动手学数据分析——第一天
动手学数据分析——第一天
文章目录
- 动手学数据分析——第一天
- 一.数据加载
- **1.导入numpy、pandas包**
- 2.载入数据
- 3.修改表头并保存
- 4.初步观察
- 6.观察数据
- 7.保存数据
- 二.pandas基础
- 1.DateFrame和Series类型
- 2.载人'train.csv'并进行相关操作
- 3.筛选的逻辑
- 三.探索性数据分析
- 1.对数据进行排序
- 2.算术计算
- 3.用describe()函数查看信息
一.数据加载
加粗样式数据集下载 https://www.kaggle.com/c/titanic/overview
1.导入numpy、pandas包
import numpy as np
import pandas as pd
2.载入数据
##这里用相对路径进行数据的载人,也可以用绝对路径的方式进行载人
df = ps.read_csv('train.csv')
df.head(4)

如果数据过大可以逐块读取
chunker = pd.read_csv(‘train.csv’, chunksize=1000)
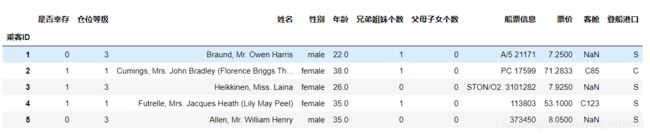
3.修改表头并保存
df = pd.read_csv('train.csv',names=['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息',
'票价','客舱','登船港口'],index_col='乘客ID',header=0)
df.head()
4.初步观察
df.info()

6.观察数据
前后数据
#前10条数据
df.head(10)
#后10条数据
df.tail(10)
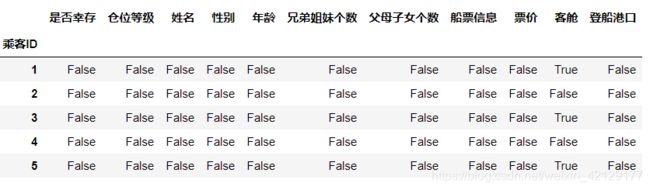
查看空信息
#为空的返回True,否则返回False
df.isnull().head()
7.保存数据
#将数据保存在当前目录下并命名为‘train_chinese.csv’
df.to_csv('train_chinese.csv')
二.pandas基础
1.DateFrame和Series类型
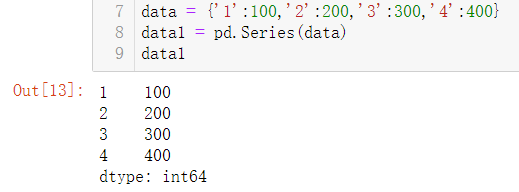
创建一个series
data = {'1':100,'2':200,'3':300,'4':400}
data1 = pd.Series(data)
data1
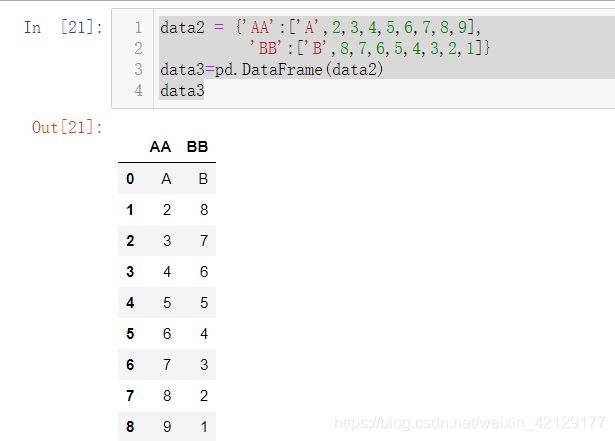
创建一个DataFrame
data2 = {'AA':['A',2,3,4,5,6,7,8,9],
'BB':['B',8,7,6,5,4,3,2,1]}
data3=pd.DataFrame(data2)
data3
2.载人’train.csv’并进行相关操作
载人数据
#载人‘train.csv'’文件
df = pd.read_csv('train.csv')
df.head(4)

查看DataFrame数据的每列的项
df.columns

查看相关的列的所有项
df['Cabin']

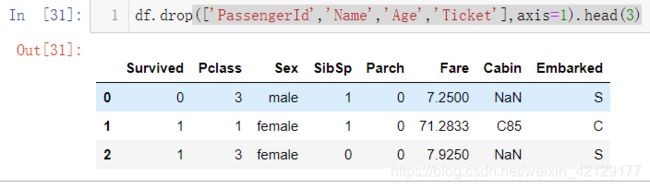
将不相关的这几个列元素隐藏,方便观察想看的几个列元素
df.drop(['PassengerId','Name','Age','Ticket'],axis=1).head(3)
3.筛选的逻辑
数据筛选
# 筛选出Age小于10的数据
df[df.Age<10].head(3)
#
筛选出Age大于10并且小于50的数据
midage = df[(df.Age>10) & (df.Age<50)]
三.探索性数据分析
1.对数据进行排序
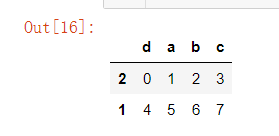
创建一个DataFrame
frame = pd.DataFrame(np.arange(8).reshape((2,4)),
index=['2','1'],
columns=['d','a','b','c'])
frame
#将DataFrame中的数据根据某一列,降序排列
frame.sort_values(by='c',ascending=False)

让 行 索引升序排序
frame.sort_index()
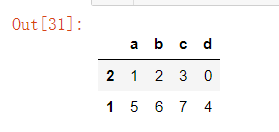
让列索引降序排序
frame.sort_index(axis=1,ascending=False)

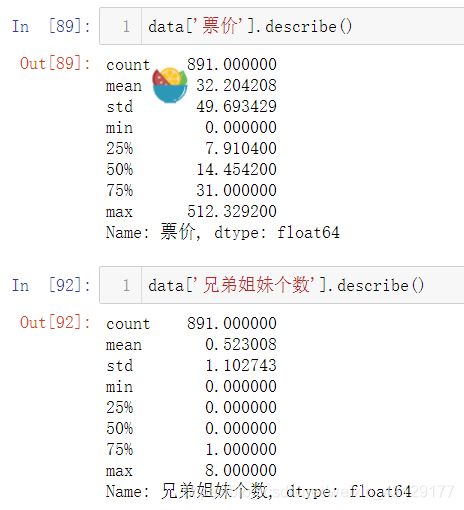
按票价和年龄两列进行综合排序(降序排列)
data.sort_values(by=['票价','年龄'],ascending=False).head(20)

2.算术计算
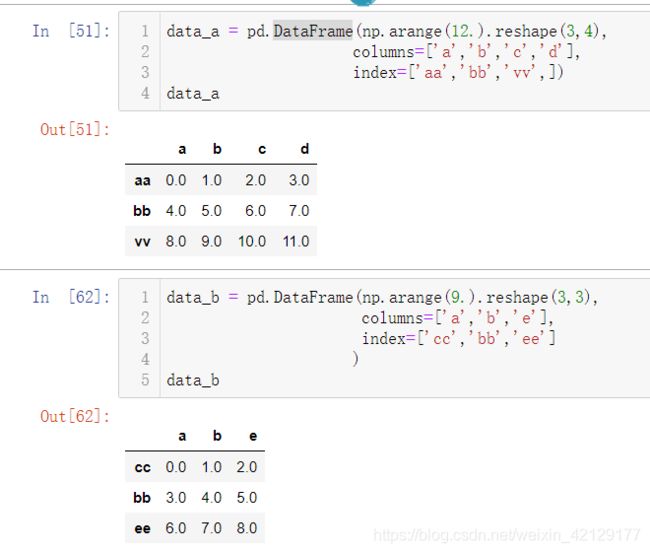
创建两个DataFrame,分别是data_a和data_b
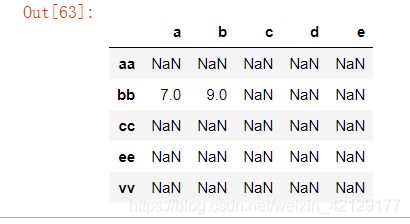
data_a 和 data_b 相加
data_a + data_b
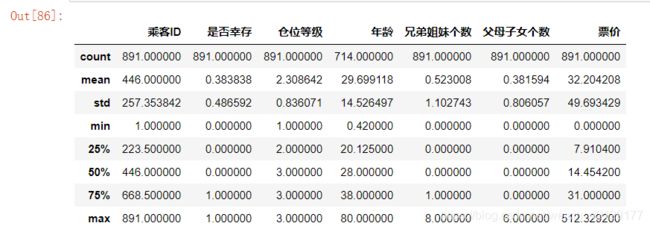
3.用describe()函数查看信息
查看数据所有的信息
data.describe()
'''
count : 样本数据大小
mean : 样本数据的平均值
std : 样本数据的标准差
min : 样本数据的最小值
25% : 样本数据25%的时候的值
50% : 样本数据50%的时候的值
75% : 样本数据75%的时候的值
max : 样本数据的最大值
'''
查看数据的一项信息