NLP --- 条件随机场CRF详解
上一节我们介绍了CRF的背景,本节开始进入CRF的正式的定义,简单来说条件随机场就是定义在隐马尔科夫过程的无向图模型,外加可观测符号X,这个X是整个可观测向量。而我们前面学习的HMM算法,默认可观测符号是独立的,但是根据我们的实际语言来说,独立性的假设太牵强,不符合我们的语言规则,因此在HMM的基础上,我们把可观测符号的独立性假设去掉。同时我们知道HMM的解法是通过期望最大化进行求解,而CRF是通过最大熵模型进行求解,下面我们就从定义开始看看什么是CRF:
CRF定义
这里定义只讲线性链随机场,针对自然语言处理领域的处理进行设计,因此这里只提线性链随机场定义:
线性链条件随机场)设![]() 均为线性链表示的随机变量序列,若在给定随机变量序列的条件下,随机变量序列Y的条件概率分布就构成条件随机场,即满足马尔可夫性
均为线性链表示的随机变量序列,若在给定随机变量序列的条件下,随机变量序列Y的条件概率分布就构成条件随机场,即满足马尔可夫性
![]()
则称![]() 为线性链条件随机场,在标注问题中,
为线性链条件随机场,在标注问题中,![]() 表示输入观测序列,
表示输入观测序列,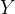 表示对应的输出标记序列或状态序列,这里大家一定要切记什么是概率图模型,什么是无向图和团,上面的定义就是针对二元组,如下图:
表示对应的输出标记序列或状态序列,这里大家一定要切记什么是概率图模型,什么是无向图和团,上面的定义就是针对二元组,如下图:
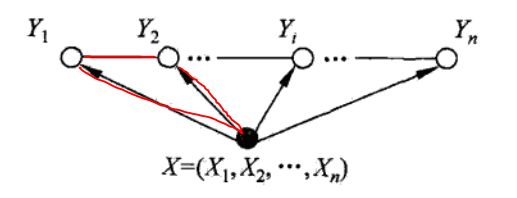
上面团就是![]() ,其他的Y不是这个团里的,那么对应的条件概率(这里以
,其他的Y不是这个团里的,那么对应的条件概率(这里以![]() 为例求解) 那么应该写成如下:
为例求解) 那么应该写成如下:
![]()
也就是说决定![]() 的概率取决于输入的序列
的概率取决于输入的序列![]() 以及和他相连的两个输出
以及和他相连的两个输出![]() ,,这正是体现了概率图模型里面的思想(符合语言的规律即联系上下文语意),不和其直接相连的可以看做条件独立,这就解释了下面为什么可以直接相乘,指数相加了,所以这里大家需要好好理解这里的深层含义,不要放过任何细节问题。下面我们给出参数化定义,上面的定义是我们语言模型最原始的出发点即知道输入的语音我如何求出对应的概率,这里需要数学模型来建立他们的关系,如下(这里大家看看上一节的什么是势函数,或者看李航的书):
,,这正是体现了概率图模型里面的思想(符合语言的规律即联系上下文语意),不和其直接相连的可以看做条件独立,这就解释了下面为什么可以直接相乘,指数相加了,所以这里大家需要好好理解这里的深层含义,不要放过任何细节问题。下面我们给出参数化定义,上面的定义是我们语言模型最原始的出发点即知道输入的语音我如何求出对应的概率,这里需要数学模型来建立他们的关系,如下(这里大家看看上一节的什么是势函数,或者看李航的书):
这里把上一节的重要公式拿过来:
最大团C上的函数![]() 的乘积形式
的乘积形式
![]()
概率无向图模型的联合概率分布![]() 的可以表示为如下形式:
的可以表示为如下形式:

其中 ![]()
定理 (线性链条件随机炀的参数化形式)设![]() 为线性链条件随机场,则在随机变量
为线性链条件随机场,则在随机变量![]() 取值为
取值为![]() 的条件下,随机变量Y取值为
的条件下,随机变量Y取值为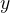 的条件概率具有如下形式:
的条件概率具有如下形式:
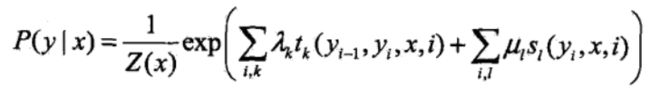
其中:
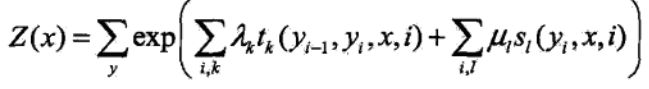
上面的定义其实就是根据势函数和概率无向图模型进行定义的,那么这些参数都代表什么意思呢?
大家这里可以把![]() 、
、![]() 看做权值,
看做权值,![]() 、
、![]() 看做特征函数,和我们最大熵模型里将的特征函数很类似可以说是一样了,即满足为1,反之为0,下面使用李航的书进行解释:
看做特征函数,和我们最大熵模型里将的特征函数很类似可以说是一样了,即满足为1,反之为0,下面使用李航的书进行解释:
上式是线性链条件随机场模型的基本形式,表示给定输入序列x,对输出序列,预测的条件概率,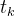 是定义在边上的特征函数,称为转移特征,依赖于当前和前一个位置,
是定义在边上的特征函数,称为转移特征,依赖于当前和前一个位置,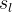 是定义在结点上的特征函数,称为状态特征,依赖于当前位置,和都依赖于位置,是局部特征函数,通常,特征函数和取值为1或0:当满足特征条件时取值为1,否则为0.条件随机场完全由特征函数和对应的
是定义在结点上的特征函数,称为状态特征,依赖于当前位置,和都依赖于位置,是局部特征函数,通常,特征函数和取值为1或0:当满足特征条件时取值为1,否则为0.条件随机场完全由特征函数和对应的![]() 、
、![]() 权值,确定.
权值,确定.
我们知道了上面的和分别代表什么了,而对于当前的位置状态只依赖于前一个状态,那可不可以扩展其他的依赖状态呢?例如依赖前两个的位置状态,答案是可行的,只是这里我们需要符合无向图最大团的定义,即任意两个都应该联通,如下图所示:

此时我们的就可以写成这样了:![]() ,这样大家应该可以理解条件随机场的工作方式的了,那么我们继续来看看上式的定义和上图,我们发现如果这样做的话会有哪些问题呢?首先特征函数如何定义呢?这里的定义是根据特征模板生成的,可以是一个子、一个词,或者一个短语等,这些特征不是人为划分而是通过计算机自动划分,这样做确实节省了人力,但是带来的问题是,无效特征也会急剧增加,例如“我爱中国”,这里面的特征可能包含‘我爱’,‘爱中’,‘中国’,其中‘爱中’就是无效特征,这样的词会很多,因此计算量就会很大,如何解这个问题,我们引入了权值即
,这样大家应该可以理解条件随机场的工作方式的了,那么我们继续来看看上式的定义和上图,我们发现如果这样做的话会有哪些问题呢?首先特征函数如何定义呢?这里的定义是根据特征模板生成的,可以是一个子、一个词,或者一个短语等,这些特征不是人为划分而是通过计算机自动划分,这样做确实节省了人力,但是带来的问题是,无效特征也会急剧增加,例如“我爱中国”,这里面的特征可能包含‘我爱’,‘爱中’,‘中国’,其中‘爱中’就是无效特征,这样的词会很多,因此计算量就会很大,如何解这个问题,我们引入了权值即![]() 、
、![]() ,通过权值我们就可以计算有效特征和无效特征的权值,这样权值会使的有效特征的权值很大,无效特征的权值几乎为0,这就是引入权值的目的,但是计算量大怎么解决呢?这一点我们在后面的学习算法中在仔细的讲,现在我们看看上式,我们发现他有两个特征函数两个权值,这样处理不是很方便,能不能把他们合二为一呢?答案是可以的,下面我们就详细的看看怎么做。
,通过权值我们就可以计算有效特征和无效特征的权值,这样权值会使的有效特征的权值很大,无效特征的权值几乎为0,这就是引入权值的目的,但是计算量大怎么解决呢?这一点我们在后面的学习算法中在仔细的讲,现在我们看看上式,我们发现他有两个特征函数两个权值,这样处理不是很方便,能不能把他们合二为一呢?答案是可以的,下面我们就详细的看看怎么做。
条件随机场的简化形式
条件随机场还可以由简化形式表示.注意到条件随机场式中同一特征在各个位置都有定义,可以对同一个特征在各个位置求和,将局部特征函数转化为一个全局特征函数,这样就可以将条件随机场写成权值向量和特征向量的内积形式,即条件随机场的简化形式,
为简便起见,首先将转移特征和状态特征及其权值用统一的符号表示.设有![]() 个转移特征,
个转移特征,![]() 个状态特征,
个状态特征,![]() ,记
,记

我们来解释一下为什么是可以合二为一,因为位置特征和状态特征的不同之处是位置只和当前位置有关和其他无关,而转移状态不仅和当前状态有关还和前一个状态有关,那么如果位置特征和加上前一个位置的特征,这里我们让前一个位置特征的权值为0就可以了,因此可以综合在一起,这里大家应该可以理解的,下面我们继续往下看:
对转移和位置状态对i进行求和:

使用![]() 代替
代替 ![]() 、
、![]() :
:

因此条件随机场的可以简化写成如下:

若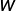 表示权值向量,则可以写成如下:
表示权值向量,则可以写成如下:
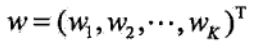
使用![]() 表示全局特征向量:
表示全局特征向量:
![]()
条件随机场可以写成向量的乘积的形式,如下:
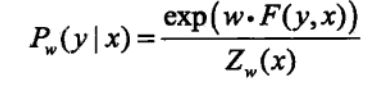
其中:
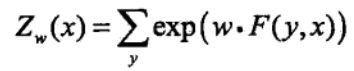
条件随机场的矩阵形式
根据(1)式我们可以写成矩阵的形式,对观测序列的每个位置![]() ,定义一个m阶矩阵,
,定义一个m阶矩阵,![]() :
:
![]()
上式可能不好理解,下面就好好解释一下这个矩阵的含义:

这里我们先假设![]() 即Y只要三种状态可以选择,那么从
即Y只要三种状态可以选择,那么从![]() 的转移有对应的转移矩阵即:
的转移有对应的转移矩阵即:

这里的转移矩阵和马尔科夫的转移矩阵很类似,但是这里不同的是,里面的数据是非归一化的概率,即他是一个数,不是概率,因为我们只是为了比较大小,只需计算出数就可以参与比较了,没必要计算出概率,这样计算量就会降低,这里大家需要理解,另外就是马尔科夫的转移矩阵是不变的,以下没特别说明的都是非归范化的矩阵。但是这里的 ![]() 的矩阵是随着i的变化而变化,因为影响的不仅仅和当前状态有关还和这个输入序列x以及前一个状态有关,还和特征函数有关,因此这里的
的矩阵是随着i的变化而变化,因为影响的不仅仅和当前状态有关还和这个输入序列x以及前一个状态有关,还和特征函数有关,因此这里的![]() 会有很多,这样大家就应该好理解了吧,大家在看下式就很简单了:
会有很多,这样大家就应该好理解了吧,大家在看下式就很简单了:
![]()
那么我们把(1)式逐渐使用矩阵来替换得到如下:

上式的带下标的x和y代表的是一个数即具体的值,不带的说明是一个向量
这样给定观测序列x,标记序列y的非规范化概率可以通过n+1个矩阵的乘积进行表示,于是条件概率![]() 是:
是:

下面给出一个实际的例子,这个例子就是李航的数上的例子。如果大家明白上面的意思了,下面的例子很简单,这里为了大家方便直接拿过来了:


这里稍微解释一下,因为每个状态y都可以去取两个值,而且有三个状态,因此总共有![]() 条路径,其中上图的红色标记是第一条路径即y=(1,1,1),蓝色是y=(2,2,2).其他的感觉就没什么难度了。
条路径,其中上图的红色标记是第一条路径即y=(1,1,1),蓝色是y=(2,2,2).其他的感觉就没什么难度了。
这里为什么需要使用矩阵形式的表达呢?下面我们的学习算法需要使用到。这里我们看看他的参数是如何求解的,其实很简单就是最大熵模型的求解过程,因为这里的目标函数是最大熵模型的指数族是一致的,因此完全可以使用最大熵模型进行求解,本来不想在啰嗦,但是还是解释一下把,为什么可以使用最大熵模型进行求解。
在最大熵模型的求解过程中我给大家推荐了一篇文章即《A Simple Introduction to Maximum Entropy Models for Natural Language Processing》,里面有几个推理我们需要看看:

这里需要先和大家回顾一下符号所代表的意思,其中P是约束条件或者说是期望,Q是求解的最大熵指数族函数,他们有两个推理,其实这两个推理在李航的书也给出了证明,不知道大家是否理解。我们一起来看看:
![]()
这个推理是什么意思呢?就是说在满足约束条件同时又是指数族函数的分布情况下,此时的熵是最大的 ,这是上面的定理告诉我们的,我们在看下一个:

这个推理告诉我们如果所求分布既满足约束条件又满足指数族函数的分布,那么所求的分布一定是最大释然的那个分布,上面的两个定理告诉我们什么呢?
其实就是说如果我们对满足条件又是指数族函数的分布根据最大释然估计出的分布就是符合最大熵的分布 ,不知道大家有没有留意,李航的书中证明了这一点,大家应该好好体会这个特点,以后我们遇到类似的情况是不是也可以这样做呢?
而我们的目标式就是上面的(1)式他就是符合上面两个定理的,约束条件其实就是特征含数了,指数族也是符合的,因此我们可以很好的解决解决CRF的权值![]() 的问题,通过改进的迭代法即IIS进行求解,如下,这里还是带大家推一边吧。
的问题,通过改进的迭代法即IIS进行求解,如下,这里还是带大家推一边吧。
CRF的学习算法即IIS
己知训练数据集,由此可知经验概率分布为![]() ,可以通过极大化训练数据的对数似然函数来求模型参数,训练数据的对数似然函数为
,可以通过极大化训练数据的对数似然函数来求模型参数,训练数据的对数似然函数为

最大释然函数大家有没有疑问的呢?例如 ![]() 为什么是
为什么是![]() 的指数?这里我给大家解释一下:
的指数?这里我给大家解释一下:
**************************************************************************************************************************************

其实第一眼之所以不理解,因为这是最大似然函数的另外一种形式。一般书上描述的最大似然函数的一般形式是各个样本集XX中各个样本的联合概率:
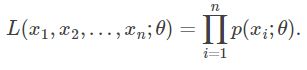
其实这个公式和上式是等价的。是样本具体观测值。随机变量![]() 是离散的,所以它的取值范围是一个集合,假设样本集的大小为n,
是离散的,所以它的取值范围是一个集合,假设样本集的大小为n,![]() 的取值有
的取值有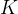 个,分别是
个,分别是![]() 。用
。用![]() 表示在观测值中样本
表示在观测值中样本![]() 出现的频数。所以
出现的频数。所以![]() 可以表示为
可以表示为

对等式两边同时开n次方,可得

因为 就是经验概率,因此可以使用
就是经验概率,因此可以使用![]() 代替即:
代替即:

很明显对![]() 求最大值和对
求最大值和对![]() 求最大值的优化的结果是一样的。整理上式所以最终的最大似然函数可以表示为:
求最大值的优化的结果是一样的。整理上式所以最终的最大似然函数可以表示为:

******************************************************************************************************************************************
到这里大家就清楚了吧,然后就是化简了,如下:

再往下大家看李航的书吧,和最大熵模型求解是一样的,这里大家应该把李航的书的章节的公式多推两边,我推了三遍,才深入理解的,大家别偷懒啊,你只有边推边思考才能体会数学的魅力所在,这里就不废话了。本节到此结束。下一节我们看看李航的书中的求期望问题,为什么要求期望呢?下一节详细介绍。