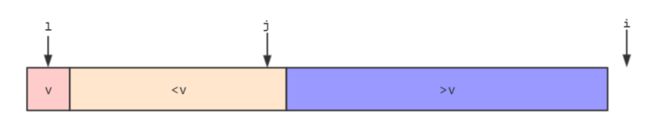
- 最后,我们让
l指向的元素和j指向的元素交换,这样就v这个元素进行了快速排序,v左边元素都小于v,右边元素都大于v。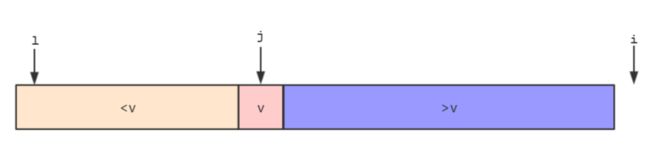
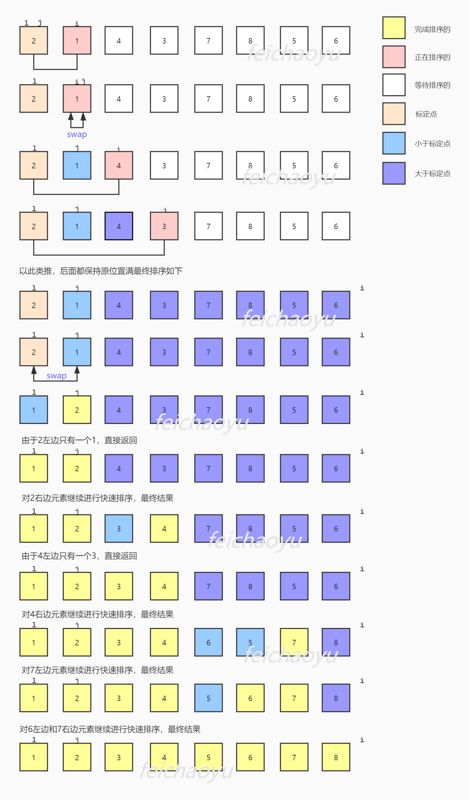
现在我们使用上述方法对数组[2, 1, 4, 3, 7, 8, 5, 6]进行快速排序,下图展示了整个快速排序的过程:
快速排序代码:
public static void sort(Comparable[] arr) {
int n = arr.length;
sort(arr, 0, n - 1);
}
// 递归使用快速排序,对arr[l...r]的范围进行排序
private static void sort(Comparable[] arr, int l, int r) {
if (l >= r) {
return;
}
// 对arr[l...r]部分进行partition操作, 返回p, 使得arr[l...p-1] < arr[p] ; arr[p+1...r] > arr[p]
int p = partition(arr, l, r);
sort(arr, l, p - 1);
sort(arr, p + 1, r);
}
private static int partition(Comparable[] arr, int l, int r) {
// 最左元素作为标定点
Comparable v = arr[l];
int j = l;
for (int i = l + 1; i <= r; i++) {
if (arr[i].compareTo(v) < 0) {
swap(arr, j + 1, i);
j++;
}
}
swap(arr, l, j);
return j;
}优化的快速排序
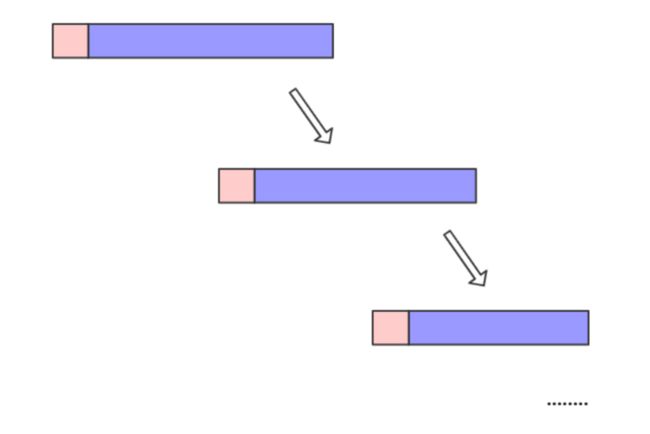
经过上述介绍,我们可以发现快速排序不能保证每次切分的子数组大小相等,因此就可能一边很小,一边很大。对于一个有序数组,快速排序的时间复杂度就变成了O(n^2),相当于树退化成了链表,下图展示了这种变化:
上述我们是固定使用左边的第一个元素作为标定元素,现在我们随机挑选一个元素作为标定元素。此时我们第一次选中第一个元素的概率为 1/n,第二次又选中第二个元素 1/n-1,以此类推,发生之前退化成链表的概率为1/n(n-1)(n-2)....,当 n 很大时,这种概率几乎为 0。
另一个优化就是对小规模数组使用插入排序,因为递归会使得小规模问题中方法的调用过于频繁,而插入排序对小规模数组排序是非常快的。
优化的快速排序代码:
public static void sort(Comparable[] arr) {
int n = arr.length;
sort(arr, 0, n - 1);
}
// 递归使用快速排序,对arr[l...r]的范围进行排序
private static void sort(Comparable[] arr, int l, int r) {
// 对于小规模数组, 使用插入排序
if (r - l <= 15) {
InsertionSort.sort(arr, l, r);
return;
}
// 对arr[l...r]部分进行partition操作, 返回p, 使得arr[l...p-1] < arr[p] ; arr[p+1...r] > arr[p]
int p = partition(arr, l, r);
sort(arr, l, p - 1);
sort(arr, p + 1, r);
}
private static int partition(Comparable[] arr, int l, int r) {
// 随机在arr[l...r]的范围中, 选择一个数值作为标定点pivot
swap(arr, l, (int) (Math.random() * (r - l + 1)) + l);
Comparable v = arr[l];
int j = l;
for (int i = l + 1; i <= r; i++) {
if (arr[i].compareTo(v) < 0) {
swap(arr, j + 1, i);
j++;
}
}
swap(arr, l, j);
return j;
}双路快速排序
对于含有大量重复元素的数组,使用上述的快速排序效率是非常低的,因为在我们上面的判断中,如果元素小于v,则将元素放在v,则放在>v部分。此时,如果数组中有大量重复元素,>v部分会变得很长,导致左右两边不均衡,性能降低。
双路快速排序的步骤如下:
- 将
>v两部分放在数组的两端,用i指向j指向>v部分的前一个元素。
- 从
i开始向后遍历,如果遍历的元素ee>=v,则停止遍历。同样从j开始向前遍历,如果遍历的元素e>v,则继续向前遍历,直到遍历的元素e<=v,则停止遍历。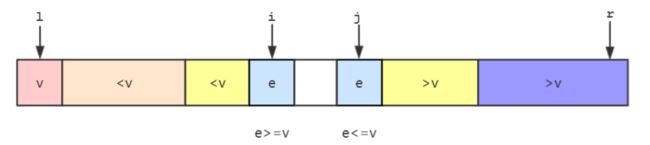
- 交换
i指向的元素和j指向的元素。然后i++,j--继续比较下一个。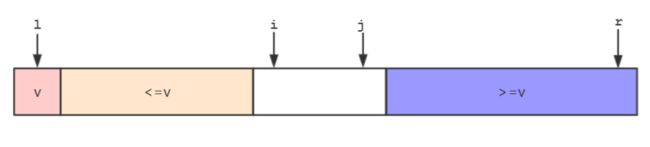
双路快速排序的代码:
public static void sort(Comparable[] arr) {
int n = arr.length;
sort(arr, 0, n - 1);
}
private static void sort(Comparable[] arr, int l, int r) {
// 对于小规模数组, 使用插入排序
if (r - l <= 15) {
InsertionSort.sort(arr, l, r);
return;
}
int p = partition(arr, l, r);
sort(arr, l, p - 1);
sort(arr, p + 1, r);
}
private static int partition(Comparable[] arr, int l, int r) {
// 随机在arr[l...r]的范围中, 选择一个数值作为标定点pivot
swap(arr, l, (int) (Math.random() * (r - l + 1)) + l);
Comparable v = arr[l];
int i = l + 1, j = r;
while (true) {
// 注意这里的边界, arr[i].compareTo(v) < 0, 不能是arr[i].compareTo(v) <= 0
// 不加等号如果遇到相等的情况,这时候while循环就会退出,即交换i和j的值,使得对于包含大量相同元素的数组, 双方相等的数据就会交换,这样就可以一定程度保证两路的数据量平衡
// 从i开始向后遍历,如果遍历的元素e=v,则停止遍历
while (i <= r && arr[i].compareTo(v) < 0) {
i++;
}
// 从j开始向前遍历,如果遍历的元素e>v,则继续向前遍历,直到遍历的元素e<=v,则停止遍历
while (j >= l + 1 && arr[j].compareTo(v) > 0) {
j--;
}
if (i >= j) {
break;
}
swap(arr, i, j);
i++;
j--;
}
// 此时j指向的元素是数组中最后一个小于v的元素, i指向的元素是数组中第一个大于v的元素
swap(arr, l, j);
return j;
} 三路快速排序
三路快速排序的步骤如下:
- 在双路快速排序的基础上,我们把等于
v的元素单独作为一个部分。lt指向小于v部分的最后一个元素,gt指向大于v部分的第一个元素。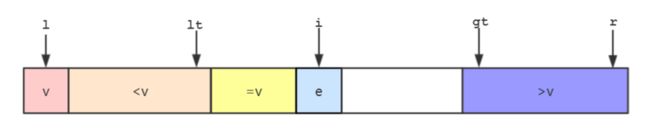
- 从
i开始向后遍历,如果遍历的元素e=v,则e直接合并到=v部分,然后i++继续遍历。如果遍历的元素ee和=v部分的第一个元素(lt+1指向的元素)交换,然后lt++,i++继续遍历。如果遍历的元素e>v,则将e和>v部分前一个元素(gt-1指向的元素)交换,然后gt--,不过此时i不需要改变,因为i位置的元素是和gt位置前面的空白元素交换过来的。 - 遍历完后
i=gt,然后将l指向元素和lt指向元素交换。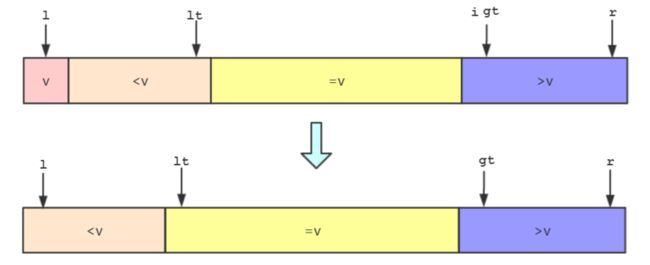
- 对
>v部分进行以上操作。
三路快速排序相比双路快速排序的优势在于:减少了对重复元素的比较操作,因为重复元素在一次排序中就已经作为单独一部分排好了,之后只需要对不等于该重复元素的其他元素进行排序。
三路快速排序代码:
public static void sort(Comparable[] arr) {
int n = arr.length;
sort(arr, 0, n - 1);
}
private static void sort(Comparable[] arr, int l, int r) {
// 对于小规模数组, 使用插入排序
if (r - l <= 15) {
InsertionSort.sort(arr, l, r);
return;
}
// 随机在arr[l...r]的范围中, 选择一个数值作为标定点pivot
swap(arr, l, (int) (Math.random() * (r - l + 1)) + l);
Comparable v = arr[l];
int lt = l; // arr[l+1...lt] < v
int gt = r + 1; // arr[gt...r] > v
int i = l + 1; // arr[lt+1...i) == v
while (i < gt) {
if (arr[i].compareTo(v) < 0) {
swap(arr, i, lt + 1);
i++;
lt++;
} else if (arr[i].compareTo(v) > 0) {
swap(arr, i, gt - 1);
gt--;
} else { // arr[i] == v
i++;
}
}
swap(arr, l, lt);
sort(arr, l, lt - 1);
sort(arr, gt, r);
}总结
本文介绍了快速排序、快速排序的优化、双路快速排序和三路快速排序。
对于快速排序,我们需要选择合适的标定点,使得标定点的两边平衡;在快速排序中递归到小数组时,我们可以使用插入排序替换递归,减少不必要的开销。
对于双路快速排序和三路快速排序,我们使用的场合是数组中存在大量重复元素。
最后,提示一下 JDK 底层的排序使用的就是插入排序 + 双路快速排序 + 归并排序的组合。
