StanfordCoreNLP安装讲解 + win10+anaconda python环境
近期选了nlp课 需要安装StanfordCoreNLP,在网上找了很久没有找到写的很详细的安装过程,于是自己写篇。我的电脑配置win10专业版。
StanfordCoreNLP安装讲解 + win10+anaconda python环境
- 一、StanfordCoreNLP简介
- 二、安装
- 1、需要先下载安装jdk1.8,并配置好java路径
- (1)下载Java安装包
- (2) 安装Java
- (3)环境配置
- (4)检查下Java是否安装成功
- 2、安装配置stanford nlp与中英文语言包
- 三、StanfordCoreNLP的具体功能使用
- 四、 参考资料
一、StanfordCoreNLP简介
Stanford CoreNLP是一个集成的NLP工具包,具有广泛的语法分析工具,包括:标记化(分词),lemmatization,POS标签,情感分析,命名实体识别,开放信息提取,选区/依赖性解析等。它同时支持英文和中文文本。
二、安装
1、需要先下载安装jdk1.8,并配置好java路径
我本身电脑并没有安装Java ,所以以下讲解详细过程。
(1)下载Java安装包
网址: https://www.oracle.com/java/
-
进入网站后点击Technical Details
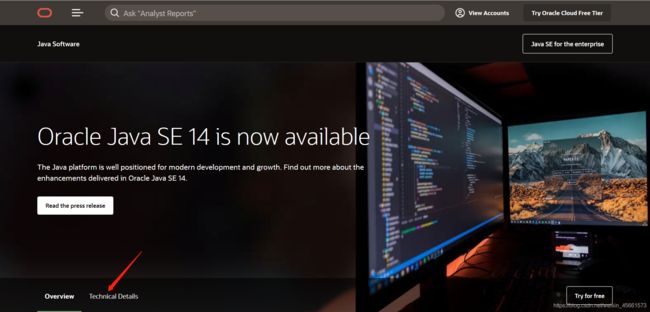
-
点击Java SE14

-
点击JDK Download
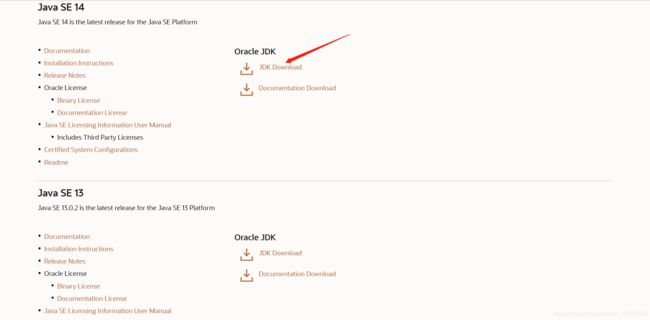
-
选择jdk-14_windows-x64_bin.exe
我这里选择的exe.的压缩包,zip应该也是可以的
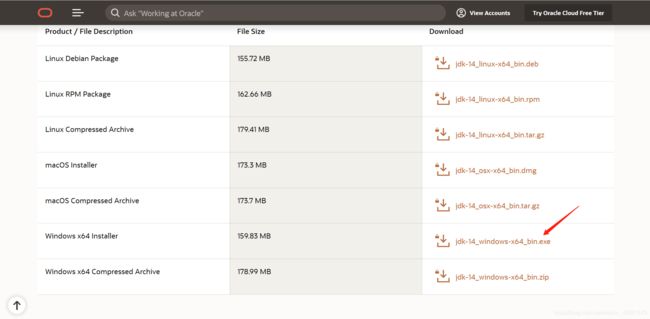
5. 勾选i review即可
(2) 安装Java
按照正常安装软件安装即可,我安装在D盘,非系统盘上。![]()
(3)环境配置
-
右键点击此电脑—属性

-
左侧点击高级系统设置

-
点击环境变量

-
设置用户变量和系统变量
- 设置用户变量
点击新建
命名为JAVA_HOME
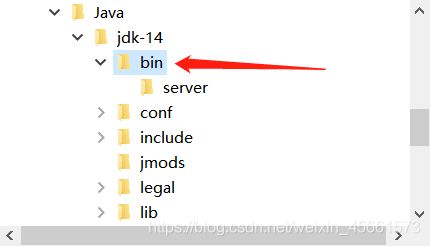
变量值以防写错 我点击浏览目录选择了安装刚刚Java的jdk-14文件夹
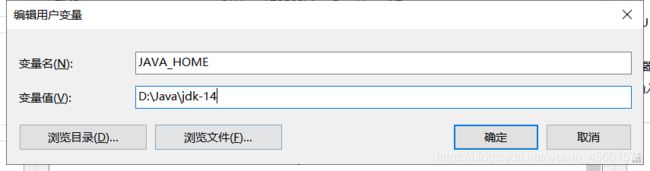
- 设置系统变量
点击path–选择编辑
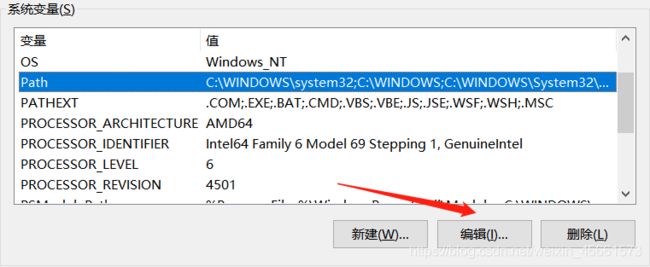
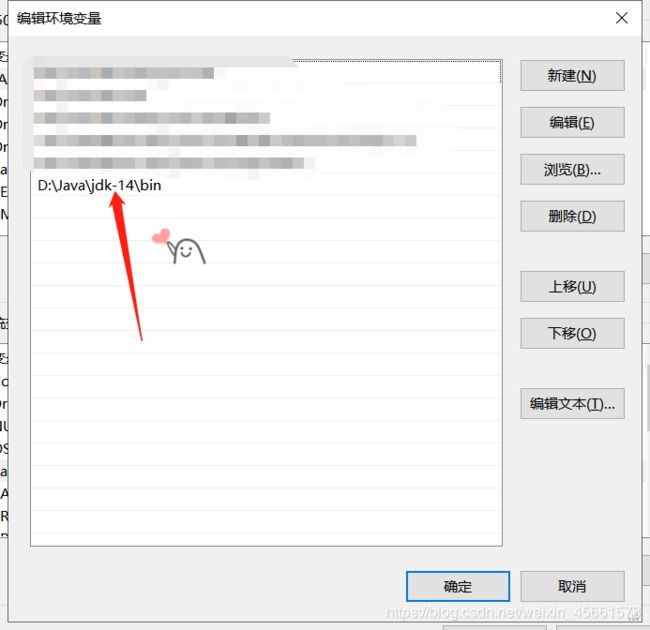
进入path设置页面后,点击新建—浏览—(再次以防敲错)选择刚才java安装文件夹里的bin文件夹即可
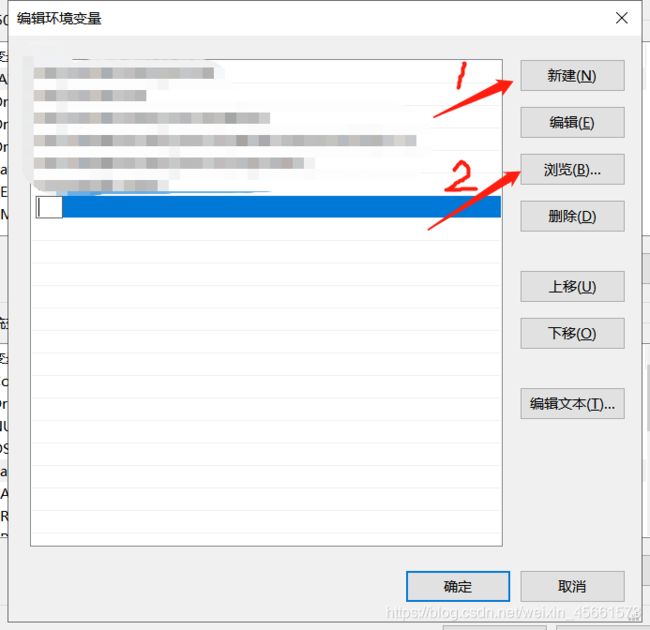
好啦环境变量配置成功
(4)检查下Java是否安装成功
win+R 输入cmd

输入 java -version 显示如下界面就是java安装好啦

2、安装配置stanford nlp与中英文语言包
好啦 搞好java环境 我们就要开始安装Stanford nlp
下载网址:https://stanfordnlp.github.io/CoreNLP/index.html
- 下载
点击download
我在这里下载了三个东西
(1)CoreNLP 3.9.2
(2)中文包
(3)英文包
文件很大 下了蛮久的QQ

以下是下载的3个文件截图


- 安装
- 解压下载的第一个文件 stanford-corenlp-full-2018-10-05
- 讲下面两个jar.格式的文件放入上面解压缩的文件夹内即可
- 安装stanfordcorenlp
在python下安装stanfordcorenlp,我配置的python环境是conda里的所有直接在jupyter notebook里面运行pip
pip install stanfordcorenlp
这里它让我restart以下 关掉再打开就好啦
- 检测
- 先检测安装的中文包
代码如下
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP(r'D:\Stanford\stanford-corenlp-full-2018-10-05', lang="zh") #r后面是安装的Stanford文件夹的位置
sentence = '清华大学位于北京。'
print(nlp.word_tokenize(sentence)) # 中文分词
print(nlp.pos_tag(sentence)) # 词性标注
print(nlp.ner(sentence)) # 命名实体分析
print(nlp.parse(sentence)) # 解析语法
print(nlp.dependency_parse(sentence)) # 解析语法关系
nlp.close()output:
[‘清华’, ‘大学’, ‘位于’, ‘北京’, ‘。’]
[(‘清华’, ‘NR’), (‘大学’, ‘NN’), (‘位于’, ‘VV’), (‘北京’, ‘NR’), (’。’, ‘PU’)]
[(‘清华’, ‘ORGANIZATION’), (‘大学’, ‘ORGANIZATION’), (‘位于’, ‘O’), (‘北京’, ‘STATE_OR_PROVINCE’), (’。’, ‘O’)]
(ROOT
(IP
(NP (NR 清华) (NN 大学))
(VP (VV 位于)
(NP (NR 北京)))
(PU 。)))
[(‘ROOT’, 0, 3), (‘compound:nn’, 2, 1), (‘nsubj’, 3, 2), (‘dobj’, 3, 4), (‘punct’, 3, 5)]
nlp = StanfordCoreNLP()
其中两个参数分别表示解压缩的文件夹目录以及语言选择,如果是英文则lang=‘en’,中文是lang=‘zh’, 其他语言以此类推。
- 检测英文包
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP(r'D:\Stanford\stanford-corenlp-full-2018-10-05',lang='en')
sentence = "Kosgi Santosh sent an email to Stanford University. He didn't get a reply"
print('Named Entities:', nlp.ner(sentence))
output

三、StanfordCoreNLP的具体功能使用
参考:https://stanfordnlp.github.io/CoreNLP/annotators.html
四、 参考资料
【1】https://blog.csdn.net/Caramel_c/article/details/103813556?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
【2】https://blog.csdn.net/DwyanePeng/article/details/102546996
【3】https://blog.csdn.net/Sakura55/article/details/87347785
第一次写博文!谢谢大家鼓励!