Pytorch实战:使用 RNN 对姓名进行分类
原文链接
文章目录 [隐藏]
- 1 准备数据
- 2 将姓名转化为Tensors
- 3 构建神经网络
- 4 检验我们构建的RNN网络
- 5 具体思路:
- 6 准备训练RNN
- 7 训练RNN网络
- 8 绘制训练误差
- 9 手动检验训练的模型
- 10 思考Exercises
本文我们构建基于字母层级(粒度是字母而不是单词或者单个的字) 循环神经网络RNN 来姓名进行分类预测。
在每一次循环过程中,字母层级的RNN 会以字母列表方式输入 姓名(单词),神经网络会输出一个预测结果outpu 和 隐藏状态hidden_state,且 隐藏状态hidden_state会作为参数传入到下一个层网络中。我们将RNN最终的输出的结果作为预测结果(类别标签)。
具体的,我们从 18 种语言的成千上万个姓名数据中开始训练,并根据姓氏拼写来预测该姓名所属语言类别 。
pridict('Hinton') (-0.47) Scottish (-1.52) English (-3.57) Irish pridict('Schmidhuber') (-0.19) German (-2.48) Czech (-2.68) Dutch
| 1 2 3 4 5 6 7 8 9 |
pridict('Hinton') (-0.47) Scottish (-1.52) English (-3.57) Irish
pridict('Schmidhuber') (-0.19) German (-2.48) Czech (-2.68) Dutch |
准备数据
在 data文件夹 中有18 个txt文件,且都是以 某种语言名.txt 命名。 每个txt文件中含有很多姓氏名,每个姓氏名独占一行,有些语言使用的是 Unicode码(含有除了26英文字母以外的其他字符),我们需要将其统一成 ASCII码。
from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = 'all' import glob # *是通配符,匹配出data文件夹中的所有txt文件 all_filenames = glob.glob('data/*.txt') all_filenames
| 1 2 3 4 5 6 7 |
from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = 'all' import glob
# *是通配符,匹配出data文件夹中的所有txt文件 all_filenames = glob.glob('data/*.txt') all_filenames |
all_filenames结果
['data/Czech.txt', 'data/German.txt', 'data/Arabic.txt', 'data/Japanese.txt', 'data/Chinese.txt', 'data/Vietnamese.txt', 'data/Russian.txt', 'data/French.txt', 'data/Irish.txt', 'data/English.txt', 'data/Spanish.txt', 'data/Greek.txt', 'data/Italian.txt', 'data/Portuguese.txt', 'data/Scottish.txt', 'data/Dutch.txt', 'data/Korean.txt', 'data/Polish.txt']
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
['data/Czech.txt', 'data/German.txt', 'data/Arabic.txt', 'data/Japanese.txt', 'data/Chinese.txt', 'data/Vietnamese.txt', 'data/Russian.txt', 'data/French.txt', 'data/Irish.txt', 'data/English.txt', 'data/Spanish.txt', 'data/Greek.txt', 'data/Italian.txt', 'data/Portuguese.txt', 'data/Scottish.txt', 'data/Dutch.txt', 'data/Korean.txt', 'data/Polish.txt'] |
将将Unicode码转换成标准的ASCII码,直接谷歌找到的stackoverflow上的解决办法。
import unicodedata import string #姓氏中所有的字符 #string.ascii_letters是大小写各26字母 all_letters = string.ascii_letters + " .,;'" #字符的种类数 n_letters = len(all_letters) # 将Unicode码转换成标准的ASCII码 def unicode_to_ascii(s): return ''.join( c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn' and c in all_letters ) print(n_letters) #字符数为57个 print(unicode_to_ascii('Ślusàrski'))
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import unicodedata import string
#姓氏中所有的字符 #string.ascii_letters是大小写各26字母 all_letters = string.ascii_letters + " .,;'" #字符的种类数 n_letters = len(all_letters)
# 将Unicode码转换成标准的ASCII码 def unicode_to_ascii(s): return ''.join( c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn' and c in all_letters )
print(n_letters) #字符数为57个 print(unicode_to_ascii('Ślusàrski')) |
打印结果
57 'Slusarski'
| 1 2 |
57 'Slusarski' |
构建 语言类别-姓名映射字典,形如 {language1: [name1, name2, ...], language2: [name_x1, name_x2, ...]}
category_names = {} all_categories = [] #读取txt文件,返回ascii码的姓名 列表 def readNames(filename): names = open(filename).read().strip().split('\n') return [unicode_to_ascii(name) for name in names] for filename in all_filenames: category = filename.split('/')[-1].split('.')[0] all_categories.append(category) names = readNames(filename) category_names[category] = names #语言种类数 n_categories = len(all_categories) print('n_categories =', n_categories) n_categories = 18
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
category_names = {} all_categories = []
#读取txt文件,返回ascii码的姓名 列表 def readNames(filename): names = open(filename).read().strip().split('\n') return [unicode_to_ascii(name) for name in names]
for filename in all_filenames: category = filename.split('/')[-1].split('.')[0] all_categories.append(category) names = readNames(filename) category_names[category] = names
#语言种类数 n_categories = len(all_categories) print('n_categories =', n_categories) n_categories = 18 |
现在我们有 category_names 语言-姓名映射词典。
#查看Italian语言中前5个姓名 category_names['Italian'][:5]
| 1 2 |
#查看Italian语言中前5个姓名 category_names['Italian'][:5] |
显示前5个姓名
['Abandonato', 'Abatangelo', 'Abatantuono', 'Abate', 'Abategiovanni']
| 1 |
['Abandonato', 'Abatangelo', 'Abatantuono', 'Abate', 'Abategiovanni'] |
将姓名转化为Tensors
跟机器学习类似,在这里我们也需要将文本转化为具体的计算机能理解的数据形式。
为了表征单个的字符, 我们使用 独热编码向量one-hot vector, 该向量的尺寸为 1 x n_letters(每个字符是2维向量)
例如
a对应的是 [[1, 0, 0, 0, 0...]] b对应的是 [[0, 1, 0, 0, 0...]] c对应的是 [[0, 0, 1, 0, 0...]] ...
| 1 2 3 4 |
a对应的是 [[1, 0, 0, 0, 0...]] b对应的是 [[0, 1, 0, 0, 0...]] c对应的是 [[0, 0, 1, 0, 0...]] ... |
每个由多个字符(每个字符是2维)组成的姓名 转化为3维,尺寸为 name_length x 1 x n_letters
在pytorch中,所有输入的数据都假设是在batch中。所以才能看到尺寸 name_length x 1 x n_letters 中的 1。
import torch as t print(t.zeros(5)) #1维 print(t.zeros(1, 5)) #2维 print(t.zeros(3, 1, 5)) #3维
| 1 2 3 4 5 |
import torch as t
print(t.zeros(5)) #1维 print(t.zeros(1, 5)) #2维 print(t.zeros(3, 1, 5)) #3维 |
打印上面三行代码运行结果
tensor([0., 0., 0., 0., 0.]) tensor([[0., 0., 0., 0., 0.]]) tensor([[[0., 0., 0., 0., 0.]], [[0., 0., 0., 0., 0.]], [[0., 0., 0., 0., 0.]]])
| 1 2 3 4 5 6 7 8 9 |
tensor([0., 0., 0., 0., 0.])
tensor([[0., 0., 0., 0., 0.]])
tensor([[[0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0.]]]) |
定义letter_to_tensor函数
import torch # 将字符转化为 <1 x n_letters> 的Tensor def letter_to_tensor(letter): tensor = torch.zeros(1, n_letters) letter_index = all_letters.find(letter) tensor[0][letter_index] = 1 return tensor # 将姓名转化成尺寸为
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import torch
# 将字符转化为 <1 x n_letters> 的Tensor def letter_to_tensor(letter): tensor = torch.zeros(1, n_letters) letter_index = all_letters.find(letter) tensor[0][letter_index] = 1 return tensor
# 将姓名转化成尺寸为 # 使用的是one-hot编码方式转化 def name_to_tensor(name): tensor = torch.zeros(len(name), 1, n_letters) for ni, letter in enumerate(name): letter_index = all_letters.find(letter) tensor[ni][0][letter_index] = 1 return tensor |
现在我们运行letter_to_tensor(‘J’)
print(letter_to_tensor('J'))
| 1 |
print(letter_to_tensor('J')) |
显示上面代码运行结果
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]) name_to_tensor('Jones').size() print(name_to_tensor('Jones'))
| 1 2 3 4 5 6 |
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]) name_to_tensor('Jones').size() print(name_to_tensor('Jones')) |
显示上面代码运行结果
torch.Size([5, 1, 57]) tensor([[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]], [[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]], [[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]], [[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]], [[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]])
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
torch.Size([5, 1, 57])
tensor([[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]]) |
构建神经网络
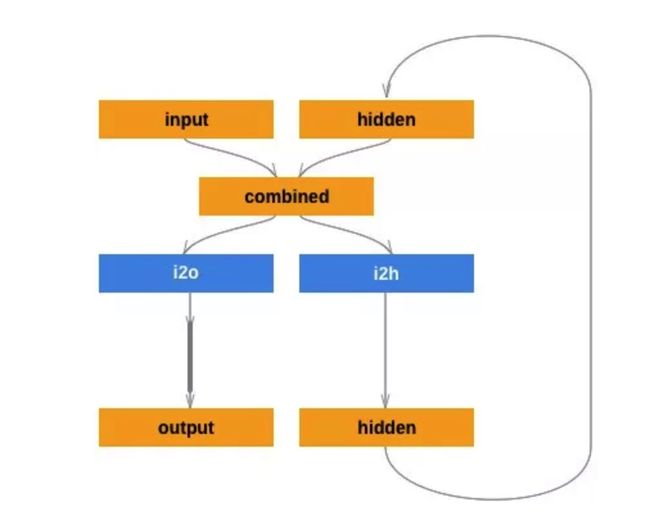
注意看图中各个参数解读:
input: 输入的数据hidden: 神经网络现有的参数矩阵combined: input矩阵与hidden矩阵合并,两个矩阵的行数一致,input和hidden分布位于新矩阵的 左侧和右侧i2o:对输入的数据转化为output的计算过程12h:将输入的数据转化为hidden参数的计算过程output:当前网络的输出hidden:当前网络传递给下层网络的参数
大家仔细看看琢磨琢磨这个图构造。现在我们先看看 combined 这个操作
a = t.Tensor(3,1) b = t.Tensor(3,2) print(a) #a print(b) #b print(t.cat((a,b), 1)) #a、b合并后的样子
| 1 2 3 4 5 6 |
a = t.Tensor(3,1) b = t.Tensor(3,2)
print(a) #a print(b) #b print(t.cat((a,b), 1)) #a、b合并后的样子 |
打印结果
tensor([[0.0000], [0.0000], [0.0000]]) tensor([[ 0.0000, 0.0000], [ 0.0000, -0.0000], [ 0.0000, 0.0000]]) tensor([[ 0.0000, 0.0000, 0.0000], [ 0.0000, 0.0000, -0.0000], [ 0.0000, 0.0000, 0.0000]])
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
tensor([[0.0000], [0.0000], [0.0000]])
tensor([[ 0.0000, 0.0000], [ 0.0000, -0.0000], [ 0.0000, 0.0000]])
tensor([[ 0.0000, 0.0000, 0.0000], [ 0.0000, 0.0000, -0.0000], [ 0.0000, 0.0000, 0.0000]]) |
开始DIY我们第一个循环神经网络RNN,各个参数解读:
input_size: 表征字母的向量的特征数量(向量长度)hidden_size: 隐藏层特征数量(列数)output_size: 语言数目,18i2h: 隐藏网络参数的计算过程。输入的数据尺寸为input_size + hidden_size, 输出的尺寸为hidden_sizei2o: 输出网络参数的计算过程。输入的数据尺寸为input_size + hidden_size, 输出的尺寸为output_size
import torch.nn as nn class RNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNN, self).__init__() self.input_size = input_size self.hidden_size = hidden_size self.output_size = output_size self.i2h = nn.Linear(input_size + hidden_size, hidden_size) self.i2o = nn.Linear(input_size + hidden_size, output_size) def forward(self, input, hidden): #将input和之前的网络中的隐藏层参数合并。 combined = torch.cat((input, hidden), 1) hidden = self.i2h(combined) #计算隐藏层参数 output = self.i2o(combined) #计算网络输出的结果 return output, hidden def init_hidden(self): #初始化隐藏层参数hidden return torch.zeros(1, self.hidden_size)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import torch.nn as nn
class RNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNN, self).__init__()
self.input_size = input_size self.hidden_size = hidden_size self.output_size = output_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size) self.i2o = nn.Linear(input_size + hidden_size, output_size)
def forward(self, input, hidden): #将input和之前的网络中的隐藏层参数合并。 combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined) #计算隐藏层参数 output = self.i2o(combined) #计算网络输出的结果 return output, hidden
def init_hidden(self): #初始化隐藏层参数hidden return torch.zeros(1, self.hidden_size) |
检验我们构建的RNN网络
定义好 RNN 类之后,我们可以创建RNN的实例
rnn = RNN(input_size=57, #输入每个字母向量的长度(57个字符) hidden_size=128, #隐藏层向量的长度,神经元个数。这里可自行调整参数大小 output_size=18) #语言的种类数目
| 1 2 3 |
rnn = RNN(input_size=57, #输入每个字母向量的长度(57个字符) hidden_size=128, #隐藏层向量的长度,神经元个数。这里可自行调整参数大小 output_size=18) #语言的种类数目 |
要运行此网络,我们需要给网络传入:
input(在我们的例子中,是当前字母的Tensor)hidden(我们首先将隐藏层参数初始化为零)
经过网络内部的运算,我们将得到:
output(每种语言的可能性的大小)next_hidden(传递给下一个网络的隐藏状态hidden)
input = letter_to_tensor('A') hidden = rnn.init_hidden() output, next_hidden = rnn(input, hidden) print('output.size =', output.size())
| 1 2 3 4 5 |
input = letter_to_tensor('A') hidden = rnn.init_hidden()
output, next_hidden = rnn(input, hidden) print('output.size =', output.size()) |
显示上面代码运行结果
output.size = torch.Size([1, 18])
| 1 |
output.size = torch.Size([1, 18]) |
现在我们使用 line_to_tensor 替换 letter_to_tensor 来构件输入的数据。注意在本例子中,给RNN网络一次输入一个姓名数据,但对该网络而言,是将姓名数据拆分成字母数组数据,逐次输入训练网络,直到这个姓名最后一个字母数组输入完成,才输出真正的预测结果(姓名所属的语言类别)。
输入 RNN神经网络 的数据的粒度变细,不再是 姓名数组数据(三维),而是组成姓名的字母的数组或矩阵(二维)。
input = name_to_tensor('Albert') hidden = torch.zeros(1, 128) #这里的128是hidden_size #给rnn传入的初始化hidden参数是尺寸为(1, 128)的zeros矩阵 #input[0]是传入姓名的第一个字符数组,注意这个数组是batch_size=1的矩阵。因为在pytorch中所有输入的数据都是batch方式输入的 output, next_hidden = rnn(input[0], hidden) print(output.shape) print(output)
| 1 2 3 4 5 6 7 8 |
input = name_to_tensor('Albert') hidden = torch.zeros(1, 128) #这里的128是hidden_size
#给rnn传入的初始化hidden参数是尺寸为(1, 128)的zeros矩阵 #input[0]是传入姓名的第一个字符数组,注意这个数组是batch_size=1的矩阵。因为在pytorch中所有输入的数据都是batch方式输入的 output, next_hidden = rnn(input[0], hidden) print(output.shape) print(output) |
显示上述结果
torch.Size([1, 18]) tensor([[-0.0785, 0.0147, 0.0940, -0.0518, -0.0286, 0.0175, -0.0641, -0.0449, -0.0013, 0.0421, 0.0153, 0.0269, -0.0556, 0.0304, -0.0133, -0.0572, 0.0217, 0.1066]], grad_fn=
| 1 2 3 4 |
torch.Size([1, 18]) tensor([[-0.0785, 0.0147, 0.0940, -0.0518, -0.0286, 0.0175, -0.0641, -0.0449, -0.0013, 0.0421, 0.0153, 0.0269, -0.0556, 0.0304, -0.0133, -0.0572, 0.0217, 0.1066]], grad_fn= |
现在我们看看output这个tensor中的含有数据,想办法从中提取出预测的 语言类别信息。
具体思路:
- 因为output是tensor,我们可以先获取这个tensor中的data
- 再使用基于data的topk方法,提取tensor中似然值最大的索引值。
该索引值就是 所属语言类别的索引值 ,具体我们可以看下面的例子更好的理解tensor的操作方法。
output.data output.data.topk(1)
| 1 2 |
output.data output.data.topk(1) |
显示上面两行代码运行结果
tensor([[-0.0785, 0.0147, 0.0940, -0.0518, -0.0286, 0.0175, -0.0641, -0.0449, -0.0013, 0.0421, 0.0153, 0.0269, -0.0556, 0.0304, -0.0133, -0.0572, 0.0217, 0.1066]]) (tensor([[0.1066]]), tensor([[17]]))
| 1 2 3 4 5 6 |
tensor([[-0.0785, 0.0147, 0.0940, -0.0518, -0.0286, 0.0175, -0.0641, -0.0449, -0.0013, 0.0421, 0.0153, 0.0269, -0.0556, 0.0304, -0.0133, -0.0572, 0.0217, 0.1066]])
(tensor([[0.1066]]), tensor([[17]])) |
上面的两行代码,
其中第一行代码得到tensor中的data
第二行代码得到某姓姓名(这里我们实际上只输入了一个字母,姑且当成只有一个字母的姓名)的 所属语言的似然值 及 所属语言类别的索引值
top_n, top_i = output.data.topk(1) top_n #所属语言的似然值,我们可以将其想象成概率 top_i #所属语言类别信息
| 1 2 3 |
top_n, top_i = output.data.topk(1) top_n #所属语言的似然值,我们可以将其想象成概率 top_i #所属语言类别信息 |
显示上面tpo_n和 top_i
tensor([[0.1066]]) tensor([[17]])
| 1 2 |
tensor([[0.1066]]) tensor([[17]]) |
接下来我们继续看
top_n, top_i = output.data.topk(1) top_i[0][0] #所属语言类别的索引值
| 1 2 |
top_n, top_i = output.data.topk(1) top_i[0][0] #所属语言类别的索引值 |
显示top_i[0][0]
tensor(17)
| 1 |
tensor(17) |
准备训练RNN
在训练前,我们把上面刚刚测试的求 所属语言类别的索引值 方法封装成函数 category_from_output。
该函数输入:
output: RNN网络输出的output
该函数输出:
语言类别语言类别索引值
def category_from_output(output): _, top_i = output.data.topk(1) category_i = top_i[0][0] return all_categories[category_i], category_i category_from_output(output)
| 1 2 3 4 5 6 7 |
def category_from_output(output): _, top_i = output.data.topk(1) category_i = top_i[0][0] return all_categories[category_i], category_i
category_from_output(output) |
显示category_from_output(output)运行结果
('Polish', tensor(17))
| 1 |
('Polish', tensor(17)) |
类比机器学习中需要将数据打乱,这里我们也要增入随机性(打乱)。
但不是将训练数据打乱,而是每次训练时随机的从数据集中抽取一种语言中的一个姓名。
这里我们定义了 random_training_pair 函数, 函数返回的是一个元组(category, name, category_tensor, name_tensor):
- category: 语言名
- name: 姓名
- category_tensor
- name_tensor
在定义函数前先看下面几个例子,更好的理解函数内部的运算过程。
category = random.choice(all_categories) category
| 1 2 |
category = random.choice(all_categories) category |
显示category
'Polish'
| 1 |
'Polish' |
上面的随机抽取了 一种语言, 接下来我们在 该语言 中抽取一个 姓名
name = random.choice(category_names[category]) name
| 1 2 |
name = random.choice(category_names[category]) name |
显示name
'Krol'
| 1 |
'Krol' |
训练过程中我们要有标签数据,在本文中 所属语言的索引值 作为 标签。
由于pytorch中训练过程中使用的都是tensor结构数据,其中的元素都是浮点型数值,所以这里我们使用LongTensor, 可以保证标签是整数。
另外要注意的是,pytorch中运算的数据都是batch。所以我们要将 所属语言的索引值 放入一个list中,再将该list传入torch.LongTensor()中.
category_tensor = torch.LongTensor([all_categories.index(category)]) category_tensor
| 1 2 |
category_tensor = torch.LongTensor([all_categories.index(category)]) category_tensor |
显示category_tensor
tensor([17])
| 1 |
tensor([17]) |
同理,name也要转化为tensor,这里我们调用name_to_tensor函数即可。
name_tensor = name_to_tensor(name) name_tensor
| 1 2 |
name_tensor = name_to_tensor(name) name_tensor |
显示name_tensor
tensor([[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]], [[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]], [[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]], [[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]])
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
tensor([[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]]) |
刚刚几个例子,相信大家已经明白了函数内部的实现方法,现在将其封装成 random_training_pair函数
import random def random_training_pair(): category = random.choice(all_categories) name = random.choice(category_names[category]) category_tensor = torch.LongTensor([all_categories.index(category)]) name_tensor = name_to_tensor(name) return category, name, category_tensor, name_tensor #我们从数据集中抽取十次 for i in range(10): category, name, category_tensor, name_tensor = random_training_pair() print('category =', category, '/ name =', name)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
import random
def random_training_pair(): category = random.choice(all_categories) name = random.choice(category_names[category]) category_tensor = torch.LongTensor([all_categories.index(category)]) name_tensor = name_to_tensor(name) return category, name, category_tensor, name_tensor
#我们从数据集中抽取十次 for i in range(10): category, name, category_tensor, name_tensor = random_training_pair() print('category =', category, '/ name =', name) |
上述代码块运行结果
category = Vietnamese / name = Truong category = Arabic / name = Malouf category = German / name = Messner category = Arabic / name = Boulos category = English / name = Batchelor category = Spanish / name = Guerrero category = Italian / name = Monti category = Scottish / name = Thomson category = Irish / name = Connell category = Korean / name = Youn
| 1 2 3 4 5 6 7 8 9 10 |
category = Vietnamese / name = Truong category = Arabic / name = Malouf category = German / name = Messner category = Arabic / name = Boulos category = English / name = Batchelor category = Spanish / name = Guerrero category = Italian / name = Monti category = Scottish / name = Thomson category = Irish / name = Connell category = Korean / name = Youn |
训练RNN网络
我们使用 nn.CrossEntropyLoss 作为评判标准,来检验 姓名真实所属的语言truth 与 预测该姓名得到预测所属语言类别predict 比对,计算RNN网络训练的误差。
criterion = nn.CrossEntropyLoss()
| 1 |
criterion = nn.CrossEntropyLoss() |
我们也创建了 优化器optimizer, 常用的优化器是SGD算法 。当 每次训练网络,我们比对结果, 好则改之, 无则加勉, 让该网络改善的学习率learning rate(改进的速度)设置为0.005 。
注意学习率learning rate不能设置的太大或者太小:
- 所谓欲速则不达,太大导致训练效果不佳。容易大条
- 太小了会导致训练速度太慢,遥遥无期。
learning_rate = 0.005 optimizer = torch.optim.SGD(rnn.parameters(), #给优化器传入rnn网络参数 lr=learning_rate) #学习率
| 1 2 3 |
learning_rate = 0.005 optimizer = torch.optim.SGD(rnn.parameters(), #给优化器传入rnn网络参数 lr=learning_rate) #学习率 |
每轮训练将:
- 创建input(name_tensor)和 input对应的语言类别标签(category_tensor)
- 当输入姓名第一个字母时,需要初始化隐藏层参数。
- 读取姓名中的
每个字母的数组信息,传入rnn,并将网络输出的hidden_state和下一个字母数组信息传入之后的RNN网络中 - 使用criterion比对 最终输出结果 与 姓名真实所属的语言标签 作比较
- 更新网络参数,改进网络。
- 循环往复以上几步
def train(category_tensor, name_tensor): rnn.zero_grad() #将rnn网络梯度清零 hidden = rnn.init_hidden() #只对姓名的第一字母构建起hidden参数 #对姓名的每一个字母逐次学习规律。每次循环的得到的hidden参数传入下次rnn网络中 for i in range(name_tensor.size()[0]): output, hidden = rnn(name_tensor[i], hidden) #比较最终输出结果与 该姓名真实所属语言,计算训练误差 loss = criterion(output, category_tensor) #将比较后的结果反向传播给整个网络 loss.backward() #调整网络参数。有则改之无则加勉 optimizer.step() #返回预测结果 和 训练误差 return output, loss.data[0]
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
def train(category_tensor, name_tensor): rnn.zero_grad() #将rnn网络梯度清零 hidden = rnn.init_hidden() #只对姓名的第一字母构建起hidden参数
#对姓名的每一个字母逐次学习规律。每次循环的得到的hidden参数传入下次rnn网络中 for i in range(name_tensor.size()[0]): output, hidden = rnn(name_tensor[i], hidden)
#比较最终输出结果与 该姓名真实所属语言,计算训练误差 loss = criterion(output, category_tensor)
#将比较后的结果反向传播给整个网络 loss.backward()
#调整网络参数。有则改之无则加勉 optimizer.step()
#返回预测结果 和 训练误差 return output, loss.data[0] |
现在我们可以使用一大堆姓名和语言数据来训练RNN网络,因为 train函数 会同时返回 预测结果 和 训练误差, 我们可以打印并可视化这些信息。
为了方便,我们每训练5000次(5000个姓名),就打印 一个姓名的预测结果,并 查看该姓名是否预测正确。
我们对每1000次的训练累计误差,最终将误差 可视化出来。
import time import math n_epochs = 100000 # 训练100000次(可重复的从数据集中抽取100000姓名) print_every = 5000 #每训练5000次,打印一次 plot_every = 1000 #每训练1000次,计算一次训练平均误差 current_loss = 0 #初始误差为0 all_losses = [] #记录平均误差 def time_since(since): #计算训练使用的时间 now = time.time() s = now - since m = math.floor(s / 60) s -= m * 60 return '%dm %ds' % (m, s) #训练开始时间点 start = time.time() for epoch in range(1, n_epochs + 1): # 随机的获取训练数据name和对应的language category, name, category_tensor, name_tensor = random_training_pair() output, loss = train(category_tensor, name_tensor) current_loss += loss #每训练5000次,预测一个姓名,并打印预测情况 if epoch % print_every == 0: guess, guess_i = category_from_output(output) correct = '✓' if guess == category else '✗ (%s)' % category print('%d %d%% (%s) %.4f %s / %s %s' % (epoch, epoch / n_epochs * 100, time_since(start), loss, name, guess, correct)) # 每训练5000次,计算一个训练平均误差,方便后面可视化误差曲线图 if epoch % plot_every == 0: all_losses.append(current_loss / plot_every) current_loss = 0
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import time import math
n_epochs = 100000 # 训练100000次(可重复的从数据集中抽取100000姓名) print_every = 5000 #每训练5000次,打印一次 plot_every = 1000 #每训练1000次,计算一次训练平均误差
current_loss = 0 #初始误差为0 all_losses = [] #记录平均误差
def time_since(since): #计算训练使用的时间 now = time.time() s = now - since m = math.floor(s / 60) s -= m * 60 return '%dm %ds' % (m, s)
#训练开始时间点 start = time.time()
for epoch in range(1, n_epochs + 1): # 随机的获取训练数据name和对应的language category, name, category_tensor, name_tensor = random_training_pair() output, loss = train(category_tensor, name_tensor) current_loss += loss
#每训练5000次,预测一个姓名,并打印预测情况 if epoch % print_every == 0: guess, guess_i = category_from_output(output) correct = '✓' if guess == category else '✗ (%s)' % category print('%d %d%% (%s) %.4f %s / %s %s' % (epoch, epoch / n_epochs * 100, time_since(start), loss, name, guess, correct))
# 每训练5000次,计算一个训练平均误差,方便后面可视化误差曲线图 if epoch % plot_every == 0: all_losses.append(current_loss / plot_every) current_loss = 0 |
上面代码块运行结果
5000 5% (0m 8s) 1.6642 San / Chinese ✗ (Korean) 10000 10% (0m 15s) 3.1045 Sobol / Arabic ✗ (Polish) 15000 15% (0m 23s) 2.9460 Hill / Vietnamese ✗ (Scottish) 20000 20% (0m 30s) 1.3255 Uemura / Japanese ✓ 25000 25% (0m 37s) 0.0889 Antonopoulos / Greek ✓ 30000 30% (0m 45s) 2.0578 Keighley / Russian ✗ (English) 35000 35% (0m 53s) 3.4646 Gaspar / Arabic ✗ (Spanish) 40000 40% (1m 1s) 2.6537 Soto / Japanese ✗ (Spanish) 45000 45% (1m 8s) 0.7883 Lykoshin / Russian ✓ 50000 50% (1m 17s) 3.1190 Blau / Vietnamese ✗ (German) 55000 55% (1m 26s) 1.4374 Sacco / Portuguese ✗ (Italian) 60000 60% (1m 33s) 0.0793 O'Boyle / Irish ✓ 65000 65% (1m 41s) 1.0468 Kong / Chinese ✓ 70000 70% (1m 47s) 0.6785 Davidson / Scottish ✓ 75000 75% (1m 55s) 3.3509 Serafin / Irish ✗ (Polish) 80000 80% (2m 2s) 0.1848 Portelli / Italian ✓ 85000 85% (2m 8s) 1.0430 Gabrisova / Czech ✓ 90000 90% (2m 15s) 1.3065 Loyola / Czech ✗ (Spanish) 95000 95% (2m 22s) 0.2379 Coelho / Portuguese ✓ 100000 100% (2m 29s) 0.3560 Teng / Chinese ✓
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
5000 5% (0m 8s) 1.6642 San / Chinese ✗ (Korean) 10000 10% (0m 15s) 3.1045 Sobol / Arabic ✗ (Polish) 15000 15% (0m 23s) 2.9460 Hill / Vietnamese ✗ (Scottish) 20000 20% (0m 30s) 1.3255 Uemura / Japanese ✓ 25000 25% (0m 37s) 0.0889 Antonopoulos / Greek ✓ 30000 30% (0m 45s) 2.0578 Keighley / Russian ✗ (English) 35000 35% (0m 53s) 3.4646 Gaspar / Arabic ✗ (Spanish) 40000 40% (1m 1s) 2.6537 Soto / Japanese ✗ (Spanish) 45000 45% (1m 8s) 0.7883 Lykoshin / Russian ✓ 50000 50% (1m 17s) 3.1190 Blau / Vietnamese ✗ (German) 55000 55% (1m 26s) 1.4374 Sacco / Portuguese ✗ (Italian) 60000 60% (1m 33s) 0.0793 O'Boyle / Irish ✓ 65000 65% (1m 41s) 1.0468 Kong / Chinese ✓ 70000 70% (1m 47s) 0.6785 Davidson / Scottish ✓ 75000 75% (1m 55s) 3.3509 Serafin / Irish ✗ (Polish) 80000 80% (2m 2s) 0.1848 Portelli / Italian ✓ 85000 85% (2m 8s) 1.0430 Gabrisova / Czech ✓ 90000 90% (2m 15s) 1.3065 Loyola / Czech ✗ (Spanish) 95000 95% (2m 22s) 0.2379 Coelho / Portuguese ✓ 100000 100% (2m 29s) 0.3560 Teng / Chinese ✓ |
绘制训练误差
import matplotlib.pyplot as plt %matplotlib inline plt.figure() plt.plot(all_losses)
| 1 2 3 4 5 6 |
import matplotlib.pyplot as plt %matplotlib inline
plt.figure() plt.plot(all_losses) |
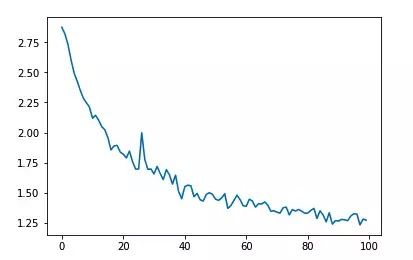
从误差图中可以看出,随着训练轮数的增加,模型的每1000次训练的平均误差越来越小。
手动检验训练的模型
为了方便,我们定义了 predict(rnn, input_name, n_predictions=3)函数
- rnn: 训练得到的rnn网络
- input_name: 姓名字符串
- n_predictions:该姓名预测结果的前n_predictions个预测结果
def predict(rnn, input_name, n_predictions=3): hidden = rnn.init_hidden() #name_tensor.size()[0] 名字的长度(字母的数目) for i in range(name_tensor.size()[0]): output, hidden = rnn(name_tensor[i], hidden) print('\n> %s' % input_name) # 得到该姓名预测结果中似然值中前n_predictions大的 似然值和所属语言 topv, topi = output.data.topk(n_predictions, 1, True) predictions = [] for i in range(n_predictions): value = topv[0][i] category_index = topi[0][i] print('(%.2f) %s' % (value, all_categories[category_index])) predictions.append([value, all_categories[category_index]]) predict(rnn, 'Dovesky') predict(rnn, 'Jackson') predict(rnn, 'Satoshi')
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
def predict(rnn, input_name, n_predictions=3): hidden = rnn.init_hidden()
#name_tensor.size()[0] 名字的长度(字母的数目) for i in range(name_tensor.size()[0]): output, hidden = rnn(name_tensor[i], hidden) print('\n> %s' % input_name)
# 得到该姓名预测结果中似然值中前n_predictions大的 似然值和所属语言 topv, topi = output.data.topk(n_predictions, 1, True) predictions = [] for i in range(n_predictions): value = topv[0][i] category_index = topi[0][i] print('(%.2f) %s' % (value, all_categories[category_index])) predictions.append([value, all_categories[category_index]])
predict(rnn, 'Dovesky') predict(rnn, 'Jackson') predict(rnn, 'Satoshi') |
上述代码块运行结果
> Dovesky (-0.87) Czech (-0.88) Russian (-2.44) Polish > Jackson (-0.74) Scottish (-2.03) English (-2.21) Polish > Satoshi (-0.77) Arabic (-1.35) Japanese (-1.81) Polish
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
> Dovesky (-0.87) Czech (-0.88) Russian (-2.44) Polish
> Jackson (-0.74) Scottish (-2.03) English (-2.21) Polish
> Satoshi (-0.77) Arabic (-1.35) Japanese (-1.81) Polish |