GAN - Anime
前言
这是看了18年李宏毅(Hung-yi Lee)的GAN课程做的作业。
课程主页:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html
基于tensorflow框架,第一次实现参考了别人的代码。
1.网络模型搭建
生成器4层,从小到大,经历一次全连接,2次上采样,3次卷积,最后tanh()激活后输出。
鉴别器5层,4次卷积后,接一次全连接,最后sigmoid()激活后输出。
中间的卷积层后接BN+LeakyReLU。

2.训练策略(超参数)
z_dimensions=100是别人的代码里预设的。
batch_size=50是我觉得凑个整数比较好,后来看到某论文说大家一般用bsize=64,后悔不已。(bigGAN的256除外)
迭代步骤D:G=5:1是某篇论文推荐的。
Iteration开了20w次我有点后悔,好像一般几万之后效果不佳就可以人为停止,开始调整模型了。
#基础设置
input_dir = ''
RESULT_ROOT = ''
Z_DIMENSIONS = 100
BATCH_SIZE = 50
ITERATION = 200000 #训练次数
D_UPDATE = 5 #每次迭代更新鉴别器次数
G_UPDATE = 1 #一般推荐生成器更新少一点,鉴别器更新多一点
Learningrate = 0.0001
3结果呈现
挺奇怪的......在每层LeakyReLU之前,做BN的时候,没有让gamma进入训练单位。
在服务器上跑了一晚上,20万次迭代,最后结果还是跟别人的差很多。
generation是有点进步了......
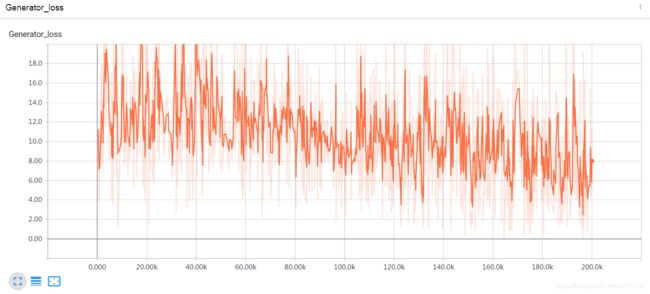
但是dscriminator在real和fake上的loss一直在涨。我都要怀疑是不是写错方程把minimize写成maximize了......
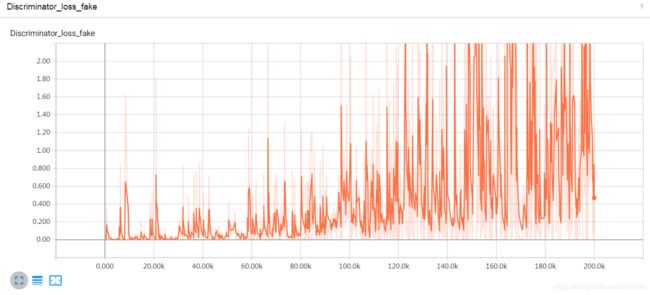
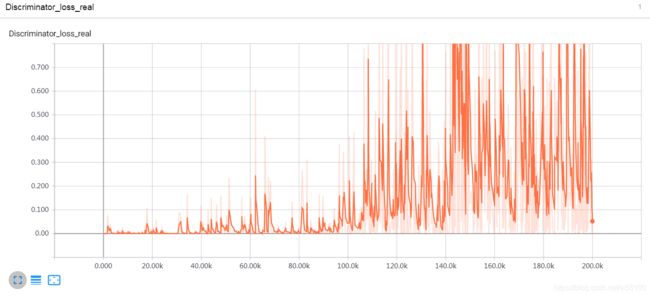
从output来看,也是一样的奇怪,鉴别器像坏了一样,识别不出来真假了。
中期开始,就仿佛陷入了奇怪的颠簸。
1万次迭代的时候,还有点彩色的感觉。
10万次就变成了很奇怪的灰蒙蒙的样子,而discriminatior没有对这种灰蒙蒙作出批评。
10万次~20万次,好像没什么进步。
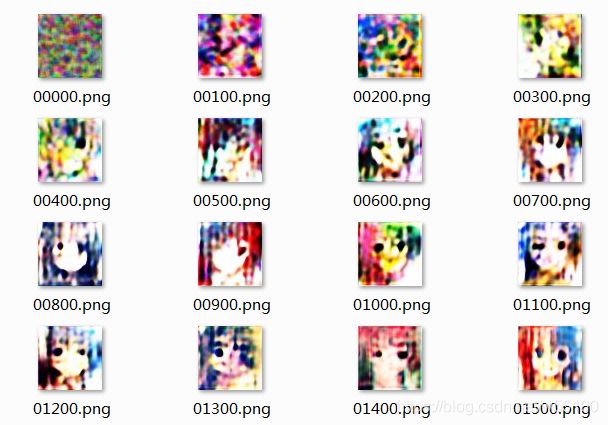
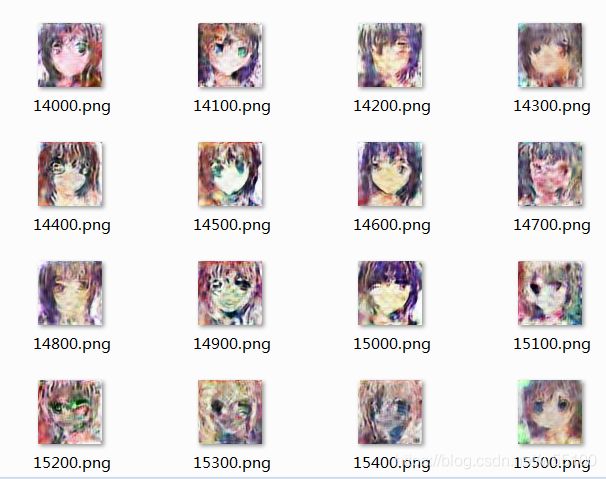
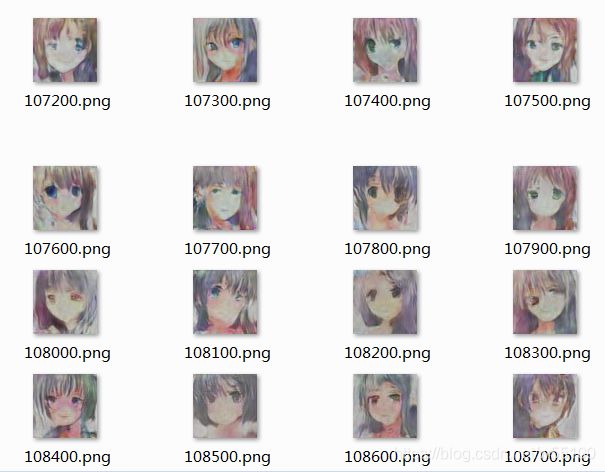
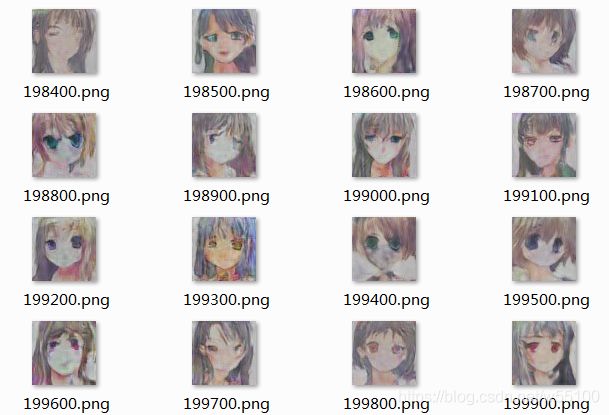
不确定具体原因。
由于我使用的LossFuction是Goodfellow在2014年提出的basicGAN。
后面被证明稳定性不好,猜测可能是由于模型的缘故。
准备再看看论文,修改LossFunction,加个正则之类的。
190227
----------------------------
190304 :
学完新的改进方法 读《Which Training Methods for GANs do actually Converge?》
尝试加入正则项训练。
#新增正则项
gamma=20
#返回的是一个list,由于我们输入只有一个x_placeholder所以只需要取第一位
grad_dx=tf.gradients(d_x,x_placeholder)[0]
#平方
grad_dx2=tf.reshape(tf.square(grad_dx),[-1,64*64*3])
#求期望
E_grad_dx2 = tf.reduce_mean(tf.reduce_sum(grad_dx2,axis=1))
#乘以超参数
d_loss_reg=0.5*gamma*E_grad_dx2
然而,由于我加了reg,等于改了模型。
tensorflow调试了好久,restore一直出错!!!
用了双图加载法也不行。
最后无奈只能从头开始重新训练 。
这次加了reg项之后,最大的感受是收敛确实快......
无论哪边的loss都很快降到了十分小的单位。
但是问题也来了,貌似学习的速度非常慢。
猜测是由于d_loss太小,鉴别器做的太好了,所以g不知道怎么学习。
generate出来的图片性质很糟糕,一点人样都看不出来。
d_loss_real_score: 0.005343113 d_loss_fake_score: 0.036767576 g_loss_score: 5.567666
d_loss_real_score: 0.16478942 d_loss_fake_score: 0.08139466 g_loss_score: 2.3662953
d_loss_real_score: 0.010131013 d_loss_fake_score: 0.0055198353 g_loss_score: 5.635129
d_loss_real_score: 0.106044084 d_loss_fake_score: 0.092205316 g_loss_score: 4.1113014
d_loss_real_score: 0.010212776 d_loss_fake_score: 0.002461825 g_loss_score: 6.70146
d_loss_real_score: 0.006576837 d_loss_fake_score: 0.0037410064 g_loss_score: 6.0741563
d_loss_real_score: 0.0054735816 d_loss_fake_score: 0.0044755517 g_loss_score: 7.3124676
d_loss_real_score: 0.062391043 d_loss_fake_score: 0.07353632 g_loss_score: 2.560544
d_loss_real_score: 0.06790272 d_loss_fake_score: 0.042310532 g_loss_score: 2.6867256
d_loss_real_score: 0.041228108 d_loss_fake_score: 0.024072465 g_loss_score: 4.014058
d_loss_real_score: 0.02995653 d_loss_fake_score: 0.021657359 g_loss_score: 4.358259
d_loss_real_score: 0.33055916 d_loss_fake_score: 0.86018467 g_loss_score: 0.80682266
d_loss_real_score: 0.22805573 d_loss_fake_score: 1.2085671 g_loss_score: 0.40464938
d_loss_real_score: 0.2124552 d_loss_fake_score: 0.9726736 g_loss_score: 0.83934057
d_loss_real_score: 0.21163458 d_loss_fake_score: 0.82160306 g_loss_score: 0.75299716
d_loss_real_score: 0.19782037 d_loss_fake_score: 0.81496835 g_loss_score: 0.6234523
d_loss_real_score: 0.17652345 d_loss_fake_score: 0.9390157 g_loss_score: 0.6418907
d_loss_real_score: 0.15939075 d_loss_fake_score: 0.95342934 g_loss_score: 0.60425675
d_loss_real_score: 0.16841677 d_loss_fake_score: 1.4444671 g_loss_score: 0.2616862
d_loss_real_score: 0.18047315 d_loss_fake_score: 1.3845222 g_loss_score: 0.6511333
d_loss_real_score: 0.15019032 d_loss_fake_score: 1.0622826 g_loss_score: 0.58802974
d_loss_real_score: 0.24260435 d_loss_fake_score: 0.8828178 g_loss_score: 0.721226
d_loss_real_score: 0.19288911 d_loss_fake_score: 1.3520197 g_loss_score: 0.48308402
d_loss_real_score: 0.2194582 d_loss_fake_score: 1.0456469 g_loss_score: 0.6393894
d_loss_real_score: 0.21083051 d_loss_fake_score: 1.0894017 g_loss_score: 0.94105697
d_loss_real_score: 0.19490531 d_loss_fake_score: 1.0507628 g_loss_score: 0.63515437
d_loss_real_score: 0.31742823 d_loss_fake_score: 0.88690114 g_loss_score: 0.90733886
d_loss_real_score: 0.17378336 d_loss_fake_score: 1.1312621 g_loss_score: 0.8181675
d_loss_real_score: 0.21248811 d_loss_fake_score: 1.1372433 g_loss_score: 0.7109188
d_loss_real_score: 0.14744556 d_loss_fake_score: 1.5381187 g_loss_score: 0.49809802
d_loss_real_score: 0.17993814 d_loss_fake_score: 0.9061226 g_loss_score: 0.7801962
d_loss_real_score: 0.286298 d_loss_fake_score: 0.9035955 g_loss_score: 0.9747153
d_loss_real_score: 0.20352158 d_loss_fake_score: 1.3611794 g_loss_score: 0.62408894
d_loss_real_score: 0.21909618 d_loss_fake_score: 0.61599606 g_loss_score: 0.9713102
d_loss_real_score: 0.22870737 d_loss_fake_score: 0.7651367 g_loss_score: 0.7541059
d_loss_real_score: 0.20967256 d_loss_fake_score: 0.96533364 g_loss_score: 0.80578583
d_loss_real_score: 0.12931567 d_loss_fake_score: 1.1115848 g_loss_score: 0.9371185
d_loss_real_score: 0.21817479 d_loss_fake_score: 1.1937568 g_loss_score: 0.5864024
d_loss_real_score: 0.13808759 d_loss_fake_score: 1.4493461 g_loss_score: 0.59239656
d_loss_real_score: 0.13292883 d_loss_fake_score: 1.2653619 g_loss_score: 0.581338
d_loss_real_score: 0.20021355 d_loss_fake_score: 1.1524645 g_loss_score: 0.5099684
d_loss_real_score: 0.16345036 d_loss_fake_score: 1.5948453 g_loss_score: 0.5373781
d_loss_real_score: 0.1475666 d_loss_fake_score: 1.2713983 g_loss_score: 0.51444435
d_loss_real_score: 0.17351137 d_loss_fake_score: 1.1338599 g_loss_score: 0.7301729
d_loss_real_score: 0.12107799 d_loss_fake_score: 0.9817743 g_loss_score: 0.7752229
d_loss_real_score: 0.12992385 d_loss_fake_score: 1.1377401 g_loss_score: 0.65125465
d_loss_real_score: 0.14500132 d_loss_fake_score: 0.85776067 g_loss_score: 0.63272965
d_loss_real_score: 0.1726664 d_loss_fake_score: 1.2968346 g_loss_score: 0.4672717
d_loss_real_score: 0.14200068 d_loss_fake_score: 1.4019428 g_loss_score: 0.69508415
d_loss_real_score: 0.24906155 d_loss_fake_score: 1.2168552 g_loss_score: 0.67364794
d_loss_real_score: 0.2570397 d_loss_fake_score: 1.348511 g_loss_score: 0.69837403
d_loss_real_score: 0.1343627 d_loss_fake_score: 2.0440807 g_loss_score: 0.2968853
d_loss_real_score: 0.11864927 d_loss_fake_score: 1.5990115 g_loss_score: 0.43185428
d_loss_real_score: 0.30447534 d_loss_fake_score: 1.0530123 g_loss_score: 0.77764946
d_loss_real_score: 0.24258098 d_loss_fake_score: 1.0120606 g_loss_score: 0.7569509
d_loss_real_score: 0.15668884 d_loss_fake_score: 1.3991141 g_loss_score: 0.49122104
d_loss_real_score: 0.32325232 d_loss_fake_score: 1.0473862 g_loss_score: 0.67378175
d_loss_real_score: 0.22706848 d_loss_fake_score: 1.2807939 g_loss_score: 0.41881984
d_loss_real_score: 0.1897703 d_loss_fake_score: 1.3935777 g_loss_score: 0.41360736
d_loss_real_score: 0.23643516 d_loss_fake_score: 1.4275017 g_loss_score: 0.37375247
d_loss_real_score: 0.2921086 d_loss_fake_score: 1.0195407 g_loss_score: 0.68123436
d_loss_real_score: 0.245147 d_loss_fake_score: 1.2747333 g_loss_score: 0.42193103后续计划。
由于可以预见,未来的学习过程中必然将大量实验不同的模型。
我决定抛弃一改模型就不能恢复参数的tensorflow,改用pytorch重现代码。
-------------------------
19.03.11更新
出线之后断了一下。继续努力哦。
早上定了闹钟起来写记录。
昨晚熬到半夜,用pytorch改写了原代码。
尝试复现ResNet,但是失败了。
应该是我代码有问题。
1.用imagefolder读入的数据,好像是 channel x size x size。
2.读入过程,需要对像素需要做transform处理,这个处理我又不知道它是怎么做,会不会把原来3通道的打散了。需要研究transform的工作机制。
3.G最后tanh()一下生成(-1,1)的数据,如果保存的时候如果用utils.save_image( ,range=(-1,1)),好像可以,但是我不清楚原理。
4.之所以对3表示困惑,因为直接x.data.numpy(),然后丢给plt.imshow()是一片黑。这是当然的,因为数据是-1,1嘛。
可是x=x*127.5+127.5,再去plt.show()还是错的,那我就迷茫了。
5.引入cv2之后,用cv2.imwrite( x.data.numpy() ) 会各种各样的报错,至少2种吧。cv2里面对img的格式要求似乎是 size x size x channel,这就很过分了。
6.目前没有找到合适的方法把 channel x size x size变成 size x size x channel。 直接用Tensor.view()会打散数据吧,结果肯定失真,保存出来也是一片黑。
综上所述。torch复现ResNet失败,而且我对几个超参数还有疑问,实际跑起来似乎参数更新的超级慢。
于是我就把旧模型的pytorch改写版本放上去跑了。
加了Conv层数,增大batch_size,改小学习速率。

效果可以看到,比tensorflow上的第一次运行要精致许多。
1.色彩更丰富了,头发有明显的高光渐变阴影
2.人物脸型基本准确。
缺点是:
1.眼睛还是形状定不好。
2.为什么还是灰蒙蒙的啊!(手动挠头) 真的不懂颜色这回事。
关于loss。
我看着loss数据的变动,突然心有明悟。
似乎dloss一直降低到一个区间后波动,然后gloss曲折增加才是正常的。
随着d训练的越来越好,g会越来越不知道怎么去更新梯度。
后续计划:
1.之后要二战,大概会花更多时间补专业课基础。
2.再去找一份ResNet的实现方案看看代码思路是哪里不对。
3.今年ICML差不多有消息了吧,如果条件允许,可以直接上stateoftheart的模型。
------
update 3.12
1.已经探明图片读取尺寸机制。
torchvision.dataset.imagefolder读取的时候,自带一个transformer 类,torchvision.transforms.ToTensor()
会把读入的np.ndarray 【height x width x channel】,变成torch.tensor 【channel x height x width】
而cv2.imread()读入的图片是【height x width xchannel】的np.ndarray类型
其他常用函数写在这里了
Pytorch torchvision.transforms小结
2.弄懂了ResNet复现失败的原因。
一个是上面说的图片尺寸问题。
另一个是transform.ToTensor()自带一个scaling的效果,我在normalize()的时候不用再 x/127.5 -1,应该用x*2-1。
可以之后找个时间改一下,跑个ResNet50的分类任务出来。
3.看完昨天买的书之后我差点晕过去。
上面写着......
跑完15个epoch之后效果就很不错了,再跑下去也不会更好。
原来不会更好啦......枉我苦苦等个几百次。
然后看了几个别人的作业效果,貌似也是一次batch的output里,就几张可以看的。
歪歪扭扭的情况也是普遍存在的。
是model本身有问题,除非上更大的算力,加层数,加batch......
也就是说我的结果已经足够交李宏毅教授的作业了。
尝试去做做别的任务。