paper:Attention Is All You Need(源码篇)
文章目录
- 1.整体结构
- 2.编码部分(Input)
- 2.1.input embedding
- 2.2.Positional encoding
- 2.3.Multi-head attention
- 2.4.Add&Norm
- 2.5.FeedForward
- 2.6.Add&Norm
- 2.7.编码Block Loop
- 3.解码
- 3.1.target sequence embedding
- 3.2.Positional embedding
- 3.3. self attention
- 3.4.Add&Norm
- 3.5.Multi-head attention
- 3.6.Add&norm
- 3.7.Feed-Forward
- 3.8. Add&norm
- 3.9 解码Block Loop
- 3.10.Linear&Softmax
- 4.模型Predict
继上篇 paper:Attention Is All You Need之后,我们针对official提供的源码进行解析。
本次源码分析针对的是tensorflow/models,同时还有一份带有详细注释的源码,在小博的github里面。(好久没整理这么详细的帖子了。。。)
本博主题思路参考:Attention Is All You Need(注意力模型),并在此基础上做了修改,并增加了相关源码解析~
更新:
这里还有一个很好的实现,之前我没有发现,在看了这个之后发现这个比官方的版本可读性要好多了,所以再深入了解一个模型的时候,如何查阅资料很关键,站在巨人的肩上会走的更快! 代码以及讲解博客:机器翻译模型Transformer代码详细解析
1.整体结构
Transformer的整体结构:
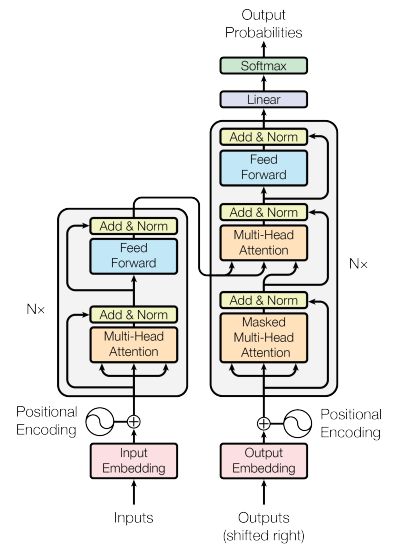
源码路径(代码1.0.1)Official/Transformer/model/transformer.py
class Transformer(object):
"""Transformer model for sequence to sequence data.
Implemented as described in: https://arxiv.org/pdf/1706.03762.pdf
The Transformer model consists of an encoder and decoder. The input is an int
sequence (or a batch of sequences). The encoder produces a continous
representation, and the decoder uses the encoder output to generate
probabilities for the output sequence.
"""
def __init__(self, params, train):
"""Initialize layers to build Transformer model.
Args:
params: hyperparameter object defining layer sizes, dropout values, etc.
train: boolean indicating whether the model is in training mode. Used to
determine if dropout layers should be added.
"""
self.train = train
self.params = params
self.embedding_softmax_layer = embedding_layer.EmbeddingSharedWeights(
params["vocab_size"], params["hidden_size"],
method="matmul" if params["tpu"] else "gather")
self.encoder_stack = EncoderStack(params, train)
self.decoder_stack = DecoderStack(params, train)
def __call__(self, inputs, targets=None):
"""Calculate target logits or inferred target sequences.
Args:
inputs: int tensor with shape [batch_size, input_length].
targets: None or int tensor with shape [batch_size, target_length].
Returns:
If targets is defined, then return logits for each word in the target
sequence. float tensor with shape [batch_size, target_length, vocab_size]
If target is none, then generate output sequence one token at a time.
returns a dictionary {
output: [batch_size, decoded length]
score: [batch_size, float]}
"""
# Variance scaling is used here because it seems to work in many problems.
# Other reasonable initializers may also work just as well.
initializer = tf.variance_scaling_initializer(
self.params["initializer_gain"], mode="fan_avg", distribution="uniform")
with tf.variable_scope("Transformer", initializer=initializer):
# Calculate attention bias for encoder self-attention and decoder
# multi-headed attention layers.
attention_bias = model_utils.get_padding_bias(inputs) # [batch_size, 1, 1, length].
# Run the inputs through the encoder layer to map the symbol
# representations to continuous representations.
encoder_outputs = self.encode(inputs, attention_bias)
# Generate output sequence if targets is None, or return logits if target
# sequence is known.
if targets is None:
return self.predict(encoder_outputs, attention_bias)
else:
logits = self.decode(targets, encoder_outputs, attention_bias)
return logits
2.编码部分(Input)
encoder的入口代码:
源码路径(代码 2.0.1):Official/Transformer/model/transformer.py
def encode(self, inputs, attention_bias):
"""Generate continuous representation for inputs.
Args:
inputs: int tensor with shape [batch_size, input_length].
attention_bias: float tensor with shape [batch_size, 1, 1, input_length]
Returns:
float tensor with shape [batch_size, input_length, hidden_size]
"""
with tf.name_scope("encode"):
# Prepare inputs to the layer stack by adding positional encodings and
# applying dropout.
### get embedding ---by zsw 2018.12.4
embedded_inputs = self.embedding_softmax_layer(inputs) # [batch_size, length, embedding_size]
inputs_padding = model_utils.get_padding(inputs) #ex.: [[0,0,0,1,1],
# [0,0,1,1,1] ]
###get position encoding and add with embedding ---by zsw 2018.12.4
with tf.name_scope("add_pos_encoding"):
length = tf.shape(embedded_inputs)[1] #[batch_size, length, embedding_size]
pos_encoding = model_utils.get_position_encoding(
length, self.params["hidden_size"])# [length, hidden_size]
encoder_inputs = embedded_inputs + pos_encoding
### Tricks : embedding layer dropout ---by zsw 2018.12.4
if self.train:
encoder_inputs = tf.nn.dropout(
encoder_inputs, 1 - self.params["layer_postprocess_dropout"])
return self.encoder_stack(encoder_inputs, attention_bias, inputs_padding)
Encoder实现代码:
源码路径(代码 2.0.2):Official/Transformer/model/transformer.py
class EncoderStack(tf.layers.Layer):
"""Transformer encoder stack.
The encoder stack is made up of N identical layers. Each layer is composed
of the sublayers:
1. Self-attention layer
2. Feedforward network (which is 2 fully-connected layers)
"""
def __init__(self, params, train):
super(EncoderStack, self).__init__()
self.layers = []
for _ in range(params["num_hidden_layers"]):
# Create sublayers for each layer.
self_attention_layer = attention_layer.SelfAttention(
params["hidden_size"], params["num_heads"],
params["attention_dropout"], train)
feed_forward_network = ffn_layer.FeedFowardNetwork(
params["hidden_size"], params["filter_size"],
params["relu_dropout"], train, params["allow_ffn_pad"])
self.layers.append([
PrePostProcessingWrapper(self_attention_layer, params, train),
PrePostProcessingWrapper(feed_forward_network, params, train)])
# Create final layer normalization layer.
### tricks : layerNorm
self.output_normalization = LayerNormalization(params["hidden_size"])
def call(self, encoder_inputs, attention_bias, inputs_padding):
"""Return the output of the encoder layer stacks.
Args:
encoder_inputs: tensor with shape [batch_size, input_length, hidden_size]
attention_bias: bias for the encoder self-attention layer.
[batch_size, 1, 1, input_length]
inputs_padding: P
Returns:
Output of encoder layer stack.
float32 tensor with shape [batch_size, input_length, hidden_size]
"""
for n, layer in enumerate(self.layers):
# Run inputs through the sublayers.
self_attention_layer = layer[0]
feed_forward_network = layer[1]
with tf.variable_scope("layer_%d" % n):
with tf.variable_scope("self_attention"):
encoder_inputs = self_attention_layer(encoder_inputs, attention_bias)
with tf.variable_scope("ffn"):
encoder_inputs = feed_forward_network(encoder_inputs, inputs_padding)
return self.output_normalization(encoder_inputs)
2.1.input embedding
将原文的所有单词汇总统计频率,删除低频词汇(比如出现次数小于20次的统一定义为’’);此时总共选出了假设10000个单词,则用数字编号为0~9999,一一对应,定义该对应表为word2num;然后用xaviers方法生成随机矩阵Matrix :10000行N列(10000行是确定的,对应10000个单词,N列自定义);这样就可以将10000个不同的单词通过word2num映射成10000个不同的数字(int),然后将10000个不同的数字通过Matrix映射成10000个不同的N维向量(如何映射?比如数字0,3,经过 Matrix映射分别变为向量Matrix[0],Matrix[3],维度为N维);这样,任何一个单词,都可以被映射成为唯一的一个N维向量(论文中hidden_size=embedding_size=512);
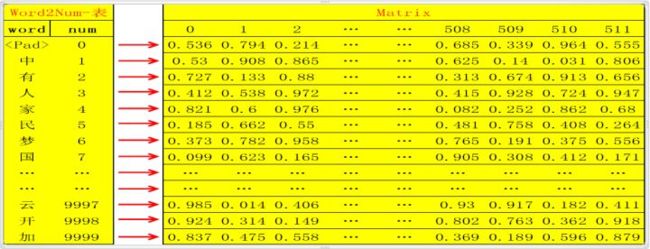
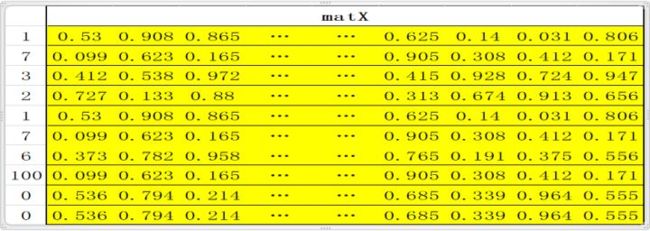
翻译的时候是一个句子一个句子的翻译,所以需要定义一个句子的标准长度,比如10个单词;如果一句话不足10个单词则用0填充(对应的word即word2num表中的),如果多了,删掉;这样一句话就是标准的10个单词;比如句子 “中国人有中国梦。”,这句话共有八个字(最后一个是结束符),经过word2num变为一列X:[1,7,3,2,1,7,6,100,0,0] (注:100代表的word是结束符),X经过Matrix映射为10行N列的矩阵matX= [Matrix[1], Matrix[7], Matrix[3], Matrix[2] , Matrix[1] , Matrix[7] , Matrix[6], Matrix[100] , Matrix[0] , Matrix[0]]; embedding 到此基本结束,即完成了将一句话变为 一个矩阵,矩阵的每一行代表一个特定的单词;此处还可以scale一下,即matX*N**(1/2);
源码解析(代码 2.1.1):
class EmbeddingSharedWeights(tf.layers.Layer):
"""Calculates input embeddings and pre-softmax linear with shared weights."""
def __init__(self, vocab_size, hidden_size, method="gather"):
"""Specify characteristic parameters of embedding layer.
Args:
vocab_size: Number of tokens in the embedding. (Typically ~32,000)
hidden_size: Dimensionality of the embedding. (Typically 512 or 1024)
method: Strategy for performing embedding lookup. "gather" uses tf.gather
which performs well on CPUs and GPUs, but very poorly on TPUs. "matmul"
one-hot encodes the indicies and formulates the embedding as a sparse
matrix multiplication. The matmul formulation is wasteful as it does
extra work, however matrix multiplication is very fast on TPUs which
makes "matmul" considerably faster than "gather" on TPUs.
"""
super(EmbeddingSharedWeights, self).__init__()
self.vocab_size = vocab_size
self.hidden_size = hidden_size
if method not in ("gather", "matmul"):
raise ValueError("method {} must be 'gather' or 'matmul'".format(method))
self.method = method
def build(self, _):
with tf.variable_scope("embedding_and_softmax", reuse=tf.AUTO_REUSE): ###why reuse? encoder and decoder use this embedding
##the word table which this embedding indicate include two language(for example:German and english)
# Create and initialize weights. The random normal initializer was chosen
# randomly, and works well.
self.shared_weights = tf.get_variable(
"weights", [self.vocab_size, self.hidden_size],
initializer=tf.random_normal_initializer(
0., self.hidden_size ** -0.5))
self.built = True
def call(self, x):
"""Get token embeddings of x.
Args:
x: An int64 tensor with shape [batch_size, length]
Returns:
embeddings: float32 tensor with shape [batch_size, length, embedding_size]
padding: float32 tensor with shape [batch_size, length] indicating the
locations of the padding tokens in x.
"""
with tf.name_scope("embedding"):
# Create binary mask of size [batch_size, length]
mask = tf.to_float(tf.not_equal(x, 0))
if self.method == "gather":
embeddings = tf.gather(self.shared_weights, x)
embeddings *= tf.expand_dims(mask, -1)
else: # matmul
embeddings = tpu_utils.embedding_matmul(
embedding_table=self.shared_weights,
values=tf.cast(x, dtype=tf.int32),
mask=mask
)
# embedding_matmul already zeros out masked positions, so
# `embeddings *= tf.expand_dims(mask, -1)` is unnecessary.
# Scale embedding by the sqrt of the hidden size
embeddings *= self.hidden_size ** 0.5
return embeddings
2.2.Positional encoding
- 单词在句子中的不同位置体现了不同信息,所以需要对位置进行编码,体现不同的信息情况,此处是对绝对位置进行编码,即位置数字0,1,2,3,…N等,进行运 算编码,具体编码如下:
对于句子中的每一个字,其位置pos∈0,1,2,…,9,每个字是N(512)维向量,维度 i (i∈[ 0,1,2,3,4,…N])带入函数:
f ( p o s , i ) = p o s 1000 0 i / N f(pos,i)=\frac {pos}{10000^{i/N}} f(pos,i)=10000i/Npos - 经过如上函数运行一次后,获得了一个10行N列的矩阵matP;每一行代表一个绝对位置信息,此时matP的shape和matX的shape相同;

- 对于矩阵matP的每一行,第0,2,4,6,…等偶数列上的值用sin()函数激 活,第1,3,5,。。。等奇数列的值用cos()函数激活,以此更新matP;即 matP[:,0::2]=sin(matP[:,0::2]), matP[:,1::2]=cos(matP[:,1::2]);

- 至此positional encoding结束,最后通常也会scale一次,即对更新后的matP进行matP*N**(1/2)运算,得到再次更新的matP,此时的matP的shape还是和matX相 同;然后将matP和matX相加即matEnc=matP+matX,矩阵matEnc其shape=[10,512];
但是在论文实现时有两点不同:- 没有采用sin() 和cos()交叉的方式 ,而是前半hidden_size/2用了sin()函数,后半hidden_size/2用了cos()函数
- 在position embedding的时候没有进行规范化(matP*N**(1/2))
源码路径(代码 2.2.1):official\transformer\model\model_utils.py
def get_position_encoding(
length, hidden_size, min_timescale=1.0, max_timescale=1.0e4):
"""Return positional encoding.
Calculates the position encoding as a mix of sine and cosine functions with
geometrically increasing wavelengths.
Defined and formulized in Attention is All You Need, section 3.5.
Args:
length: Sequence length.
hidden_size: Size of the
min_timescale: Minimum scale that will be applied at each position
max_timescale: Maximum scale that will be applied at each position
Returns:
Tensor with shape [length, hidden_size]
"""
position = tf.to_float(tf.range(length))
num_timescales = hidden_size // 2
log_timescale_increment = (
math.log(float(max_timescale) / float(min_timescale)) /
(tf.to_float(num_timescales) - 1))
inv_timescales = min_timescale * tf.exp(
tf.to_float(tf.range(num_timescales)) * -log_timescale_increment) ####[hidden_size/2]
scaled_time = tf.expand_dims(position, 1) * tf.expand_dims(inv_timescales, 0) #if min_timescal=1 :对于sin(): sin(pos*(exp(2i/{model}*-log(10000)))) 和原公式等价
signal = tf.concat([tf.sin(scaled_time), tf.cos(scaled_time)], axis=1)
return signal
2.3.Multi-head attention
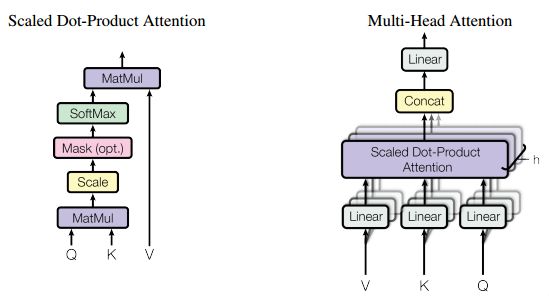
Multi-head attention 由三个输入,分别为V,K,Q,此处V=K=Q=matEnc(在解码部分multi-head attention中的VKQ三者不是这种关系);
- 首先分别对V,K,Q三者分别进行线性变换,即将三者分别输入到三个单层神经网络层,激活函数选择relu,输出新的V,K,Q(三者shape都和原来shape相同,即经过线性变换时输出维度和输入维度相同);
- 然后将Q在最后一维上进行切分为num_heads(假设为8)段,然后对切分完的矩阵在axis=0维上进行concat链接起来;对V和K都进行和Q一样的操作;操作后的矩阵记为Q_,K_,V_;
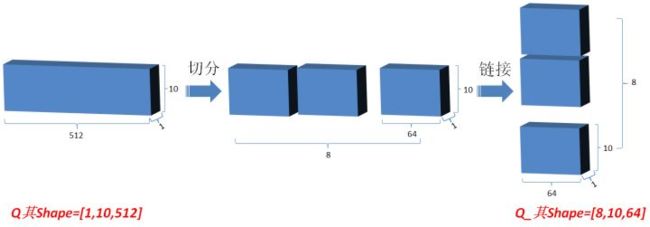

这里在实现multi head的时候,并不是把self attention做8次,因为矩阵相乘能特别方便的完成该操作,tf.matmul([8,10,64],[8,10,64],transpose=True)的结果就是[8,10,10],相当于并行把multi head attention做完了
- Q_矩阵相乘 K_的转置(对最后2维),生成结果记为outputs,然后对outputs 进行scale一次更新为outputs;此次矩阵相乘是计算词与词的相关性,切成多个num_heads进行计算是为了实现对词与词之间深层次相关性进行计算;

- 对outputs进行softmax运算,更新outputs,即outputs=softmax(outputs);
- 最新的outputs(即K和Q的相关性,而K和V一直相等) 矩阵相乘 V_, 其值更新为outputs;

- 最后将outputs在axis=0维上切分为num_heads段,然后在axis=2维上合并, 恢复原来Q的维度;
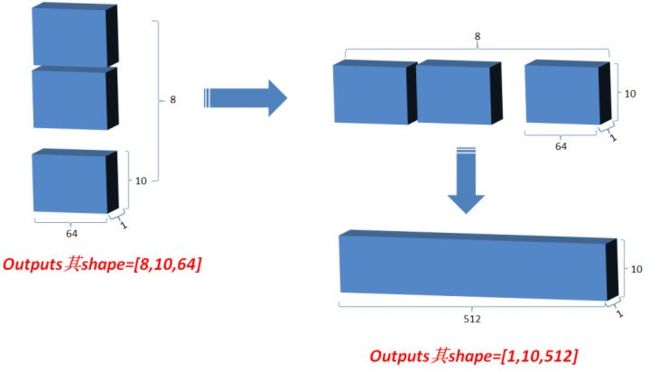
源码路径(代码 2.3.1):official\transformer\model\transformer.py
class SelfAttention(Attention):
"""Multiheaded self-attention layer."""
def call(self, x, bias, cache=None):
return super(SelfAttention, self).call(x, x, bias, cache)
class Attention(tf.layers.Layer):
"""Multi-headed attention layer."""
def __init__(self, hidden_size, num_heads, attention_dropout, train):
if hidden_size % num_heads != 0:
raise ValueError("Hidden size must be evenly divisible by the number of "
"heads.")
super(Attention, self).__init__()
self.hidden_size = hidden_size
self.num_heads = num_heads
self.attention_dropout = attention_dropout
self.train = train
# Layers for linearly projecting the queries, keys, and values.
self.q_dense_layer = tf.layers.Dense(hidden_size, use_bias=False, name="q")
self.k_dense_layer = tf.layers.Dense(hidden_size, use_bias=False, name="k")
self.v_dense_layer = tf.layers.Dense(hidden_size, use_bias=False, name="v")
self.output_dense_layer = tf.layers.Dense(hidden_size, use_bias=False,
name="output_transform")
def split_heads(self, x):
"""Split x into different heads, and transpose the resulting value.
The tensor is transposed to insure the inner dimensions hold the correct
values during the matrix multiplication.
Args:
x: A tensor with shape [batch_size, length, hidden_size]
Returns:
A tensor with shape [batch_size, num_heads, length, hidden_size/num_heads]
"""
with tf.name_scope("split_heads"):
batch_size = tf.shape(x)[0]
length = tf.shape(x)[1]
# Calculate depth of last dimension after it has been split.
depth = (self.hidden_size // self.num_heads)
# Split the last dimension
x = tf.reshape(x, [batch_size, length, self.num_heads, depth]) ###
# Transpose the result
return tf.transpose(x, [0, 2, 1, 3])###[batch_size, num_heads, length, hidden_size/num_heads]
def combine_heads(self, x):
"""Combine tensor that has been split.
Args:
x: A tensor [batch_size, num_heads, length, hidden_size/num_heads]
Returns:
A tensor with shape [batch_size, length, hidden_size]
"""
with tf.name_scope("combine_heads"):
batch_size = tf.shape(x)[0]
length = tf.shape(x)[2]
x = tf.transpose(x, [0, 2, 1, 3]) # --> [batch, length, num_heads, depth]
return tf.reshape(x, [batch_size, length, self.hidden_size])
def call(self, x, y, bias, cache=None):
"""Apply attention mechanism to x and y.
Args:
x: a tensor with shape [batch_size, length_x, hidden_size]
y: a tensor with shape [batch_size, length_y, hidden_size]
bias: attention bias that will be added to the result of the dot product.
cache: (Used during prediction) dictionary with tensors containing results
of previous attentions. The dictionary must have the items:
{"k": tensor with shape [batch_size, i, key_channels],
"v": tensor with shape [batch_size, i, value_channels]}
where i is the current decoded length.
Returns:
Attention layer output with shape [batch_size, length_x, hidden_size]
"""
# Linearly project the query (q), key (k) and value (v) using different
# learned projections. This is in preparation of splitting them into
# multiple heads. Multi-head attention uses multiple queries, keys, and
# values rather than regular attention (which uses a single q, k, v).
q = self.q_dense_layer(x)
k = self.k_dense_layer(y)
v = self.v_dense_layer(y)
if cache is not None:
# Combine cached keys and values with new keys and values.
k = tf.concat([cache["k"], k], axis=1)
v = tf.concat([cache["v"], v], axis=1)
# Update cache
cache["k"] = k
cache["v"] = v
# Split q, k, v into heads.
q = self.split_heads(q) #[batch_size, num_heads, length, hidden_size/num_heads]
k = self.split_heads(k)
v = self.split_heads(v)
# Scale q to prevent the dot product between q and k from growing too large.
depth = (self.hidden_size // self.num_heads)
q *= depth ** -0.5
# Calculate dot product attention
logits = tf.matmul(q, k, transpose_b=True)
logits += bias
weights = tf.nn.softmax(logits, name="attention_weights")
if self.train:
weights = tf.nn.dropout(weights, 1.0 - self.attention_dropout)
attention_output = tf.matmul(weights, v)
# Recombine heads --> [batch_size, length, hidden_size]
attention_output = self.combine_heads(attention_output)
# Run the combined outputs through another linear projection layer.
attention_output = self.output_dense_layer(attention_output)
return attention_output
2.4.Add&Norm
-
标准化矫正一次,在outputs对最后一维计算均值和方差,用outputs减去均值除以方差+spsilon得值更新为outputs,然后变量gamma*outputs+变量beta;这里的标准化就是我们常数的layer normalization
源码路径(代码 2.4.1):official\transformer\model\transformer.pyclass LayerNormalization(tf.layers.Layer): """Applies layer normalization.""" def __init__(self, hidden_size): super(LayerNormalization, self).__init__() self.hidden_size = hidden_size def build(self, _): self.scale = tf.get_variable("layer_norm_scale", [self.hidden_size], initializer=tf.ones_initializer()) self.bias = tf.get_variable("layer_norm_bias", [self.hidden_size], initializer=tf.zeros_initializer()) self.built = True def call(self, x, epsilon=1e-6): mean = tf.reduce_mean(x, axis=[-1], keepdims=True) variance = tf.reduce_mean(tf.square(x - mean), axis=[-1], keepdims=True) norm_x = (x - mean) * tf.rsqrt(variance + epsilon) return norm_x * self.scale + self.bias -
类似ResNet,将最初的输入与其对应的输出(attention只有的结果)叠加一次,即outputs=outputs+Q, 使网络有效叠加,避免梯度消失:

源码地址(代码 2.4.2):
official\transformer\model\transformer.pyclass PrePostProcessingWrapper(object): """Wrapper class that applies layer pre-processing and post-processing.""" def __init__(self, layer, params, train): self.layer = layer self.postprocess_dropout = params["layer_postprocess_dropout"] self.train = train # Create normalization layer self.layer_norm = LayerNormalization(params["hidden_size"]) def __call__(self, x, *args, **kwargs): # Preprocessing: apply layer normalization y = self.layer_norm(x) # Get layer output y = self.layer(y, *args, **kwargs) # Postprocessing: apply dropout and residual connection if self.train: y = tf.nn.dropout(y, 1 - self.postprocess_dropout) return x + y
2.5.FeedForward
对outputs进行第一次卷积操作,结果更新为outputs(卷积核为1*1,每一次卷积操作的计算发生在一个词对应的向量元素上,卷积核数目即最后一维向量长度,也就是一个词对应的向量维数);
这里有点不太理解网上的这种说法,为什么卷积核是1*1,实际代码只是一个dense layer呀?望理解的大佬指教~
对最新outputs进行第二次卷积操作,卷积核仍然为1*1,卷积核数目为N;
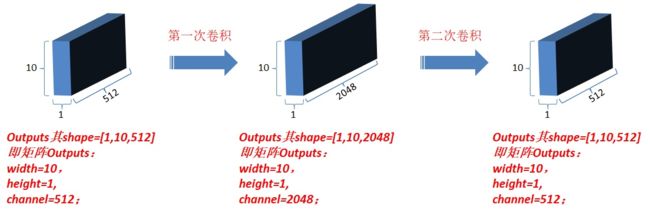
源码路径(代码 2.5.1):Official/transformer/model/ffn_layer.py
这里的实际代码中,在进入dense layer之前,先对padding的index去掉了,然后对batch中的非padding的向量送到dense layer,这样的好处是减少了padding的内容,从而让batch实际操作的内容大大减少,从而可以提高batch的大小(个人理解)
这里需要注意的是,在过这两层dense layer的时候,第一层采用的是relu函数,但是第二层没有激活函数,相当于第二层是线性的,原因是?我个人认为之所以要用两层dense layer,是因为第一层有激活函数的原因
class FeedFowardNetwork(tf.layers.Layer):
"""Fully connected feedforward network."""
def __init__(self, hidden_size, filter_size, relu_dropout, train, allow_pad):
super(FeedFowardNetwork, self).__init__()
self.hidden_size = hidden_size
self.filter_size = filter_size
self.relu_dropout = relu_dropout
self.train = train
self.allow_pad = allow_pad
self.filter_dense_layer = tf.layers.Dense(
filter_size, use_bias=True, activation=tf.nn.relu, name="filter_layer")
self.output_dense_layer = tf.layers.Dense(
hidden_size, use_bias=True, name="output_layer")
def call(self, x, padding=None):
"""Return outputs of the feedforward network.
Args:
x: tensor with shape [batch_size, length, hidden_size]
padding: (optional) If set, the padding values are temporarily removed
from x (provided self.allow_pad is set). The padding values are placed
back in the output tensor in the same locations.
shape [batch_size, length]
Returns:
Output of the feedforward network.
tensor with shape [batch_size, length, hidden_size]
"""
padding = None if not self.allow_pad else padding
# Retrieve dynamically known shapes
batch_size = tf.shape(x)[0]
length = tf.shape(x)[1]
if padding is not None:
with tf.name_scope("remove_padding"):
# Flatten padding to [batch_size*length]
pad_mask = tf.reshape(padding, [-1]) # [[0,0,0,1,1],
# [0,0,1,1,1] ] => [0,0,0,1,1,0,0,1,1,1]
nonpad_ids = tf.to_int32(tf.where(pad_mask < 1e-9)) ### nopad == 0
# [[0],[1],[2],[5],[6]]
# Reshape x to [batch_size*length, hidden_size] to remove padding
x = tf.reshape(x, [-1, self.hidden_size])
x = tf.gather_nd(x, indices=nonpad_ids) #### [nopad_number, hidden_size]
# Reshape x from 2 dimensions to 3 dimensions.
x.set_shape([None, self.hidden_size])
x = tf.expand_dims(x, axis=0) ###[1,nopad_number, hidden_size]
output = self.filter_dense_layer(x)
if self.train:
output = tf.nn.dropout(output, 1.0 - self.relu_dropout)
output = self.output_dense_layer(output)
if padding is not None:
with tf.name_scope("re_add_padding"):
output = tf.squeeze(output, axis=0)
output = tf.scatter_nd(
indices=nonpad_ids,
updates=output,
shape=[batch_size * length, self.hidden_size]
)
output = tf.reshape(output, [batch_size, length, self.hidden_size])
return output
2.6.Add&Norm
Add&norm : 和3.3相同,经过以上操作后,此时最新的output和matEnc的shape相同;
2.7.编码Block Loop
完成上面2.1-2.6小结的过程后,已经完成了Encoder stack里面的一次编码,之后令matEnc=outputs, 完成一次循环,然后返回到2.1开始第二次循环;共循环Nx(自定义;每一次循环其结构相同,但对应的参数是不同的,即是独立训练的);完成Nx次后,模型的编码部分完成,仍然令matEnc=outputs,准备进入解码部分;(对应多层循环部分详见代码2.0.2)
3.解码
这里的结构和编码大同小异,只不过增加了self attention之后的Mask Attention结构。
解码整体入口部分(代码3.0.1):official\transformer\model\transformer.py
def decode(self, targets, encoder_outputs, attention_bias):
"""Generate logits for each value in the target sequence.
Args:
targets: target values for the output sequence.
int tensor with shape [batch_size, target_length]
encoder_outputs: continuous representation of input sequence.
float tensor with shape [batch_size, input_length, hidden_size]
attention_bias: float tensor with shape [batch_size, 1, 1, input_length]
Returns:
float32 tensor with shape [batch_size, target_length, vocab_size]
"""
with tf.name_scope("decode"):
# Prepare inputs to decoder layers by shifting targets, adding positional
# encoding and applying dropout.
decoder_inputs = self.embedding_softmax_layer(targets)
with tf.name_scope("shift_targets"):
# Shift targets to the right, and remove the last element
decoder_inputs = tf.pad(
decoder_inputs, [[0, 0], [1, 0], [0, 0]])[:, :-1, :] ###add [0,0...] to as the first word
with tf.name_scope("add_pos_encoding"):
length = tf.shape(decoder_inputs)[1]
decoder_inputs += model_utils.get_position_encoding(
length, self.params["hidden_size"])
if self.train:
decoder_inputs = tf.nn.dropout(
decoder_inputs, 1 - self.params["layer_postprocess_dropout"])
# Run values
decoder_self_attention_bias = model_utils.get_decoder_self_attention_bias(
length)
outputs = self.decoder_stack(
decoder_inputs, encoder_outputs, decoder_self_attention_bias,
attention_bias)
logits = self.embedding_softmax_layer.linear(outputs)
return logits
解码整体实现部分(代码3.0.2):
class DecoderStack(tf.layers.Layer):
"""Transformer decoder stack.
Like the encoder stack, the decoder stack is made up of N identical layers.
Each layer is composed of the sublayers:
1. Self-attention layer
2. Multi-headed attention layer combining encoder outputs with results from
the previous self-attention layer.
3. Feedforward network (2 fully-connected layers)
"""
def __init__(self, params, train):
super(DecoderStack, self).__init__()
self.layers = []
for _ in range(params["num_hidden_layers"]):
self_attention_layer = attention_layer.SelfAttention(
params["hidden_size"], params["num_heads"],
params["attention_dropout"], train)
enc_dec_attention_layer = attention_layer.Attention(
params["hidden_size"], params["num_heads"],
params["attention_dropout"], train)
feed_forward_network = ffn_layer.FeedFowardNetwork(
params["hidden_size"], params["filter_size"],
params["relu_dropout"], train, params["allow_ffn_pad"])
self.layers.append([
PrePostProcessingWrapper(self_attention_layer, params, train),
PrePostProcessingWrapper(enc_dec_attention_layer, params, train),
PrePostProcessingWrapper(feed_forward_network, params, train)])
self.output_normalization = LayerNormalization(params["hidden_size"])
def call(self, decoder_inputs, encoder_outputs, decoder_self_attention_bias,
attention_bias, cache=None):
"""Return the output of the decoder layer stacks.
Args:
decoder_inputs: tensor with shape [batch_size, target_length, hidden_size]
encoder_outputs: tensor with shape [batch_size, input_length, hidden_size]
decoder_self_attention_bias: bias for decoder self-attention layer.
[1, 1, target_len, target_length]
attention_bias: bias for encoder-decoder attention layer.
[batch_size, 1, 1, input_length]
cache: (Used for fast decoding) A nested dictionary storing previous
decoder self-attention values. The items are:
{layer_n: {"k": tensor with shape [batch_size, i, key_channels],
"v": tensor with shape [batch_size, i, value_channels]},
...}
Returns:
Output of decoder layer stack.
float32 tensor with shape [batch_size, target_length, hidden_size]
"""
for n, layer in enumerate(self.layers):
self_attention_layer = layer[0]
enc_dec_attention_layer = layer[1]
feed_forward_network = layer[2]
# Run inputs through the sublayers.
layer_name = "layer_%d" % n
layer_cache = cache[layer_name] if cache is not None else None
with tf.variable_scope(layer_name):
with tf.variable_scope("self_attention"):
decoder_inputs = self_attention_layer(
decoder_inputs, decoder_self_attention_bias, cache=layer_cache)
with tf.variable_scope("encdec_attention"):
decoder_inputs = enc_dec_attention_layer(
decoder_inputs, encoder_outputs, attention_bias)
with tf.variable_scope("ffn"):
decoder_inputs = feed_forward_network(decoder_inputs)
return self.output_normalization(decoder_inputs)
3.1.target sequence embedding
- Outputs:shifted right右移一位,是为了解码区最初初始化时第一次输入,并将其统一定义为特定值(在word2num中提前定义),详见代码3.0.1,对应代码如下:
decoder_inputs = tf.pad( decoder_inputs, [[0, 0], [1, 0], [0, 0]])[:, :-1, :] ###add [0,0...] to as the first word - target sequence embedding: 同编码部分;更新outputs;
3.2.Positional embedding
同编码部分;更新outputs;
3.3. self attention
进入解码区循环体,即figure1中右侧红框内的部分;
Masked multi-head attention: 和编码部分的multi-head attention类似,但是多了一 次masked,因为在解码部分,解码的时候时从左到右依次解码的,当解出第一个字的时候,第一个字只能与第一个字计算相关性,当解出第二个字的时候,只能计算出第二个字与第一个字和第二个字的相关性,。。。;所以需要linalg.LinearOperatorLowerTriangular进行一次mask;
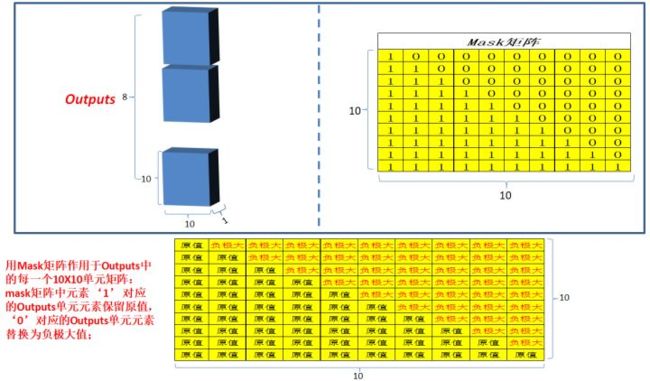
源码解析(代码3.3.0):official\transformer\model\model_utils.py
def get_decoder_self_attention_bias(length):
"""Calculate bias for decoder that maintains model's autoregressive property.
Creates a tensor that masks out locations that correspond to illegal
connections, so prediction at position i cannot draw information from future
positions.
Args:
length: int length of sequences in batch.
Returns:
float tensor of shape [1, 1, length, length]
"""
with tf.name_scope("decoder_self_attention_bias"):
valid_locs = tf.matrix_band_part(tf.ones([length, length]), -1, 0) ###下三角矩阵
valid_locs = tf.reshape(valid_locs, [1, 1, length, length])
decoder_bias = _NEG_INF * (1.0 - valid_locs) # 上三角矩阵 上三角-INF
return decoder_bias
3.4.Add&Norm
同编码部分,更新outputs;
3.5.Multi-head attention
同编码部分,但是Q和K,V不再相同,Q=outputs,K=V=matEnc;
3.6.Add&norm
同编码部分,更新outputs;
3.7.Feed-Forward
同编码部分,更新outputs;
3.8. Add&norm
同编码部分,更新outputs;
3.9 解码Block Loop
最新outputs和最开始进入该循环时候的outputs的shape相同;回到4.1,开始第 二次循环。。。;直到完成Nx次循环(自定义;每一次循环其结构相同,但对应的参数是不同的,即独立训练的);
3.10.Linear&Softmax
Linear: 将最新的outputs,输入到单层神经网络中,输出层维度为“译文”有效单词总数;更新outputs;
softmax:对outputs进行softmax运算,确定模型译文和原译文比较计算loss,进行网络优化;
4.模型Predict
上面说的都是模型的Train的阶段,那么模型怎么predict呢?decoder的时候是借助了target的结果的呀!但是predict很明显是拿不到结果的target sequence的,这就需要predict逻辑了,在(代码1.0.1)中有这样的逻辑
if targets is None:
return self.predict(encoder_outputs, attention_bias)
else:
logits = self.decode(targets, encoder_outputs, attention_bias)
也就是如果没有target,就走predict的模块,该部分的逻辑是先通过decoder的逻辑一个一个的生成target的结果,然后最后直到结束符结束decoder,也就是说原来的decoder要进行好多次,生成完整的结果。
到这里我们再想一下,还记得之前decoder部分有一个self attention的mask操作吗?当时为什么要mask呢?其实后面的对生成结果是有用的,但是如果训练的时候不mask而是用了后面的信息,那么predict的时候没有结果作为输入序列,那怎么Predict呢?是不是模型就白白训练了呢?
源码(代码4.0.1)路径:official\transformer\model\transformer.py`
def predict(self, encoder_outputs, encoder_decoder_attention_bias):
"""Return predicted sequence."""
batch_size = tf.shape(encoder_outputs)[0]
input_length = tf.shape(encoder_outputs)[1]
max_decode_length = input_length + self.params["extra_decode_length"]
symbols_to_logits_fn = self._get_symbols_to_logits_fn(max_decode_length)
# Create initial set of IDs that will be passed into symbols_to_logits_fn.
initial_ids = tf.zeros([batch_size], dtype=tf.int32)
# Create cache storing decoder attention values for each layer.
cache = {
"layer_%d" % layer: {
"k": tf.zeros([batch_size, 0, self.params["hidden_size"]]),
"v": tf.zeros([batch_size, 0, self.params["hidden_size"]]),
} for layer in range(self.params["num_hidden_layers"])}
# Add encoder output and attention bias to the cache.
cache["encoder_outputs"] = encoder_outputs
cache["encoder_decoder_attention_bias"] = encoder_decoder_attention_bias
# Use beam search to find the top beam_size sequences and scores.
decoded_ids, scores = beam_search.sequence_beam_search(
symbols_to_logits_fn=symbols_to_logits_fn,
initial_ids=initial_ids,
initial_cache=cache,
vocab_size=self.params["vocab_size"],
beam_size=self.params["beam_size"],
alpha=self.params["alpha"],
max_decode_length=max_decode_length,
eos_id=EOS_ID)
# Get the top sequence for each batch element
top_decoded_ids = decoded_ids[:, 0, 1:]
top_scores = scores[:, 0]
return {"outputs": top_decoded_ids, "scores": top_scores}
def _get_symbols_to_logits_fn(self, max_decode_length):
"""Returns a decoding function that calculates logits of the next tokens."""
timing_signal = model_utils.get_position_encoding(
max_decode_length + 1, self.params["hidden_size"]) ###get position embedding
decoder_self_attention_bias = model_utils.get_decoder_self_attention_bias(
max_decode_length) ####get the decoding mask upper triangular matrix(upper parameter all is -INF)
def symbols_to_logits_fn(ids, i, cache):
"""Generate logits for next potential IDs.
Args:
ids: Current decoded sequences.
int tensor with shape [batch_size * beam_size, i + 1]
i: Loop index
cache: dictionary of values storing the encoder output, encoder-decoder
attention bias, and previous decoder attention values.
Returns:
Tuple of
(logits with shape [batch_size * beam_size, vocab_size],
updated cache values)
"""
# Set decoder input to the last generated IDs
decoder_input = ids[:, -1:]
# Preprocess decoder input by getting embeddings and adding timing signal.
decoder_input = self.embedding_softmax_layer(decoder_input)
decoder_input += timing_signal[i:i + 1] ##add position signal to word embedding
self_attention_bias = decoder_self_attention_bias[:, :, i:i + 1, :i + 1] #######??????
decoder_outputs = self.decoder_stack(
decoder_input, cache.get("encoder_outputs"), self_attention_bias,
cache.get("encoder_decoder_attention_bias"), cache)
logits = self.embedding_softmax_layer.linear(decoder_outputs)
logits = tf.squeeze(logits, axis=[1])
return logits, cache
return symbols_to_logits_fn
最终的decoder stack输出的是浮点型的向量,那怎么把它变为一个翻译的目标单词呢?这就需要最后的Linear layer以及后面的Softmax Layer了。
假如模型的输出词表大小为10000,那么通过全连接之后,会得到每个单词的相关分数,最后通过softmax,从而得出当前的分值最大的output word。这里也就需要Search的相关代码了。
具体代码路径:official\transformer\model\beam_search.py,就不详细介绍了~