泰坦尼克(机器学习逻辑回归)
泰坦尼克(机器学习逻辑回归)
原文链接
数据预处理
import pandas as pd
train=pd.read_csv('C:/Users/Admin/Downloads/train.csv')
train.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
可见age,cabin有缺失数据,
对于age:
用随机森林预测缺失的age
随机森林
用在原始数据中做不同采样,建立多颗DecisionTree,再进行average等等来降低过拟合现象,提高结果的机器学习算法
缺失值
如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
#用随机森林处理age缺失值
from sklearn.ensemble import RandomForestRegressor
age_df=train[['Age','Fare', 'Parch', 'SibSp','Pclass']]
known_age=age_df[age_df.Age.notnull()].as_matrix()
unknown_age=age_df[age_df.Age.isnull()].as_matrix()
y=known_age[:, 0]
x=known_age[:, 1:]
rfr=RandomForestRegressor(random_state=0,n_estimators=2000,n_jobs=-1)
rfr.fit(x,y)
predictAge=rfr.predict(unknown_age[:,1:])
train.loc[(train.Age.isnull()),'Age']=predictAge
因为逻辑回归建模时,需要输入的特征都是数值型特征,所以,先对类目型的特征因子化,使用pandas的"get_dummies"来完成这个工作,并拼接在原来的"data_train"之上
train.loc[(train.Cabin.notnull()),'Cabin']=1
train.loc[(train.Cabin.isnull()),'Cabin']=0
dummies_sex=pd.get_dummies(train['Sex'],prefix='Sex')
dummies_Cabin=pd.get_dummies(train['Cabin'],prefix='Cabin')
dummies_embarked=pd.get_dummies(train['Embarked'],prefix='Embarked')
dummies_Pclass=pd.get_dummies(train['Pclass'],prefix='Pclass')
train=pd.concat([train,dummies_sex,dummies_Cabin,dummies_embarked,dummies_Pclass],axis=1)
train.drop(['Pclass','Name','Sex','Ticket','Cabin','Embarked'],axis=1,inplace=True)

Age和Fare两个属性,乘客的数值幅度变化太大了。
逻辑回归与梯度下降的话,各属性值之间scale差距太大,将对收敛速度造成几万点伤害值!甚至不收敛!
对age:
标准化将一些变化幅度较大的特征化到[-1,1]之内。
import sklearn.preprocessing as preprocessing
new_fare=np.array(train['Fare']).reshape(-1,1)
scaler=preprocessing.StandardScaler().fit(new_fare)
train['Fare_scaled']=scaler.transform(new_fare)
train.drop(['Fare'],axis=1,inplace=True)
import sklearn.preprocessing as preprocessing
import numpy as np
scaler=preprocessing.StandardScaler()
#new_age=np.array(train['Age']).reshape(-1,1)
train['Age_scaled']=scaler.fit_transform(np.array(train['Age']).reshape(-1,1))
train.drop(['Age'],axis=1,inplace=True)
查看此时的train为:
逻辑回归建模
from sklearn import linear_model
train_df=train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np=train_df.as_matrix()
y=train_np[:,0]
x=train_np[:,1:]
clf=linear_model.LogisticRegression(C=1.0,penalty='l1',tol=1e-6)
clf.fit(x,y)
clf
得到一个model

现在对test做一样的预处理
test=pd.read_csv('C:/Users/Admin/Downloads/test.csv')
test.loc[(test.Fare.isnull()),'Fare']=0
tmp_df=test[['Age','Fare','Parch','SibSp','Pclass']]
notnull_age=tmp_df[tmp_df.Age.notnull()].as_matrix()
null_age=tmp_df[tmp_df.Age.isnull()].as_matrix()
x=notnull_age[:,1:]
y=notnull_age[:,0]
from sklearn.ensemble import RandomForestRegressor
rfr=RandomForestRegressor(random_state=0,n_estimators=2000,n_jobs=-1).fit(x,y)
predictAge=rfr.predict(null_age[:,1:])
test.loc[(test.Age.isnull()),'Age']=predictAge
test.loc[(test.Cabin.notnull()),'Cabin']=1
test.loc[(test.Cabin.isnull()),'Cabin']=0
dummies_Cabin=pd.get_dummies(test['Cabin'],prefix='Cabin')
dummies_Embarked = pd.get_dummies(test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(test['Pclass'], prefix= 'Pclass')
test = pd.concat([test, dummies_Embarked, dummies_Sex, dummies_Pclass,dummies_Cabin], axis=1)
test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Embarked','Cabin'], axis=1, inplace=True)
import sklearn.preprocessing as preprocessing
scaler=preprocessing.StandardScaler()
test['Age_scaled']=scaler.fit_transform(np.array(test['Age']).reshape(-1,1))
test['Fare_scaled']=scaler.fit_transform(np.array(test['Fare']).reshape(-1,1))
test.drop(['Age','Fare'],axis=1,inplace=True)
test

预测取结果吧
from sklearn import linear_model
x_test = test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(x_test)
result = pd.DataFrame({'PassengerId':test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result

逻辑回归系统优化
1.模型系数关联分析
把得到的model系数和feature关联起来看看。
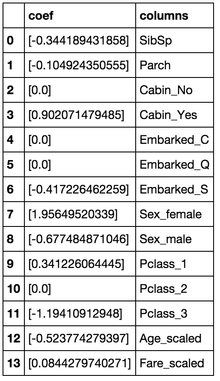
重绝对值非常大的feature,在我们的模型上:
Sex属性,如果是female会极大提高最后获救的概率,而male会很大程度拉低这个概率。
Pclass属性,1等舱乘客最后获救的概率会上升,而乘客等级为3会极大地拉低这个概率。
有Cabin值会很大程度拉升最后获救概率(这里似乎能看到了一点端倪,事实上从最上面的有无Cabin记录的Survived分布图上看出,即使有Cabin记录的乘客也有一部分遇难了,估计这个属性上我们挖掘还不够)
Age是一个负相关,意味着在我们的模型里,年龄越小,越有获救的优先权(还得回原数据看看这个是否合理)
有一个登船港口S会很大程度拉低获救的概率,另外俩港口压根就没啥作用(这个实际上非常奇怪,因为我们从之前的统计图上并没有看到S港口的获救率非常低,所以也许可以考虑把登船港口这个feature去掉试试)。
船票Fare有小幅度的正相关(并不意味着这个feature作用不大,有可能是我们细化的程度还不够,举个例子,说不定我们得对它离散化,再分至各个乘客等级上?)
2.交叉验证
from sklearn import model_selection
clf=linear_model.LogisticRegression(C=1.0,penalty='l1',tol=1e-6)
all_data=train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
x=all_data.as_matrix()[:,1:]
y=all_data.as_matrix()[:,0]
print(model_selection.cross_val_score(clf,x,y,cv=5))
结果为
[0.81564246 0.81564246 0.78651685 0.78651685 0.81355932]
下面我们做数据分割,并且在原始数据集上瞄一眼bad case:
split_train,split_cv=model_selection.train_test_split(train,test_size=0.3,random_state=0)
train_df=split_train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
clf=linear_model.LogisticRegression(C=1.0,penalty='l1',tol=1e-6)
clf.fit(train_df.as_matrix()[:,1:],train_df.as_matrix()[:,0])
cv_df=split_cv.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions=clf.predict(cv_df.as_matrix()[:,1:])
origin_data_train=pd.read_csv('C:/Users/Admin/Downloads/train.csv')
bad_cases=origin_data_train.loc[origin_data_train['PassengerId'].isin(split_cv[predictions!=cv_df.as_matrix()[:,0]]['PassengerId'].values)]
bad_cases

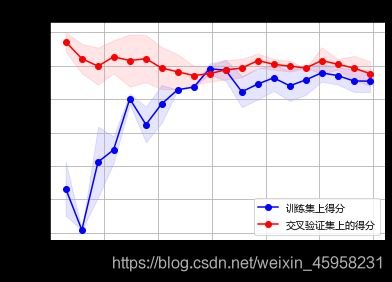
学习曲线
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
train_sizes,train_scores,test_scores=learning_curve(
clf,x,y,cv=None,n_jobs=1,train_sizes=np.linspace(.05,1.,20),verbose=0)
train_scores_mean=np.mean(train_scores,axis=1)
train_scores_std=np.std(train_scores,axis=1)
test_scores_mean=np.mean(test_scores,axis=1)
test_scores_std=np.std(test_scores,axis=1)
plot=True
ylim=None
if plot:
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
plt.figure()
plt.title('学习曲线')
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel('训练样本数')
plt.ylabel('得分')
plt.gca().invert_yaxis()#x轴反向
plt.grid()
plt.fill_between(train_sizes,train_scores_mean-train_scores_std,train_scores_mean+train_scores_std,alpha=0.1,color='b')
plt.fill_between(train_sizes,test_scores_mean-test_scores_std,test_scores_mean+test_scores_std,alpha=0.1,color='r')
plt.plot(train_sizes,train_scores_mean,'o-',color='b',label='训练集上得分')
plt.plot(train_sizes,test_scores_mean,'o-',color='r',label='交叉验证集上的得分')
plt.legend(loc='best')
plt.draw()
plt.show()
plt.gca().invert_yaxis()