【深度学习】8:CNN卷积神经网络与sklearn数据集实现数字识别
前言:这个代码是自己闲暇无事时候写的。
因为CNN卷积神经网络用MNIST数据集、sklearn数据集代码很多部分都很相似,这一篇就不附详细说明,源码最下。CNN卷积神经网络的工作原理,请详情参考——【深度学习】5:CNN卷积神经网络原理、MNIST数据集识别
–-----------------------------------------------------------------------------—--------------------------------------------------------—
–-----------------------------------------------------------------------------—--------------------------------------------------------—
一、卷积神经网络原理介绍
用CNN卷积神经网络识别图片,一般需要的步骤有:
- 卷积层初步提取特征
- 池化层提取主要特征
- 全连接层将各部分特征汇总
- 产生分类器,进行预测识别
1.1、卷积层工作原理
卷积层的作用:就是提取图片每个小部分里具有的特征
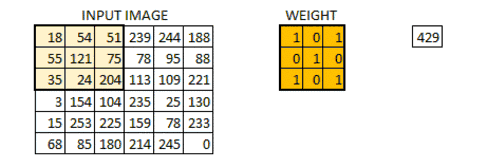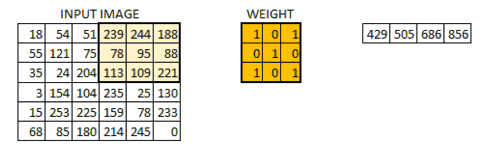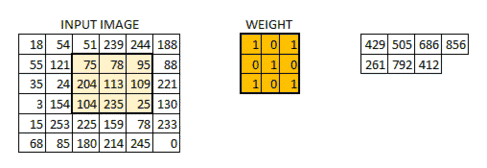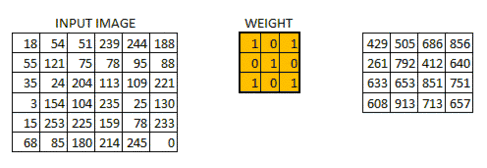
假定我们有一个尺寸为66 的图像,每一个像素点里都存储着图像的信息。我们再定义一个卷积核(相当于权重),用来从图像中提取一定的特征。卷积核与数字矩阵对应位相乘再相加,得到卷积层输出结果。
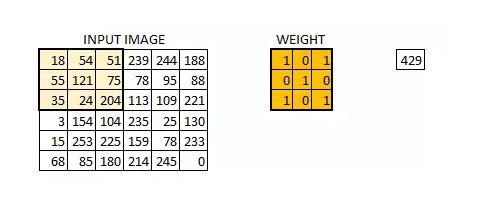
(429 = 181+540+511+550+1211+750+351+240+2041)
卷积核的取值在没有以往学习的经验下,可由函数随机生成,再逐步训练调整
当所有的像素点都至少被覆盖一次后,就可以产生一个卷积层的输出(下图的步长为1)
机器一开始并不知道要识别的部分具有哪些特征,是通过与不同的卷积核相作用得到的输出值,相互比较来判断哪一个卷积核最能表现该图片的特征——比如我们要识别图像中的某种特征(比如曲线),也就是说,这个卷积核要对这种曲线有很高的输出值,对其他形状(比如三角形)则输出较低。卷积层输出值越高,就说明匹配程度越高,越能表现该图片的特征。
卷积层具体工作过程:
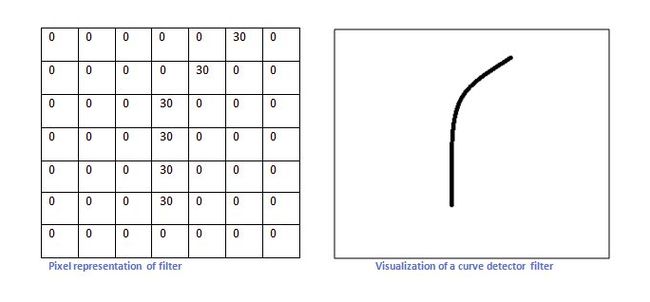
比如我们设计的一个卷积核如下左,想要识别出来的曲线如下右:
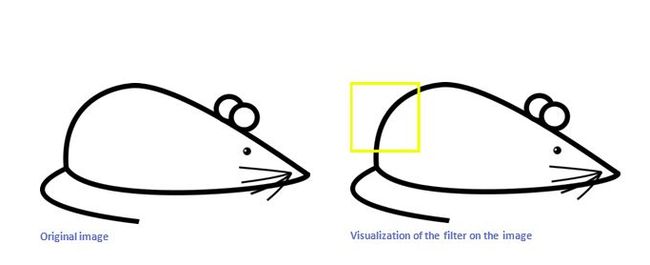
现在我们用上面的卷积核,来识别这个简化版的图片——一只漫画老鼠
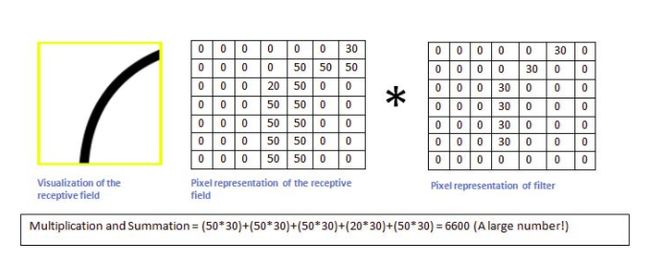
当机器识别到老鼠的屁股的时候,卷积核与真实区域数字矩阵作用后,输出较大:6600
而用同一个卷积核,来识别老鼠的耳朵的时候,输出则很小:0
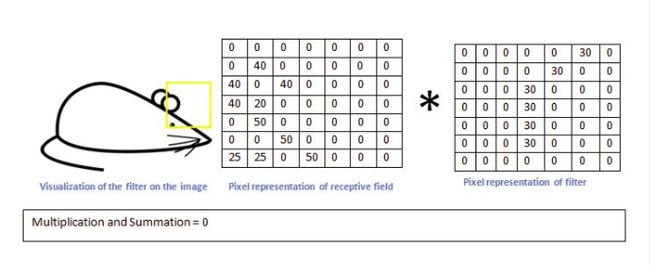
我们就可以认为:现有的这个卷积核保存着曲线的特征,匹配识别出来了老鼠的屁股是曲线的。我们则还需要其他特征的卷积核,来匹配识别出来老鼠的其他部分。卷积层的作用其实就是通过不断的改变卷积核,来确定能初步表征图片特征的有用的卷积核是哪些,再得到与相应的卷积核相乘后的输出矩阵
1.2、池化层工作原理
池化层的输入就是卷积层输出的原数据与相应的卷积核相乘后的输出矩阵
池化层的目的:
- 为了减少训练参数的数量,降低卷积层输出的特征向量的维度
- 减小过拟合现象,只保留最有用的图片信息,减少噪声的传递
最常见的两种池化层的形式:
- 最大池化:max-pooling——选取指定区域内最大的一个数来代表整片区域
- 均值池化:mean-pooling——选取指定区域内数值的平均值来代表整片区域
举例说明两种池化方式:(池化步长为2,选取过的区域,下一次就不再选取)
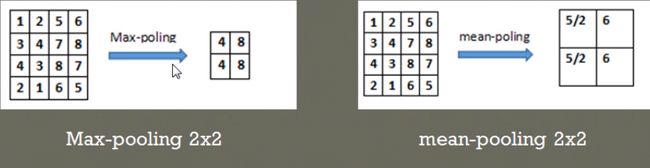
在44的数字矩阵里,以步长22选取区域,比如上左将区域[1,2,3,4]中最大的值4池化输出;上右将区域[1,2,3,4]中平均值5/2池化输出
1.3、全连接层工作原理
卷积层和池化层的工作就是提取特征,并减少原始图像带来的参数。然而,为了生成最终的输出,我们需要应用全连接层来生成一个等于我们需要的类的数量的分类器。
全连接层的工作原理和之前的神经网络学习很类似,我们需要把池化层输出的张量重新切割成一些向量,乘上权重矩阵,加上偏置值,然后对其使用ReLU激活函数,用梯度下降法优化参数既可。
二、卷积神经网络代码解析
2.1、数据集的读取,以及数据预定义
# 读取数据
digits = load_digits()
X_data = digits.data.astype(np.float32)
Y_data = digits.target.astype(np.float32).reshape(-1,1)
# 归一化处理:最小最大值标准化
X_data = MinMaxScaler().fit_transform(X_data)
# 转换为图片的格式 (batch,height,width,channels)
X = X_data.reshape(-1,8,8,1)
# 标签二值化:one-hot编码
Y = OneHotEncoder().fit_transform(Y_data).todense()
'''
#归一化的另一种方法
X_data -= X_data.min()
X_data /= X_data.max()
'''
- 数据为什么要归一化处理?当数据集的数值过大,即便乘以较小的权重后仍然还是一个很大的数时,当代入sigmoid激活函数中,激活函数的输出就趋近于1,不利于学习
- 怎么操作使数据归一化?原始数据集中每一个数据先减去最小的那个数,将得到的新数据集再除以最大的那个数既可(大家可以举个例子:2,7,5,9。试一试就知道)
- sklearn中直接一条语句就可以切分数据了:将数据项、标签项切分出来,3/4做训练集,剩下的1/4做测试集。
- 为什么要标签二值化?因为我们存入的标签是0,1,2,,,9这十个数,而计算机的识别都是0-1字符串,所以满足计算机识别分类,就需要进行标签二值化。
- 怎么标签二值化?举例最好说明:用长度为10的字符串表示如下:
0 –>1000000000;3 –>0001000000;8 –>0000000010
2.2、权重、偏置值函数
def get_weight(shape):
initial = tf.random_normal(shape)
return tf.Variable(initial)
def get_baise(shape):
initial = tf.random_normal(shape)
return tf.Variable(initial)
truncated_normal()函数:选取位于正态分布均值=0.1附近的随机值
2.3、卷积函数、池化函数定义
#stride = [1,水平移动步长,竖直移动步长,1]
def conv2d(x,W,strides=[1, 1, 1, 1]):
initial = tf.nn.conv2d(x,W,strides, padding='SAME')
return initial
# stride = [1,水平移动步长,竖直移动步长,1]
def max_pool_2x2(x):
initial = tf.nn.max_pool(x,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
return initial
- 输入x是图片信息矩阵,W是卷积核的值
- 卷积层conv2d()函数里strides参数要求第一个、最后一个参数必须是1;
- 第二个参数表示:卷积核每次向右移动的步长
- 第三个参数表示:卷积核每次向下移动的步长
在上面卷积层的工作原理中,有展示strides=[1, 1, 1, 1]的动态图,
下面展示strides=[1, 2, 2, 1]时的情况:可以看到高亮的区域每次向右移动两格,向下移动两格
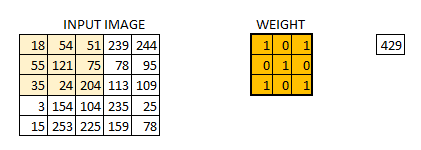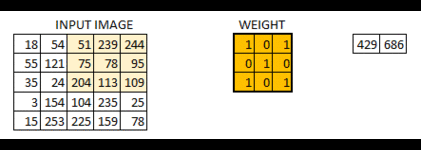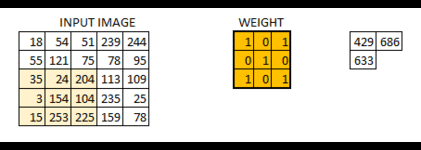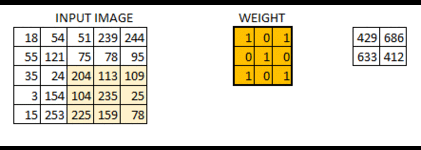
可以得到:当我们的卷积层步长值越大,得到的输出图像的规格就会越小。为了使得到的图像的规格和原图像保持一样的大,在输入图像四周填充足够多的 0 边界就可以解决这个问题,这时padding的参数就为“SAME”(利用边界保留了更多信息,并且也保留了图像的原大小)下图:
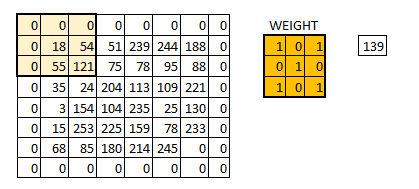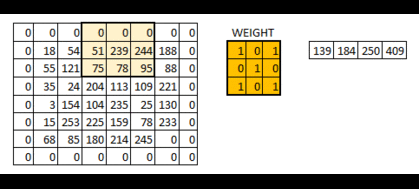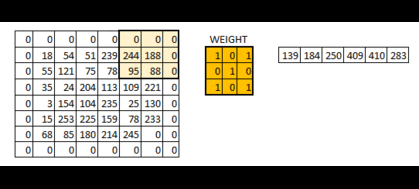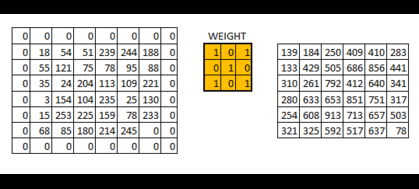
padding的另一个可选参数为“VALID”,和“SAME”不同的是:不用0来填充边界,这时得到的图像的规格就会小于原图像。新图像尺寸大小 = 原数据尺寸大小-卷积核尺寸大小+1(一般我们选用的padding都为“SAME”)
池化函数用简单传统的2x2大小的模板做max pooling,池化步长为2,选过的区域下次不再选取
2.4、第一次卷积+池化
# 卷积层1 + 池化层1
W_conv1 = get_weight([3, 3, 1, 10])
b_conv1 = get_baise([10])
h_conv1 = tf.nn.relu(conv2d(x, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
- 这里的卷积核大小是3*3的,输入的通道数是1,输出的通道数是10
- 卷积核的值这里就相当于权重值,用随机数列生成的方式得到
2.5、第二次卷积+池化
# 卷积层2
W_conv2 = get_weight([3, 3, 10, 5])
b_conv2 = get_baise([5])
h_conv2 = conv2d(h_conv1, W_conv2,strides=[1, 2, 2, 1]) + b_conv2
# BN归一化层 + 激活层
batch_mean, batch_var = tf.nn.moments(h_conv2, [0, 1, 2], keep_dims=True)
shift = tf.Variable(tf.zeros([5]))
scale = tf.Variable(tf.ones([5]))
BN_out = tf.nn.batch_normalization(h_conv2, batch_mean, batch_var, shift, scale,lr)
relu_BN_maps2 = tf.nn.relu(BN_out)
# 池化层2 + 全连接层1
h_pool2 = max_pool_2x2(relu_BN_maps2)
- 这里的卷积核大小也是3*3的,第二次输入的通道数是10,输出的通道数是5
2.6、全连接层1、全连接层2
# 全连接层1
h_pool2_flat = tf.reshape(h_pool2, [-1, 2*2*5])
W_fc = get_weight([2*2*5,50])
b_fc = get_baise([50])
fc_out = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc) + b_fc)
# 输出层
W_out = get_weight([50,10])
b_out = get_baise([10])
pred = tf.nn.softmax(tf.matmul(fc_out,W_out)+b_out)
- 全连接层的输入就是第二次池化后的输出,全连接层1有50个神经元
- 全连接层2有10个神经元,相当于生成的分类器
- 经过全连接层1、2,得到的预测值存入pred 中
2.7、梯度下降法优化、求准确率
# 计算误差、梯度下降法减小误差、求准确率
#loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=pred))
loss = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(pred,1e-11,1.0)))
train_step = tf.train.AdamOptimizer(1e-2).minimize(loss)
y_pred = tf.arg_max(pred,1)
bool_pred = tf.equal(tf.arg_max(y_,1),y_pred)
accuracy = tf.reduce_mean(tf.cast(bool_pred,tf.float32)) # 准确率
- 由于数据集太庞大,这里采用的优化器是AdamOptimizer,学习率是1e-4
- bool_pred 这里是返回一个布尔数组。为了计算我们分类的准确率,我们将布尔值转换为浮点数来代表对与错,然后取平均值。例如:[True, False, True, True]变为[1,0,1,1],计算出准确率就为0.75
三、源码以及准确率展示
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing
# -*- 2018/03/25 18:40
# -*- python3.5
"""
程序有时会陷入局部最小值,导致准确率在一定数值浮动,可以重新运行程序
"""
import pylab as pl
import numpy as np
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import OneHotEncoder
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
def get_batch(X,Y,n_examples, batch_size):
for batch_i in range(n_examples // batch_size):
start = batch_i*batch_size
end = start + batch_size
batch_xs = X[start:end]
batch_ys = Y[start:end]
yield batch_xs, batch_ys # 生成每一个batch
def get_weight(shape):
initial = tf.random_normal(shape)
return tf.Variable(initial)
def get_baise(shape):
initial = tf.random_normal(shape)
return tf.Variable(initial)
def conv2d(x,W,strides=[1, 1, 1, 1]):
initial = tf.nn.conv2d(x,W,strides, padding='SAME')
return initial
def max_pool_2x2(x):
initial = tf.nn.max_pool(x,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
return initial
lr = 1e-3
# 读取数据
digits = load_digits()
X_data = digits.data.astype(np.float32)
Y_data = digits.target.astype(np.float32).reshape(-1,1)
# 归一化处理:最小最大值标准化
X_data = MinMaxScaler().fit_transform(X_data)
# 转换为图片的格式 (batch,height,width,channels)
X = X_data.reshape(-1,8,8,1)
# 标签二值化:one-hot编码
Y = OneHotEncoder().fit_transform(Y_data).todense()
'''
#归一化的另一种方法
X_data -= X_data.min()
X_data /= X_data.max()
'''
# 预定义x,y_
x = tf.placeholder(tf.float32,[None,8,8,1])
y_ = tf.placeholder(tf.float32,[None,10])
# 卷积层1 + 池化层1
W_conv1 = get_weight([3, 3, 1, 10])
b_conv1 = get_baise([10])
h_conv1 = tf.nn.relu(conv2d(x, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 卷积层2
W_conv2 = get_weight([3, 3, 10, 5])
b_conv2 = get_baise([5])
h_conv2 = conv2d(h_conv1, W_conv2,strides=[1, 2, 2, 1]) + b_conv2
# BN归一化层 + 激活层
batch_mean, batch_var = tf.nn.moments(h_conv2, [0, 1, 2], keep_dims=True)
shift = tf.Variable(tf.zeros([5]))
scale = tf.Variable(tf.ones([5]))
BN_out = tf.nn.batch_normalization(h_conv2, batch_mean, batch_var, shift, scale,lr)
relu_BN_maps2 = tf.nn.relu(BN_out)
# 池化层2 + 全连接层1
h_pool2 = max_pool_2x2(relu_BN_maps2)
h_pool2_flat = tf.reshape(h_pool2, [-1, 2*2*5])
W_fc = get_weight([2*2*5,50])
b_fc = get_baise([50])
fc_out = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc) + b_fc)
# 输出层
W_out = get_weight([50,10])
b_out = get_baise([10])
pred = tf.nn.softmax(tf.matmul(fc_out,W_out)+b_out)
# 计算误差、梯度下降法减小误差、求准确率
#loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=pred))
loss = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(pred,1e-11,1.0)))
train_step = tf.train.AdamOptimizer(1e-2).minimize(loss)
y_pred = tf.arg_max(pred,1)
bool_pred = tf.equal(tf.arg_max(y_,1),y_pred)
accuracy = tf.reduce_mean(tf.cast(bool_pred,tf.float32)) # 准确率
'''
# 用下面的,准确率只在90%左右
correct_prediction = tf.equal(tf.argmax(pred,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
'''
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 迭代1000个周期,每个周期进行MBGD算法
for i in range(101):
for batch_xs,batch_ys in get_batch(X,Y,Y.shape[0],batch_size=8):
sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys})
if(i%10==0):
res = sess.run(accuracy,feed_dict={x:X,y_:Y})
print ("step",i, " training accuracy",res)
# 只能预测一批样本,不能预测一个样本
res_ypred = y_pred.eval(feed_dict={x: X, y_: Y}).flatten()
print('所有的预测标签值', res_ypred)
"""
# 下面是打印出前15张图片的预测标签值、以及第5张图片
print('预测标签', res_ypred[0:15])
pl.gray()
pl.matshow(digits.images[4])
pl.show()
"""
结果展示:
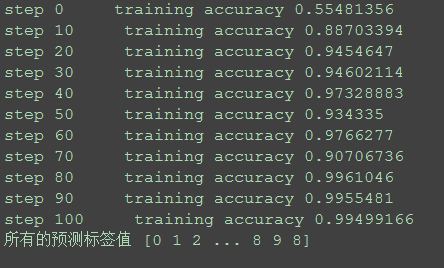
sklearn数据集中的图片大小都是8*8的,所以识别的速度、准确率都是比较高的
–-----------------------------------------------------------------------------—--------------------------------------------------------
–-----------------------------------------------------------------------------—--------------------------------------------------------
系列推荐:
【监督学习】1:KNN算法实现手写数字识别的三种方法
–-----------------------------------------------------------------------------—--------------------------------------------------------—----
【无监督学习】1:K-means算法原理介绍,以及代码实现
【无监督学习】2:DBSCAN算法原理介绍,以及代码实现
【无监督学习】3:Density Peaks聚类算法(局部密度聚类)
–-----------------------------------------------------------------------------—--------------------------------------------------------—----
【深度学习】1:感知器原理,以及多层感知器解决异或问题
【深度学习】2:BP神经网络的原理,以及异或问题的解决
【深度学习】3:BP神经网络识别MNIST数据集
【深度学习】4:BP神经网络+sklearn实现数字识别
【深度学习】5:CNN卷积神经网络原理、MNIST数据集识别
【深度学习】8:CNN卷积神经网络识别sklearn数据集(附源码)
【深度学习】6:RNN递归神经网络原理、MNIST数据集识别
【深度学习】7:Hopfield神经网络(DHNN)原理介绍
–-----------------------------------------------------------------------------—--------------------------------------------------------—----
TensorFlow框架简单介绍
–-----------------------------------------------------------------------------—--------------------------------------------------------—----