如何使用Python对中文文档进行可视化的主题建模?

主题建模是一种无监督的机器学习方法,它帮助我们发现文档(语料库)中隐藏的语义结构,它使我们能够快速的发现文档中所包含的主题。 主题模型可以应用于推荐系统和论坛中的帖子自动加注标签等这样的应用中。Latent Dirichlet Allocation(LDA)是一种用于发现文档(语料库)中存在的主题的算法。如果您使用的是Python,目前有一些开源库如Gensim、SkLearn都提供了主题建模的工具,今天我们就来使用这两个开源库提供的3种主题建模工具如Gensim的ldamodel和SkLearn的sklearn.decomposition.NMF和sklearn.decomposition.LatentDirichletAllocation对中文语料库进行主题建模,并比较它们的结果。
LDA和NMF的工作原理
在这里我们不会对主题建模的数学原理进行深入的分析和讲解,因为我们的目的是“实战”和“应用”,如果想深入了解主题建模请自行搜索相关资料和我上面提供的文档的链接。LDA和NMF的数学原理是不一样的,但两种算法都能够返回属于语料库中的主题对应的文档和属于主题的单词。 LDA基于概率图形建模,而NMF是基于于线性代数。 两种算法都将词袋矩阵作为输入(即,每个文档表示为行,每列包含语料库中的单词计数)。 然后,每个算法都会产生2个矩阵:文档的主题分布矩阵和主题的单词分布矩阵:
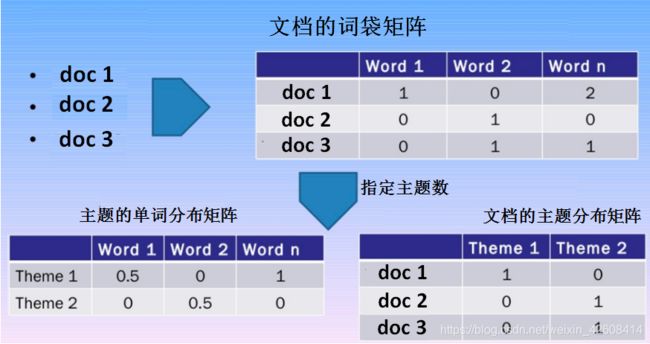
我们要在建模之前指定文档集中所包含的主题数,这是一个问题,上述算法都没有自动确定主题数的功能,主题数类似与聚类算法中的聚类中心数,目前还没有太好的办法来自动确定主题数,一般都是凭经验和对业务的了解来确定主题数。
数据
我们的数据来自于搜狗的新闻语料库,你可以从百度网盘中下载,你也可以下载经过我整理好的csv文件(https://pan.baidu.com/s/10HqLPMyw2nMLgFgrb127VQ 提取码:546q)。首先我们加载所需要的库
import pandas as pd
import chardet
import pandas as pd
import numpy as np
import jieba as jb
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.decomposition import NMF, LatentDirichletAllocation
import gensim
from gensim import corpora
import pyLDAvis.gensimdf = pd.read_csv('./data/sogou2006_2.csv')
df=df[['text','label']]
print(len(df))
df.sample(10)
总共有17909条记录,label是原来文件对应的文件夹名称,所以我导入每个文件夹里面的文件后把它们所在的文件夹作为label,我们查看一下总共有多少个lable:
df['label_id'] = df['label'].factorize()[0]
label_id_df = df[['label', 'label_id']].drop_duplicates().sort_values('label_id').reset_index(drop=True)
label_id_df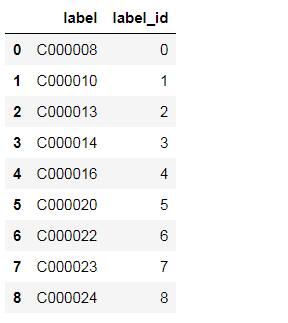
总共有9个label,我将其转换成对应的label_id,接下来我们查看几个新闻的具体内容:



经过对上述新闻内容的查看,我感觉label_id=3的新闻内容是关于“体育”方面的内容,label_id=5好像是和"教育"相关的内容,label_id=8好像是和“军事”相关的内容。由此可见不同的label_id对应不同类型的新闻内容。下面我们要进行数据清洗,因为新闻内容中充斥着大量的符号(回车符换行符等),首先我们定义几个数据清洗的函数:
#定义删除除字母,数字,汉字以外的所有符号的函数
def remove_punctuation(line):
line = str(line)
if line.strip()=='':
return ''
rule = re.compile(u"[^\u4E00-\u9FA5]")
line = rule.sub('',line)
return line
#停用词列表
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
#加载停用词
stopwords = stopwordslist("./data/chineseStopWords.txt")接下来我开始分词和过滤停用词,并生成两个新的字段clean_text和cut_text:
#删除除汉字以外的所有符号
df['clean_text'] = df['text'].apply(remove_punctuation)
#分词,并过滤停用词
df['cut_text'] = df['clean_text'].apply(lambda x: " ".join([w for w in list(jb.cut(x)) if w not in stopwords]))
df.head()
下面我们要对cut_text进行向量化处理,我们将使用两种方法来进行方法来进行文本的向量化处理:CountVectorizer和TfidfVectorizer这两种方法在我之前的博客中都多次提到,这里不再详细讲解:
no_features = 1000
tfidf = TfidfVectorizer(max_features=no_features)
tfidf_features = tfidf.fit_transform(df.cut_text)
tfidf_feature_names = tfidf.get_feature_names()
cv = CountVectorizer(max_features=no_features)
cv_features = cv.fit_transform(df.cut_text)
cv_feature_names = cv.get_feature_names()主题建模
NMF和LatentDirichletAllocation
接下来我们要使用SKLearn的两种主题建模的方法NMF和LatentDirichletAllocation分别来进行主题建模,其中NMF是基于非负矩阵分解(Non-negative Matrix Factorization)来实现主题建模,原始数据中包含了9个分类,那么我们在这里也指定9个主题。在NMF模型中我们使用tf-idf特征向量来训练模型,而在LDA的模型中我们使用CountVectorizer特征向量来训练模型。
两个模型中的参数请参考官方文档,在这里不一一说明。
no_topics = 9
#NMF
nmf_tfidf = NMF(n_components=no_topics, random_state=1, alpha=.1, l1_ratio=.5, init='nndsvd').fit(tfidf_features)
#LDA
lda_cv = LatentDirichletAllocation(n_topics=no_topics, max_iter=5, learning_method='online', learning_offset=50.,random_state=0).fit(cv_features)
模型训练完成后,下面我们打印一下主题的分布:
def display_topics(model, feature_names, no_top_words):
for topic_idx, topic in enumerate(model.components_):
print("主题 {} : {}".format(topic_idx,"|".join([feature_names[i] for i in topic.argsort()[:-no_top_words - 1:-1]])))
no_top_words = 10
print('---------------NMF-tfidf_features 主题-----------------------------------------')
display_topics(nmf_tfidf, tfidf_feature_names, no_top_words)
print()
print('--------------Lda-CountVectorizer_features 主题--------------------------------')
display_topics(lda_cv, cv_feature_names, no_top_words)
我们看到两个模型分布生成了它们的主题的分布,和每个主题中概率最高的前10个词语,下面我们来分析一下这两个模型生成的主题分布:
NMF的主题分布
- 主题0: 应该和生活相关
- 主题1: 好像和金融证券相关
- 主题2:和体育相关
- 主题3: 和旅游相关
- 主题4: 和工作、职业相关
- 主题5: 和教育考试相关
- 主题6: 和医疗相关
- 主题7:和军事相关
- 主题8:和企业相关
LDA的主题分布
- 主题0: 好像和金融证券相关
- 主题1: 和工作、职业相关
- 主题2:和企业相关
- 主题3: 和企业相关
- 主题4: 似乎和体育有关,但不是很明确
- 主题5: 似乎和教育考试相关
- 主题6: 不是很明确
- 主题7:不是很明确
- 主题8:好像和军事有关
经过上述分析,个人感觉好像NMF的主题分布更加明确。LDA的主题分布有些不明确的地方,也有些主题含义似乎有重叠。
接下来我们使用训练集以外的数据来预测一下主题,我们随机从各大门户网站摘录几条新闻来进行预测:
def predict_topic_by_cv(text):
txt = remove_punctuation(text)
txt = [w for w in list(jb.cut(txt)) if w not in stopwords]
txt = [w for w in txt if len(w)>1]
txt = [" ".join([w for w in txt])]
newfeature = cv.transform(txt)
doc_topic_dist_unnormalized = np.matrix(lda_cv.transform(newfeature))
doc_topic_dist = doc_topic_dist_unnormalized/doc_topic_dist_unnormalized.sum(axis=1)
topicIdx = doc_topic_dist.argmax(axis=1)[0,0]
print('该文档属于:主题 {}'.format(topicIdx))
print("主题 {} : {}".format(topicIdx,"|".join([cv_feature_names[i] for i in (lda_cv.components_[topicIdx,:]).argsort()[:-no_top_words - 1:-1]])))
上述随机从门户网站上摘录的新闻预测结果似乎是正确的。
Gensim 主题建模
下面我们使用Gensim库来进行LDA主题建模,Gensim的LDA建模需要两个东西: dictionary(字典)和corpus(语料),其中dictionary用来存放文档集的词汇表和索引,corpus则是文档集的向量化表示,它类似与sklearn的CountVectorizer和TfidfVectorizer的向量化表示,因此corpus也有两种表示方法:基于计算的和基于TF-IDF的向量化表示:
text_data = df.cut_text.apply(lambda x:x.split())
#过滤掉单个汉字的词语
text_data = text_data.apply(lambda x:[w for w in x if len(w)>1] )
dictionary = corpora.Dictionary(text_data)
#过滤掉词频小于5次,和词频大于90%的词语
dictionary.filter_extremes(no_below=5, no_above=0.9)下面我们使用基于计数的语料来进行主题建模,我们指定了7个主题:
#计数的语料
corpus = [dictionary.doc2bow(text) for text in text_data]
#普通LDA模型
import gensim
no_topics = 9
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = no_topics, id2word=dictionary)
topics = ldamodel.print_topics(num_words=8)
for topic in topics:
print("主题 %d: " % (topic[0]))
print(topic[1])
print()

下面我们使用基于TF-IDF的语料来进行主题建模,我们同样指定了7个主题,在这里我们使用的是基于并发的多核LDA模型(LdaMulticore),如果你的CPU是多核的可以使用该方法来训练模型,这样可以缩短训练的时间:
#tf-idf语料
tfidf = gensim.models.TfidfModel(corpus)
corpus_tfidf = tfidf[corpus]
#多核并行lda模型
no_topics = 9
tf_idf_lda_model = gensim.models.LdaMulticore(corpus_tfidf, num_topics=no_topics, id2word=dictionary, passes=2, workers=4)
topics = tf_idf_lda_model.print_topics(num_words=8)
for topic in topics:
print("主题 %d: " % (topic[0]))
print(topic[1])
print() 
可视化
pyLDAvis是一个可以帮助用户理解语料库中主题分布的一个可视化工具。 pyLDAvis从训练好的LDA主题模型中提取信息,以通Web的交互式形式将主题分布做可视化的展示。
lda_display = pyLDAvis.gensim.prepare(tf_idf_lda_model, corpus_tfidf, dictionary, sort_topics=False)
pyLDAvis.display(lda_display)
lda_display = pyLDAvis.gensim.prepare(ldamodel, corpus, dictionary, sort_topics=False)
pyLDAvis.display(lda_display)
图中圆圈代表不同的主题,圆圈的大小代表主题的重要程度,圆圈越大表示该主题对应数据来说更重要。如果圆圈之间有相互重叠则说明它们所代表的主题有相似之处。
完整代码在此下载
