XML解析之DOM、SAX、JAXP、DOM4J
XML解析之DOM、SAX、JAXP、DOM4J
1. DOM与SAX
XML是 一种通用的数据交换格式,可以使数据在各种应用程序之间轻松地实现数据交换。
虽然XML有各种各样的优点,但对于XML的解析并不是一件简单的事。
在XML发展的过程中,出现了两种解析模型,即DOM与SAX。这两种模型各有各的优点以及缺点。
1. DOM
文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展标志语言的标准编程接口。在网页上,组织页面(或文档)的对象被组织在一个树形结构中,用来表示文档中对象的标准模型就称为DOM。
2. SAX
SAX,它既是一个接口,也是一个软件包.但作为接口,SAX是事件驱动型XML解析的一个标准接口不会改变 SAX的工作原理简单地说就是对文档进行顺序扫描,当扫描到文档(document)开始与结束、元素(element)开始与结束、文档(document)结束等地方时通知事件处理函数,由事件处理函数做相应动作,然后继续同样的扫描,直至文档结束。
3. DOM与SAX的区别
DOM与SAX是对xml两种不同的方式。
DOM在解析时是对xml完全装载在内存中,将其完整分析后,以一组对象的形式保存起来。如下图:
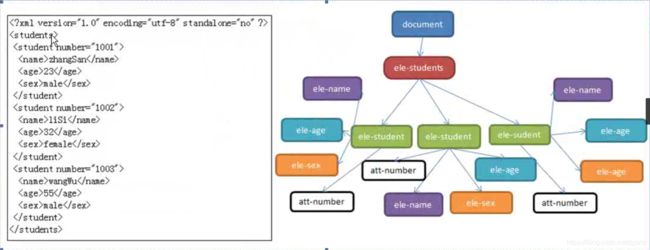
这种方式可以完整的展现出当前文件的信息以及结构。但由于这种方式需要将整个xml装载到内存中,如果我们读取的xml文件过大,就可能会出现爆内存的现象。
SAX在解析xml时是对xml逐行进行解析。
其在解析过程中,在待定事件引发时,来调用接口中的特定方法。在开始SAX解析之前用户需要给SAX提供接口实现类。
SAX解析总的来看适合对超大的xml文件进行解析,由于其逐行解析的方法,无需完整读取xml,占用内存极小,不会出现爆内存的现象。但也是由于其逐行解析的方式,每次只能分析一行数据,无法完整的获取xml的结构信息。
2. JAXP与DOM4J
上文中提到的SAX与DOM是两种对xml解析的模型,并不是具体的实现。
在Java中,对xml解析我们通常使用JAXP和DOM4J两种工具进行解析。
我们使用的xml例子如下:
<teams>
<team name="Madrid">
<person>Ronaldoperson>
<person>Casillasperson>
<person>Ramosperson>
<person>Modricperson>
<person>Benzemaperson>
team>
<team name="Lakers">
<person>Onealperson>
<person>Bryantperson>
team>
teams>
1. JAXP
JAXP是由Java提供的一个xml解析器,JAXP是对所有像xerces一样的解析的提供统一接口的API。
当我们使用JAXP完成解析工作时,还需要为JAXP指定xerces或其他解析器,但需要更换解析器时,无需修改代码,只需要修改配置即可。同时,如果我们没有提供解析器,JAXP还可以调用自带的解析器。
JAXP中可以使用DOM也可以使用SAX对xml进行解析。
1. JAXP for DOM
使用JAXP之DOM对xml进行解析时,步骤如下:
- 创建工厂
- 通过工厂得到解析器
- 通过解析器来解析xml,得到document
- 对document进行各项操作
例程如下:
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import java.io.File;
public class demo {
/*
获取document对象
1. 创建工厂
2. 通过工厂得到解析器
3. 通过解析来解析xml,得到document
*/
private static Document getDocument() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("D:\\SoftwareData\\IDEA\\POS\\src\\chapter_1.xml"));
return document;
}
/*
遍历Document
1. 从Document中获取根元素,即文档元素
2. 通过root元素获取它的所有子元素
*/
private static void forElement(Document document) {
//此处得到最外层的元素
Element root = document.getDocumentElement();
//获得根元素下的节点列表
NodeList nodeList = root.getElementsByTagName("team");
//遍历节点列表
for(int i = 0; i < nodeList.getLength(); i++){
Node node = nodeList.item(i);
//每个节点都是element类型,所以我们可以将node转换成element类型
Element element = (Element) node;
//获得节点的name元素
String name = element.getAttribute("name");
System.out.println("球队名称:" + name);
//获得节点的子元素列表
NodeList elementnodelist = element.getElementsByTagName("person");
//遍历列表
for (int j = 0; j < elementnodelist.getLength(); j++){
Node node1 = elementnodelist.item(j);
Element element1 = (Element) node1;
//获取element的text
String name1 = element1.getTextContent();
System.out.println("队员姓名:" + name1);
}
}
}
public static void main(String[] args) throws Exception{
forElement(getDocument());
}
}
运行结果如下图:

2. JAXP for SAX
在JAXP中使用SAX与使用DOM方法类似,唯一需要注意的是我们需要实现一个接口类。这个类需要继承自DefaultHandler。
例程如下:
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.File;
public class jaxp_sax {
/*
SAX采用逐行解析的方法进行解析
1. 创建工厂
2. 获取解析器
3. 对解析器提供xml文件以及管理器
*/
private static void SAXDocument() throws Exception{
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
parser.parse(new File("D:\\SoftwareData\\IDEA\\POS\\src\\chapter_1.xml"), new MyHandler());
}
public static void main(String[] args) throws Exception{
SAXDocument();
}
}
/*
实现管理器接口
所有方法仅为例子,其中具体的实现依照具体问题而定
*/
class MyHandler extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
System.out.println("开始解析");
}
@Override
public void endDocument() throws SAXException {
System.out.println("结束解析");
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println("开始解析元素:" + qName);
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("结束解析元素:" + qName);
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String string = new String(ch, start, length);
System.out.println(string);
}
运行结果如下图:

2. DOM4J
DOM4J,顾名思义,该工具是使用DOM对xml进行解析的。该工具与JAXP相比,其操作更简便,功能更全面。现在绝大多数公司都使用该工具对xml进行解析。
需要注意的是,在使用该工具时我们必须要导入两个jar包,这两个jar包有的软件会集成进去,有的不会,需要我们自己导入。这两个jar包分别为:
- dom4j.jar
- jaxen.jar

具体例程如下:
//所有使用的均为dom4j包中的方法
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.util.List;
public class demo1 {
//读取xml
private static Document readDocument(String path) throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File(path));
return document;
}
//写入xml
private static void writeDocument() throws Exception {
//SAXReader reader = new SAXReader();
//Document document = reader.read(new File("src/chapter_1.xml"));
Document document = readDocument("src/chapter_1.xml");
//将数据写入xml
XMLWriter writer = new XMLWriter(new FileOutputStream("src/chapter_1_copy.xml"));
writer.write(document);
}
//遍历xml
private static void ergodicDocument() throws Exception{
//读取xml
Document document = readDocument("src/chapter_1.xml");
//获取xml的根元素
Element root = document.getRootElement();
//获取根元素的子元素列表
List<Element> elementList = root.elements("team");
//遍历子元素列表
for (Element element: elementList) {
//获取子元素的name属性
String name = element.attributeValue("name");
System.out.println("球队的名称为:" + name);
//获取当前元素的子元素列表
List<Element> list = element.elements("person");
//遍历列表
for (Element element1: list) {
//获取元素的值
String name1 = element1.getText();
System.out.println("球员的姓名为:" + name1);
}
System.out.println();
}
}
//修改xml
private static void chengeDocument() throws Exception{
//读取xml
Document document = readDocument("src/chapter_1_copy.xml");
//查找到需要修改的元素
Element element = (Element) document.selectSingleNode("//team[@name='deyunshe']");
//修改指定元素信息
element.element("person").setText("banzhu - guodegang");
//设置格式化器,“\t" 为添加制表符, true为添加回车
OutputFormat format = new OutputFormat("\t", true);
//删除原格式中的空白
format.setTrimText(true);
//写入数据
XMLWriter writer = new XMLWriter(new FileOutputStream("src/chapter_1_copy.xml"), format);
writer.write(document);
}
//添加xml
private static void addDocument() throws Exception{
//读取元素
Document document = readDocument("src/chapter_1.xml");
//获取根元素
Element root = document.getRootElement();
/*
1. 在需要添加元素的位置添加元素
2. 设置元素的属性
3. 设置元素的子元素
*/
Element teams = root.addElement("team");
teams.addAttribute("name", "deyunshe");
teams.addElement("person").setText("guodegang");
teams.addElement("person").setText("yuqian");
//设置格式化器,“\t" 为添加制表符, true为添加回车
OutputFormat format = new OutputFormat("\t", true);
//删除原格式中的空白
format.setTrimText(true);
//写入数据
XMLWriter writer = new XMLWriter(new FileOutputStream("src/chapter_1_copy.xml"), format);
writer.write(document);
}
//删除xml
private static void delDocument() throws Exception{
Document document = readDocument("src/chapter_1_copy.xml");
//使用Xpath查询需要删除的元素,其中“@”表示查找其属性
Element element = (Element) document.selectSingleNode("//team[@name='deyunshe']");
//先获取需要删除元素的父元素,获取后通过父元素移除该元素
element.getParent().remove(element);
//设置格式化器,“\t" 为添加制表符, true为添加回车
OutputFormat format = new OutputFormat("\t", true);
//删除原格式中的空白
format.setTrimText(true);
//写入数据
XMLWriter writer = new XMLWriter(new FileOutputStream("src/chapter_1_copy.xml"), format);
writer.write(document);
}
public static void main(String[] args) throws Exception{
ergodicDocument();
}
}