【李宏毅2020 ML/DL】P67-72 Anomaly Detection
我已经有两年 ML 经历,这系列课主要用来查缺补漏,会记录一些细节的、自己不知道的东西。
本系列课程第 5 节有缺失,我已找到补充视频,见【 李宏毅机器学习:异常检测 】Anomaly Detection(合辑)(中文)
本节内容综述
- 概括一下异常检测问题 Problem Formulation 。什么是异常呢?What is Anomaly? 与训练集不是一类的东西。
- 有什么应用呢?
- 这不就是二分类问题吗?不是。要注意,
对于 Anomaly Detection 问题,其异常集几乎是无穷无尽的。况且,其可能没有异常数据。 - 异常检测问题的分类Categories。
- 首先,来讨论第一个类别:With Classifier。
- 此外,除了设置 Training Set ,还可以设置 Dev Set 。
- 讨论一个问题:有些特征很强,能被分类器识别。但是对于没有这些特征的异常图片,则很难进行识别。见 Possible Issues 。
- 进入第二个类别:Without Label 。
文章目录
- 本节内容综述
- 小细节
- Problem Formulation
- Applications?
- Categories
- With Classifier
- Outlook: Network for Confidence Estimation
- Dev Set - Evaluation
- 建立混淆矩阵与Cost Table
- Possible Issues
- Without Label
- Problem Formulation
- Maximum Likelihood & Gaussian Distribution
- Outlook: Auto-encoder
小细节
Problem Formulation
- 有训练数据: { x 1 , x 2 , . . . , x N } \{x^1,x^2,...,x^N\} {x1,x2,...,xN}
- 来了一个新数据,判断是否是训练集中的(是否相似)。

从外,不一定是检测出“不好”的东西。
Applications?
Fraud Detection
训练数据:正常刷卡行为;来判断盗刷行为。有 kaggle 比赛。
Network Intrusion Detection
训练数据:正常连线;来判断是否有攻击行为。
Cancer Detection
训练数据:正常细胞;来检测癌细胞等。
Categories
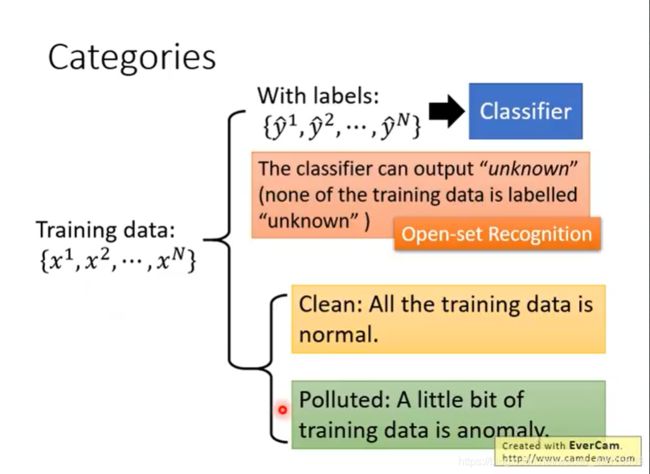
如上,可分为有标签与无标签。但是,在有标签中,没有标签是 ‘unkown’ ,因此,这个还不是个简单的分类问题,因为有一类 ‘unkown’ 没有训练数据,是一个 Open-set Recognition 。
With Classifier
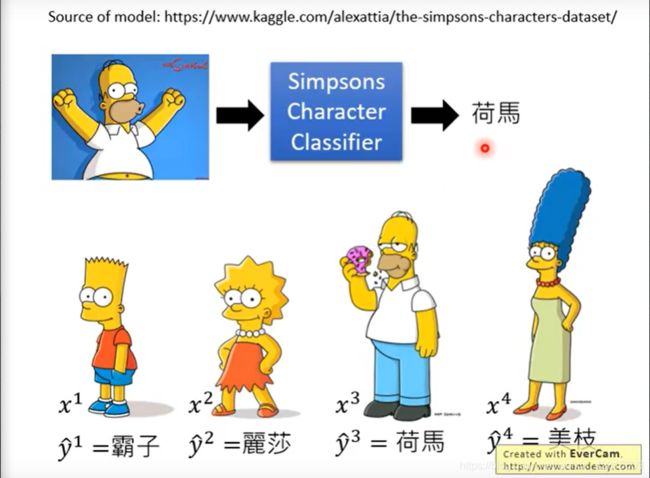
如上,每个辛普森家庭人物图像都有标签。
训练好了这个人物分类器后,我们使用这个分类器来做 Anomaly Detection 。
我们设置“信心分数” λ \lambda λ:
f ( x ) = { normal, c ( x ) > λ anomaly, c ( x ) ≤ λ f(x)=\left\{\begin{array}{ll} \text { normal, } & c(x)>\lambda \\ \text { anomaly, } & c(x) \leq \lambda \end{array}\right. f(x)={ normal, anomaly, c(x)>λc(x)≤λ

如上,我们把一张其他动漫的人物放入分类器,发现其“没有信心”。因此判定为 Anomaly 。
我们可以根据正常图片的最高分或者异常图片的最高分来设定信心分数。
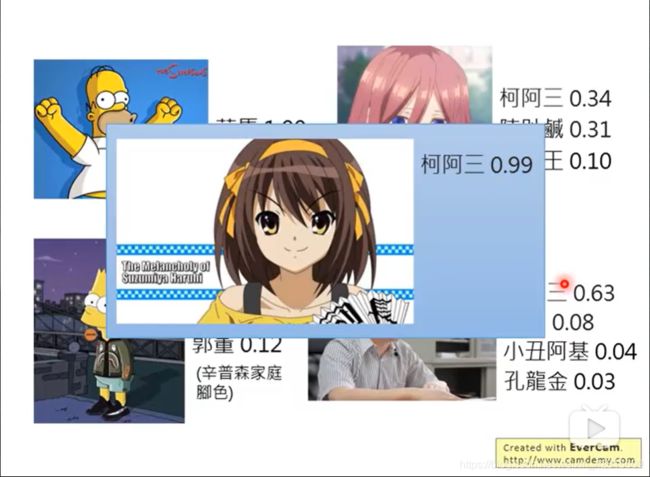
如上,李老师做了实验。发现也不太鲁棒。比如这里,“凉宫春日”被认成了“柯阿三”,且分数为 0.99 。
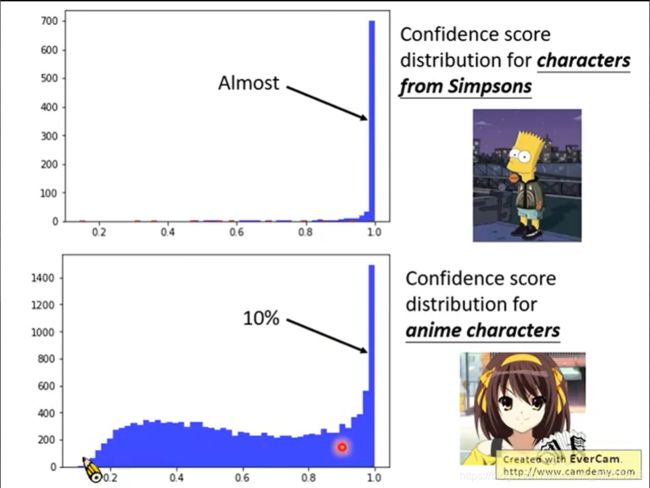
如上,辛普森家族得分分布与其他动漫人物得分分布。
Outlook: Network for Confidence Estimation

如上,直接教神经网络看出“信心分数”,不仅仅做分类。
Dev Set - Evaluation

如上,我们设置了一个 Dev Set ,其中有是否为异常的标签。

如上,异常的数据不用太多,这里我们有100个正常图片,5个一场图片(李老师还在课上介绍了这五位人物…)。
最右边的,其信心分数达到了 0.998 ,但实际上,绝大部分正常图片都是高于 0.998 分的。
如何在 Dev Set 上评估系统好坏呢?
使用二分类正确率并不是个好的选择。
建立混淆矩阵与Cost Table

如上,根据阈值,建立混淆矩阵。
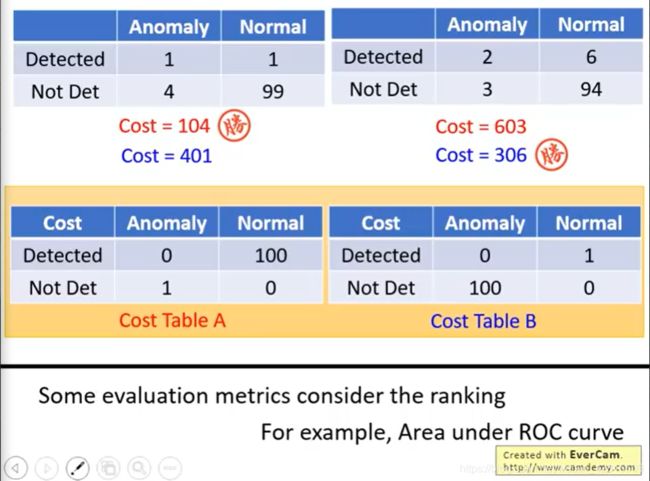
如上,在不同情境中,会有不同的 Cost Table 。这决定了阈值放在哪里更好。
此外,还有 ROC 曲线的方法等。
Possible Issues

如上,李老师将图片涂黄,果然,特征被加强了,检测器认为其是辛普森一家的人物概率也更高了。

如上,可以使用生成模型生成一些“假数据”,用于增强检测器鲁棒性。
Without Label
Problem Formulation
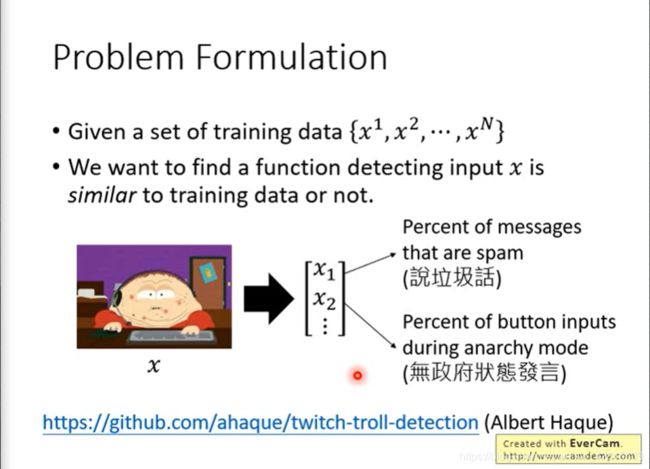
李老师举了一个例子,检测异常玩家。
在没有标签的情况下,可以建立一个概率模型 P ( x ) P(x) P(x)。
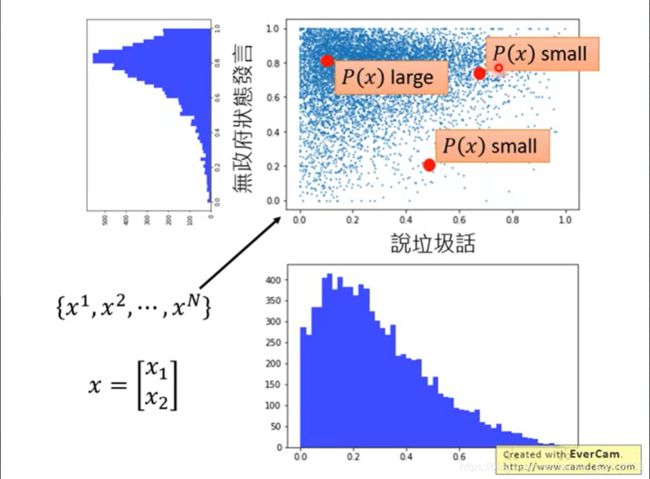
假设每个玩家可以用一个二维状态来表示,如上。
Maximum Likelihood & Gaussian Distribution
极大似然法,不再赘述。

如上,对于用于拟合的模型,使用高斯分布。
此外,高斯分布的极大似然拟合是有公式的:
μ ∗ = 1 N ∑ n = 1 N x n \mu^* = \frac{1}{N}\sum_{n=1}^N x^n μ∗=N1n=1∑Nxn
Σ ∗ = 1 N ∑ n = 1 N ( x − μ ∗ ) ( x − μ ∗ ) T \Sigma^* = \frac{1}{N} \sum^N_{n=1} (x - \mu^*)(x-\mu^*)^T Σ∗=N1n=1∑N(x−μ∗)(x−μ∗)T
但是,如果数据本身不服从高斯分布怎么办呢?可以使用其他模型,如生成模型等等。
因此,可以做异常检测了:


如上,可以取 log 。
Outlook: Auto-encoder
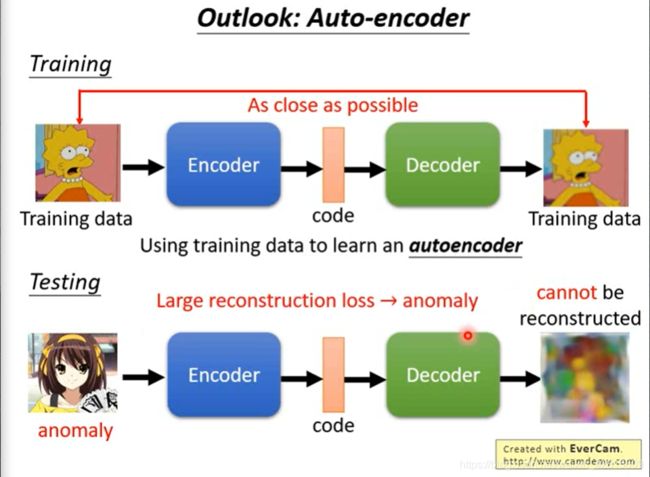
这里做了个展望,可以用 Auto-encoder 来做。如上,如果编码再解码后,还原度低(loss)大,则也可说明是异常数据。
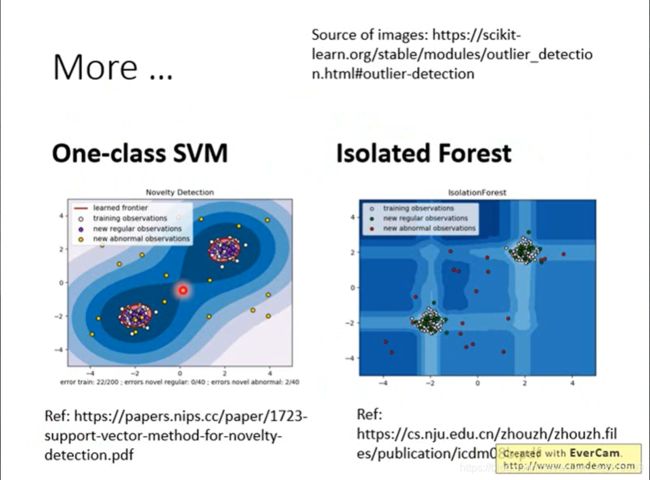
如上,此外还可以用SVM、孤立森林做。