『Python』快速复盘【泰坦尼克获救预测分析】·动手学数据分析(未完待续)
半年前为了学习机器学习的分类模型,首次写下这篇博客泰坦尼克获救预测分析,如今为了巩固python分析基础(提醒自己基础熟练的重要性!!!),还有分享如何快速“动手学数据分析”,快速复盘这个案例。
Python数据分析流程
- 一、数据基本操作
- 1.数据加载
- 1.1载入数据
- 1.2初步观察
- 1.3保存数据
- 2.Pandas基础
- 2.1认识Pandas中两数据结构:DateFrame和Series
- 2.2查看数据
- 2.2数据筛选
- 3.探索性数据分析
- 3.1利用Pandas-describe()函数查看数据基本统计信息
- 3.2利用Pandas对示例数据进行排序,要求升序
- 3.3利用Pandas进行算术计算,计算两个DataFrame数据相加结果
- 二、数据清洗与重构
- 1.数据清洗及特征处理
- 1.1缺失值观察
- 1.2缺失值处理
- 1.3重复值观察与处理
- 1.4特征观察与处理
- 2.数据重构1
- 2.1数据的合并
- 2.2
- 3.数据重构2
- 三级目录
- 4.数据可视化
- 三级目录
- 三、建模和评估
- 二级目录
- 三级目录
一、数据基本操作
1.数据加载
1.1载入数据
数据集下载: https://www.kaggle.com/c/titanic/overview
1.1.1 导基本包
![]()
1.1.2 导数据
(1) 使用相对路径载入数据
(2) 使用绝对路径载入数据
也可以把地址赋给一个变量,之后引用这个变量即可。


备注:电脑是Mac系统,我得到绝对地址的方法是:把文件直接拖拽到终端里,自动会显示此文件的绝对地址。
1.1.3每1000行为一个数据模块,逐块读取文件
![]()
问题:什么是逐块读取?
答案:利用chunksize参数,来控制每次块数据的大小。它的本质就是将文本分成若干块。其实,每次进行迭代的时候还是一个DataFrame类型的数据结构。
问题:为什么要逐块读取呢?
答案:使用pandas来处理文件的时候,经常会遇到大文件,而有时候我们只想要读取其中的一部分数据,这时对文件进行逐块处理。
1.1.4将表头改为中文,索引改为乘客id
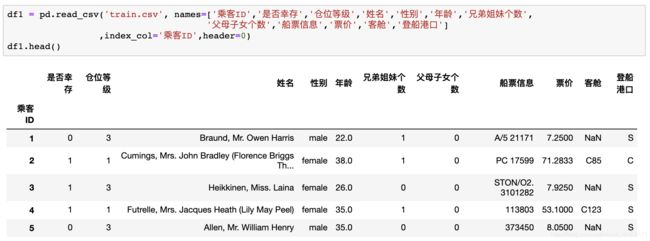

1.2初步观察
1.2.1查看数据的基本信息

1.2.2观察表格前10行的数据和后15行的数据


1.2.3判断数据是否为空,为空的地方返回True,其余地方返回False

量化一下:

1.3保存数据
将你加载并作出改变的数据,在工作目录下保存为一个新的文件train_chinese.csv
![]()
2.Pandas基础
2.1认识Pandas中两数据结构:DateFrame和Series


总结:
1、Series是一种类似于一维数组的对象。它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。Series只有行索引。
2、DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共同用一个索引)。
3、dataframe类型的每一列都是Series类型。
2.2查看数据
2.2.1加载上面保存的"train_chinese.csv"文件。

2.2.2查看数据的某列的所有项

注意:取值时用[]包含才是dataframe,否则取出来就是Series
2.2.3删除某些列
①del df[]
②df.drop([],axis = 1)
#方法一
del test_df['某一列']
#方法二
test_df.drop(['乘客ID','姓名','年龄','票价'],axis=1)
2.2数据筛选
表格数据中,最重要的一个功能就是要具有可筛选的能力,选出我所需要的信息,丢弃无用的信息。 用实战来学习pandas这个功能。
2.3.1 以‘age’为筛选条件,显示年龄在10岁以下的乘客信息

2.3.2以‘Age’为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage

Ps:小心标注的符号吼!!!
2.3.3数值筛选

原本是这样的,如果想要按索引筛选,需要重置索引。



总结:loc和iloc的区别:
loc:只能通过选取行标签索引数据;
iloc:只能通过选取行位置编号索引数据。
3.探索性数据分析
3.1利用Pandas-describe()函数查看数据基本统计信息

说明:
·count : 样本数据大小
·mean : 样本数据的平均值
·std : 样本数据的标准差
·min : 样本数据的最小值
·25% : 样本数据25%的时候的值
·50% : 样本数据50%的时候的值
·75% : 样本数据75%的时候的值
·max : 样本数据的最大值
分析:
仅对于票价分析
一共有891个票价数据,
平均值约为:32.20,
标准差约为49.69,说明票价波动特别大, 25%的人的票价是低于7.91的,50%的人的票价低于14.45,75%的人的票价低于31.00, 票价最大值约为512.33,最小值为0。
3.2利用Pandas对示例数据进行排序,要求升序

代码解析:
pd.DataFrame() :创建一个DataFrame对象
np.arange(8).reshape((2, 4)) : 生成一个二维数组(2*4),第一列:0,1,2,3 第二列:4,5,6,7
index=['2, 1] :DataFrame 对象的索引列
columns=[‘d’, ‘a’, ‘b’, ‘c’] :DataFrame 对象的索引行

sort_values这个函数中by参数指向要排列的列,ascending参数指向排序的方式(升序还是降序)
排序总结:
·让行索引升序排序 df.sort_index()
·让列索引升序排序df.sort_index(axis = 1)
·让列索引降序排序df.sort_index(axis= 1,ascending = True)
·任选两列数据进行排序 df.sort_values(by = [])
3.2.1对泰坦尼克号数据(trian.csv)按票价和年龄两列进行综合排序(降序排列)


分析:排序后,如果我们仅仅关注年龄和票价两列。根据常识知道发现票价越高,客舱越好,所以明显看出,票价前10中有8位幸存,票价后15中(除去Null和0)仅仅有1人幸存。
我们后面可以进一步分析一下 票价和存活之间的关系,年龄和存活之间的关系。
3.3利用Pandas进行算术计算,计算两个DataFrame数据相加结果



说明:两个DataFrame相加后,会返回一个新的DataFrame,对应的行和列的值会相加,没有对应的会变成空值 NaN。
3.3.1计算出船上最大的家族有多少人?
最大的家族计算公式=兄弟姐妹个数+父母子女个数

算完没有用的话,请删除

二、数据清洗与重构
我们拿到的数据通常是不干净的,所谓的不干净,就是数据中有缺失值,有一些异常点等,需要经过一定的处理才能继续做后面的分析或建模,所以拿到数据的第一步是进行数据清洗,我们将从缺失值、重复值、字符串和数据转换等操作,将数据清洗成可以分析或建模的形式。
1.数据清洗及特征处理
1.1缺失值观察
1.1.1查看每个特征缺失值个数,有两种方法:

1.1.2查看Age, Cabin, Embarked列的数据
1.2缺失值处理
两种处理办法
1.2.1 删除缺失值


1.2.2 填充缺失值


总结:
fillna()和dropna()默认会返回一个替换后的新对象,不改变源数据,这个时候将替换后的数据赋值给新的表,如果要改变源数据,通过传入inplace=True进行更改。
1.3重复值观察与处理
1.3.1查看数据中的重复值

1.3.2处理数据中的重复值
对于重复值我们一般是进行删除处理,使用的方法是drop_duplicates()。

![]()
1.4特征观察与处理
我们对特征进行一下观察,可以把特征大概分为两大类:
数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare,其中Survived, Pclass为离散型数值特征,Age, SibSp, Parch, Fare为连续型数值特征
文本型特征:Name, Sex, Cabin,Embarked, Ticket,其中Sex, Cabin, Embarked, Ticket为类别型文本特征。
数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性(一些异常情况下它的效果能否继续相对稳定)会对连续变量进行离散化。文本
型特征往往需要转换成数值型特征才能用于建模分析。
1.4.1 [数值型特征] 对年龄进行分箱(离散化)处理


1.4.2 [文本型特征] 对文本变量进行查看
- 方法一:value_counts()

- 方法二:unique()和nunique()

1.4.3 [文本型特征] 对文本变量进行转换
1、将文本变量Sex, Cabin ,Embarked用数值变量12345表示
-
方法一:replace

-
方法二:map

-
方法三:使用sklearn.preprocessing的LabelEncoder

2、将文本变量Sex, Cabin, Embarked用one-hot编码表示

1.4.4 从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)

知识拓展1:pandas中字符数据的处理方法:
Series.str.extract(pat, flags=0, expand=None)
pat : 字符串或正则表达式
flags : 整型,
expand : 布尔型,是否返回DataFrame
知识拓展2:正则表达式’([A-Za-z]+).’
[A-Za-z]+:由26个字母组成的字符串。
[]:字符集,一个字符的集合,可匹配其中任意一个字符。
+:匹配前一个元字符1到多次。
\.:反斜杠后面接一个字符,表示匹配某种类型的一个字符。因为点是一个元字符,直接出现在正则表达式中,表示匹配任意的单字符,不能表示.这个字符本身的意思了。如果我们要搜索的内容本身就包含元字符,就可以使用反斜杠进行转义。
\s: 匹配任意一个空白字符,包括 空格,tab,换行符等。
\S: 匹配任意一个非空白字符。


2.数据重构1
2.1数据的合并
- 使用pandas的concat方法

- 使用DataFrame自带的join和append方法

- 使用pandas自带的merge和append方法

总结:
1、merge、join只能横向合并数据,concat可以横向也可以纵向合并数据。