Pandas学习笔记4 变形——Datawhale组队学习
- pivot与pivot_table
一般状态下,数据在DataFrame会以压缩(stacked)状态存放,例如上面的Gender,两个类别被叠在一列中,pivot函数可将某一列作为新的cols。然而pivot函数具有很强的局限性,除了功能上较少之外,还不允许values中出现重复的行列索引对(pair)。
df.pivot(index='ID',columns='Gender',values='Height')
pivot_table功能更多,但速度比不上pivot函数。
pd.pivot_table(df,index='ID',columns='Gender',values='Height')
pivot_table常用参数:
aggfunc:对组内进行聚合统计,可传入各类函数,默认为’mean’
pd.pivot_table(df,index='School',columns='Gender',values='Height',aggfunc=['mean','sum'])
margins:汇总边际状态pd.pivot_table(df,index='School',columns='Gender',values='Height',aggfunc=['mean','sum'],margins=True)
行、列、值都可以为多级
pd.pivot_table(df,index=['School','Class'], columns=['Gender','Address'], values=['Height','Weight'])
- 交叉表,典型的用途如分组统计
pd.crosstab(index=df['Address'],columns=df['Gender'])
重要参数
values和aggfunc:分组对某些数据进行聚合操作,这两个参数必须成对出现pd.crosstab(index=df['Address'],columns=df['Gender'], values=np.random.randint(1,20,df.shape[0]),aggfunc='min')
normalize参数,可选’all’,‘index’,'columns’参数值pd.crosstab(index=df['Address'],columns=df['Gender'],normalize='all',margins=True)
- melt函数可以认为是pivot函数的逆操作,将unstacked状态的数据,压缩成stacked,使“宽”的DataFrame变“窄”
pivoted = df.pivot(index='ID',columns='Gender',values='Math')
result = pivoted.reset_index().melt(id_vars=['ID'],value_vars=['F','M'],value_name='Math')\
.dropna().set_index('ID').sort_index()
melt函数中的id_vars表示需要保留的列,value_vars表示需要stack的一组列
- stack总共只有两个参数:level和dropna。stack函数可以看做将横向的索引放到纵向,功能类似与melt,参数level可指定变化的列索引是哪一层。
df_stacked = df_s.stack()
df_stacked = df_s.stack(0)
- unstack:stack的逆函数,功能上类似于pivot_table
result = df_stacked.unstack().swaplevel(1,0,axis=1).sort_index(axis=1)
- get_dummies函数,功能主要是进行one-hot编码
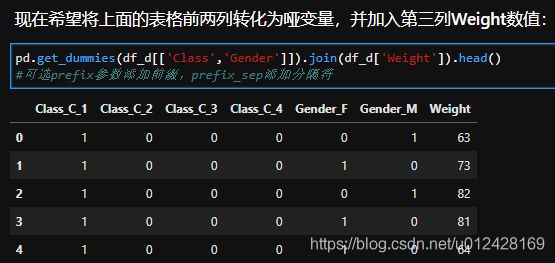
- factorize方法主要用于自然数编码,并且缺失值会被记做-1,其中sort参数表示是否排序后赋值
codes, uniques = pd.factorize(['b', None, 'a', 'c', 'b'], sort=True)
笔记出处:
joyful-pandas/第4章 变形.ipynb