优化算法的选择(附执行代码)
文章目录
- 知识准备--指数加权平均
- 1.SGD
- 2.Momentum
- 3.AdaGrad
- 4.RMSProp
- 5.Adam
- 梯度更新算法的选择
- Learning rate decay
- 局部最优 local optima
知识准备–指数加权平均
本处参考:吴恩达的深度学习课程
梯度更新的算法理解都要用到指数加权平均,所以这里我们首先介绍下指数加权平均。关于每种更新算法的详解后续再做更新,先把框架搭好~
加权平均的公式
v t = β ∗ v t − 1 + ( 1 − β ) ∗ θ t v_t = \beta * v_{t-1} + (1-\beta)*{\theta_t} vt=β∗vt−1+(1−β)∗θt
我们称 v t v_t vt为滑动平均值,我们以每日温度为例,今日的滑动平均值等于昨天的滑动平均值的 β \beta β倍加上近日气温的 ( 1 − β ) (1-\beta) (1−β)倍
首先考虑 β \beta β = 0.98,那么滑动平均值相当于当天的气温占比为0.02, 1 0.02 = 50 \frac{1}{0.02} = 50 0.021=50 相当于50天的平均。
上述计算方式是因为权值如果小于 1 e \frac{1}{e} e1可以忽略不计,因而我们只需要证明 β 1 1 − β = 1 e \beta^{\frac{1}{1-\beta}} = \frac{1}{e} β1−β1=e1
令 1 1 − β = N \frac{1}{1-\beta} = N 1−β1=N β = 1 − 1 N \beta = {1-\frac{1}{N}} β=1−N1
只需证明 ( 1 − 1 N ) N = 1 e {(1-\frac{1}{N})^{N}} = \frac{1}{e} (1−N1)N=e1
利用在n趋于无穷时, ( 1 + 1 n ) n 等 于 e (1 + \frac{1}{n})^{n}等于e (1+n1)n等于e
下图红线表示的是 β = 0.9 \beta = 0.9 β=0.9也就是平均10天,而绿线表示 β = 0.98 \beta = 0.98 β=0.98相当于平均50天。
绿色的曲线要平坦一些,原因在于多平均了几天的温度,所以这个曲线,波动更小,更加平坦。缺点是曲线进一步右移,因为现在平均的温度值更多,要平均更多的值,指数加权平均公式在温度变化时,适应地更缓慢一些,所以会出现一定延迟。相当于给前一天的值加了太多权重,只有0.02的权重给了当日的值,所以温度变化时,温度上下起伏,当 β \beta β较大时,指数加权平均值适应地更缓慢一些。
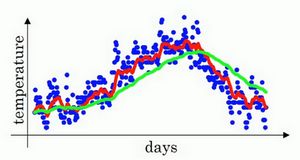
我们考虑第100天的滑动平均值
v 100 = 0.1 ∗ θ 100 + 0.9 ∗ ( 0.1 ∗ θ 99 + 0.9 ∗ v 98 ) v_{100} = 0.1*\theta_{100} + 0.9*( 0.1*\theta_{99}+0.9*v_{98} ) v100=0.1∗θ100+0.9∗(0.1∗θ99+0.9∗v98)
最后可以推导出 v 100 = 0.1 ∗ θ 100 + 0.1 ∗ 0.9 ∗ θ 99 + 0.1 ∗ 0.9 ∗ 0.9 ∗ θ 98 + . . . v_{100} = 0.1*\theta_{100} + 0.1*0.9*\theta_{99} + 0.1*0.9*0.9*\theta_{98} + ... v100=0.1∗θ100+0.1∗0.9∗θ99+0.1∗0.9∗0.9∗θ98+...
然后我们构建一个指数衰减函数,从 0.1 0.1 0.1开始,到 0.1 ∗ 0.9 0.1*0.9 0.1∗0.9,到 0.1 ∗ 0.9 ∗ 0.9 0.1*0.9*0.9 0.1∗0.9∗0.9,以此类推。假设 β = 0.9 \beta = 0.9 β=0.9, 0.9 10 {0.9}^{10} 0.910约为0.35,约等于 1 e \frac{1}{e} e1,也就是说约10天后,衰减到初始权值的 1 3 \frac{1}{3} 31,如果 β \beta β = 0.98,则需要约50天也就是 0.98 50 {0.98}^{50} 0.9850到大概 1 e \frac{1}{e} e1
另外,考虑到初始 v 0 v_{0} v0 = 0,所以初始的滑动平均值会有很大的误差,因而会考虑使用 v t 1 − β t \frac{v_t}{1-\beta_t} 1−βtvt 来代替 v t v_t vt,这种方法称为指数加权平均偏差修正。
指数加权平均的主要好处是:占用内存少,只占用一行代码,当然它并不是最精准的计算平均数的方法。
1.SGD
上文我们构建模型采用的梯度更新算法是SGD
W = W − η ∂ ( L ) ∂ ( W ) W =W-\eta{\frac{\partial(L)}{\partial(W)}} W=W−η∂(W)∂(L)
η 是 学 习 率 \eta是学习率 η是学习率
由于很多情况下,梯度的方向并不指向最小值的方向,所以SGD算法比较低效.
以下是SGD的更新代码,输入学习率和梯度,参数用字典params
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
2.Momentum
Momentum算法又叫做动量梯度下降法,运行速度几乎总是快于标准的梯度下降算法。它的基本想法就是计算梯度的指数加权平均值,并利用该梯度更新权重。
υ = α υ − η ∂ ( L ) ∂ ( W ) \upsilon = \alpha\upsilon - \eta{\frac{\partial(L)}{\partial(W)}} υ=αυ−η∂(W)∂(L)
W = W + υ W = W + \upsilon W=W+υ
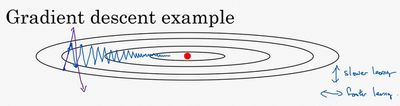
下面来理解下这种算法,如下图,红点表示我们想要达到的最低点,在纵轴上,我们希望学习率小一点,而横轴,我们希望快一点达到最小值点。即横轴梯度加快一点,纵轴梯度减低一点减少不必要的震荡。
这里我们计算下式,其中 θ \theta θ表示当前的梯度,然后用该平均值对权值做更新,这样纵轴梯度在平均过程中,正负数容易相互抵消,而由于所有的微分都指向横轴,所有横轴平均值仍较大。
v = β ∗ v + ( 1 − β ) ∗ θ v = \beta*v + (1-\beta)*\theta v=β∗v+(1−β)∗θ
详细优化算法如下:

最后,很多资料会选择去掉去掉 ( 1 − β ) (1-\beta) (1−β)得到
v = β ∗ v + θ v = \beta*v +\theta v=β∗v+θ
在吴恩达的课程中,上述两种方法效果都比较好,但吴本人倾向于不省略 1 − β 1-\beta 1−β。
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val) # 初始化,每个v与参数的维度相同
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
3.AdaGrad
学习率的选择十分重要,学习率过小,导致学习花费很多时间,学习率过大导致学习发散不能收敛。因而有一种技巧叫学习率衰减,随着学习的进行,逐渐减小学习率。AdaGrad会为参数的每个元素适当的调整学习率。
h = h + ∂ ( L ) ∂ ( W ) ⊙ ∂ ( L ) ∂ ( W ) h = h +{\frac{\partial(L)}{\partial(W)}}\odot{\frac{\partial(L)}{\partial(W)}} h=h+∂(W)∂(L)⊙∂(W)∂(L)
W = W − η 1 h ∂ ( L ) ∂ ( W ) W = W - \eta\frac{1}{\sqrt{h}}{\frac{\partial(L)}{\partial(W)}} W=W−ηh1∂(W)∂(L)
⊙ \odot ⊙表示对应矩阵元素的乘法,变量 h h h保存了所有梯度的平方和
在更新参数时乘以 1 h \frac{1}{\sqrt{h}} h1,就可以调整学习的尺度,这意味参数元素中变动较大的元素学习率将变小。
AdaGrad代码如下,与Momentum代码类似。
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += + grads[key] * grads[key]
params[key] -= self.lr / (np.sqrt(self.h[key]) + 1e-7) * grads[key]
4.RMSProp
AdaGrad会记录过去所有梯度的平方和,随着学习深入,更新的幅度就越小,RMSProp为了改善这个问题,并不会将过去所有的梯度一视同仁的相加,而是逐渐遗忘过去的梯度,将新的梯度更多的反映出来,这种方法称为指数移动平均的记录。更新的参数W和b的表达式如下
S W = β ∗ S d W + ( 1 − β ) ∗ ( d W ) 2 S_W = \beta*S_{dW} + (1-\beta)*(dW)^2 SW=β∗SdW+(1−β)∗(dW)2
S b = β ∗ S d b + ( 1 − β ) ∗ ( d b ) 2 S_b = \beta*S_{db} + (1-\beta)*(db)^2 Sb=β∗Sdb+(1−β)∗(db)2
W : = W − α ∗ d W S W + ε , b : = b − α ∗ d b S b + ε W :=W-\alpha*\frac{dW}{\sqrt{S_W}+\varepsilon}, b :=b - \alpha*\frac{db}{\sqrt{S_b}+\varepsilon} W:=W−α∗SW+εdW,b:=b−α∗Sb+εdb
ε = 1 0 − 8 , 目 的 是 防 止 被 除 数 为 0 \varepsilon = 10^{-8},目的是防止被除数为0 ε=10−8,目的是防止被除数为0

以上图为例,假设横向为w,纵向为b,横向震荡较小,而纵向震动较大,表现为梯度w方向梯度较小,b方向梯度较大,在更新梯度的表达式中 d W S W \frac{dW}{\sqrt{S_W}} SWdW较大,而 d b S b \frac{db}{\sqrt{S_b}} Sbdb较小,即加快了w方向的速度,减小了b方向的速度
5.Adam
Adam直观来讲,融合了Momentum和AdaGrad的方法。Adam会设置3个超参数。学习率 α \alpha α、一次momentum系数 β 1 \beta_1 β1和二次动量系数 β 2 \beta_2 β2。 β 1 \beta_1 β1通常设置为0.9, β 2 \beta_2 β2设置为0.99。
方法一:
l r = l r ∗ 1 − β 2 i 1 − β 1 i lr = lr * \frac{\sqrt{1-\beta_2^i}}{1-\beta_1^i} lr=lr∗1−β1i1−β2i
m = m + ( 1 − β 1 ) ( ∂ ( L ) ∂ ( W ) − m ) m = m + (1-\beta_1)({\frac{\partial(L)}{\partial(W)}} - m) m=m+(1−β1)(∂(W)∂(L)−m)
v = v + ( 1 − β 2 ) ( ( ∂ ( L ) ∂ ( W ) ) 2 − v ) v = v + (1-\beta_2)({(\frac{\partial(L)}{\partial(W)}})^{2} - v) v=v+(1−β2)((∂(W)∂(L))2−v)
W = W − m v + ε W = W - \frac{m}{\sqrt{v} + \varepsilon} W=W−v+εm
代码如下
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
(NG)方法二:
V d W = β 1 V d W + ( 1 − β 1 ) d W , V d b = β 1 V d b + ( 1 − β 1 ) d b V_{dW} = \beta_1 V_{dW} + (1-\beta_1) dW, V_{db} = \beta_1 V_{db} + (1-\beta_1) db VdW=β1VdW+(1−β1)dW,Vdb=β1Vdb+(1−β1)db
S d W = β 2 S d W + ( 1 − β 2 ) d W 2 , S d b = β 2 S d b + ( 1 − β 2 ) d b 2 S_{dW} = \beta_2S_{dW} + (1-\beta_2) dW^{2},S_{db} = \beta_2S_{db} + (1-\beta_2) db^{2} SdW=β2SdW+(1−β2)dW2,Sdb=β2Sdb+(1−β2)db2
V d W c o r r e c t = V d W 1 − β 1 t , V d b c o r r e c t = V d b 1 − β 1 t V_{dW}^{correct} = \frac{V_{dW}}{1-\beta_1^t},V_{db}^{correct} = \frac{V_{db}}{1-\beta_1^t} VdWcorrect=1−β1tVdW,Vdbcorrect=1−β1tVdb
S d W c o r r e c t = S d W 1 − β 2 t , S d b c o r r e c t = S d b 1 − β 2 t S_{dW}^{correct} = \frac{S_{dW}}{1-\beta_2^t},S_{db}^{correct} = \frac{S_{db}}{1-\beta_2^t} SdWcorrect=1−β2tSdW,Sdbcorrect=1−β2tSdb
以上标准化在有的代码中并未体现
W : = W − α V d W c o r r e c t S d W c o r r e c t + ε , b : = b − α V d b c o r r e c t S d b c o r r e c t + ε W :=W-\alpha\frac{V_{dW}^{correct}}{\sqrt{S_{dW}^{correct}+ \varepsilon}}, b :=b - \alpha\frac{V_{db}^{correct}}{\sqrt{S_{db}^{correct}+\varepsilon}} W:=W−αSdWcorrect+εVdWcorrect,b:=b−αSdbcorrect+εVdbcorrect
实际应用中,Adam算法结合了动量梯度下降和RMSP,使得神经网络训练的速度大大加快。
附上keras的adam的代码实现 Keras Adam代码解析
目前Adam基础之上的还有Amsadam等算法,后续有时间更一下。
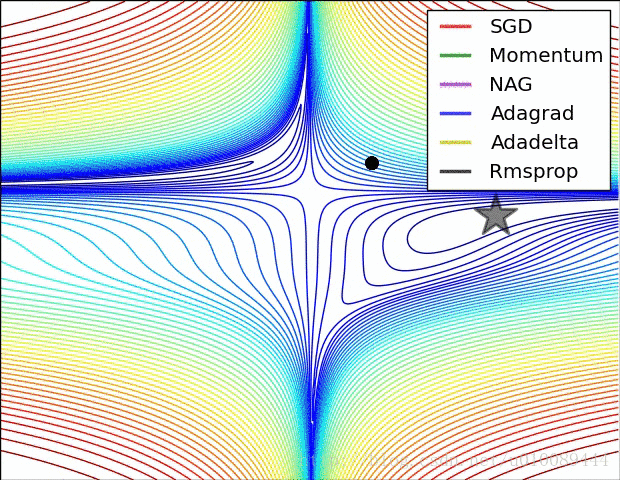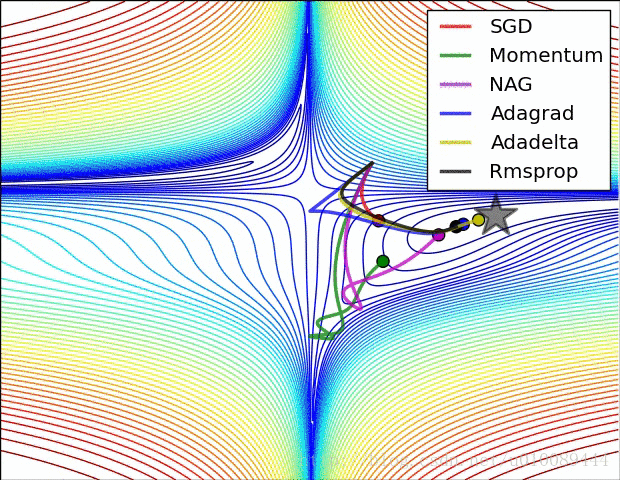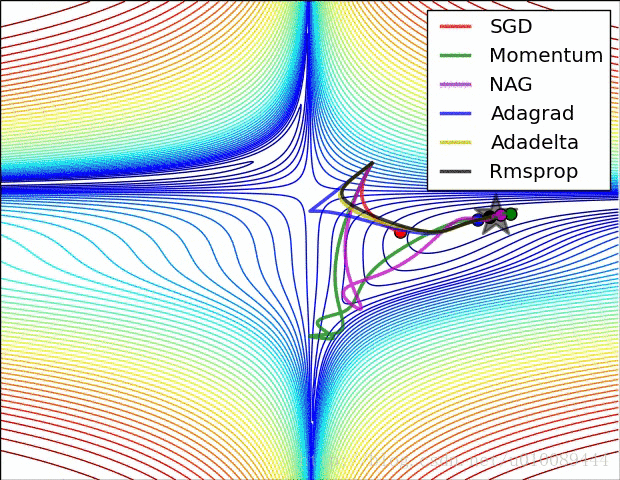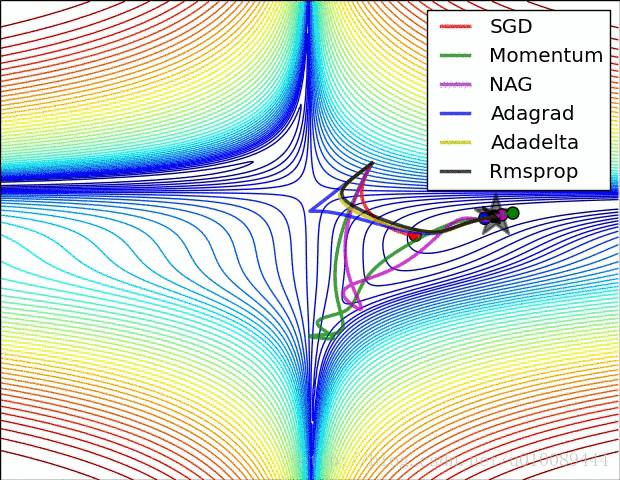
梯度更新算法的选择
事实上,并不存在能在所有问题都表现良好的方法,以上方法各有各的特点,各有各自擅长解决的问题和不擅长解决的问题。
关于集中梯度更新方法的图像展示如下

Learning rate decay
学习因子 α \alpha α的减小也能有效提高神经网络迭代速度,这种方法称为learning rate decay.
随着迭代次数增加,学习因子逐渐减小,下图蓝线表示恒定的学习因子,绿线表示衰减的学习因子。可以看到,衰减的学习因子可以避免训练时在最小值附近震荡
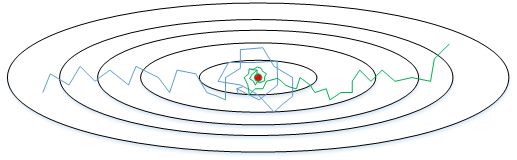
关于 α \alpha α常用的有以下几种
α = 1 1 + d e c a y ∗ e p o c h α 0 \alpha = \frac{1}{1+decay*epoch}\alpha_0 α=1+decay∗epoch1α0
其中decay是衰退率,可以调节,epoch是训练全部样本的次数,随着epoch增加 α \alpha α逐渐减小
α = 0.9 5 e p o c h ∗ α 0 \alpha = 0.95^{epoch}*\alpha_0 α=0.95epoch∗α0
α = k e p o c h ∗ α 0 o r k t ∗ α 0 \alpha = \frac{k}{\sqrt{epoch}}*\alpha_0 or \frac{k}{\sqrt{t}}*\alpha_0 α=epochk∗α0ortk∗α0
其中k为可调参数,t为mini-batch number
此外还可以设置 α \alpha α为离散值。
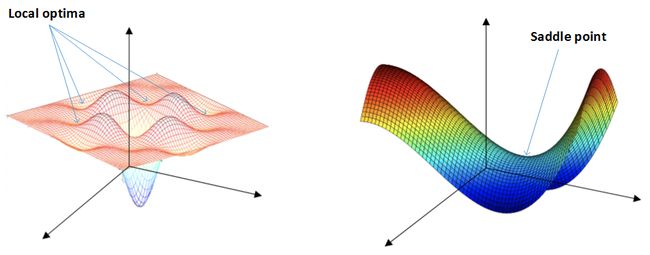
局部最优 local optima
图一类似的local optima会降低神经网络学习速度。然而高维度空间的局部最优的可能性会十分低,比如一个2万维空间,如果想取到局部最优,所有两万个方向都是局部最优,可能性大约是 2 − 20000 2^{-20000} 2−20000
然而类似马鞍的曲线是训练的一个很大的瓶颈,这种平稳的段会减缓学习,导数长时间解决于0。
总的来说,只要选择合理的神经网络,一般不太可能陷入local optima;plateaus可能会使梯度下降变慢,降低学习速度。
本文参考
Coursera吴恩达《优化深度神经网络》课程笔记(2)
第二周:优化算法 (Optimization algorithms)
附一张图总结一下

有错误可以指出,大家一起进步~