本文来自作者 一行 在 GitChat 分享的{分布式锁的技术选型及思考}
锁和分布式锁
在计算机中,锁的作用是解决在并发状态下的共享资源互斥问题,保证在同一时间只有一个进程/线程可以掌握资源的控制权。
例如以下几种情况:
文件锁的实现是为了解决不同用户同时读写同一文件的并发问题而出现的,防止导致文件的内容被破坏。
使用数组实现的队列,在 push 操作的地方一般需要加锁来解决槽位的争夺问题,防止出现多次 push 冲突从而导致数据丢失问题。
对于12306来说,火车票就是他的资源,最终放票的时候需要锁来保证票、人、座位唯一对应。
……
上面的例子中其实就包含了我们通常讲的传统单机锁和我要讲的分布式锁。
单机环境下,资源竞争者都是来自机器内部((进程/线程),那么实现锁的方案只需要借助单机资源就可以了,比如借助磁盘、内存、寄存器来实现。
但是对于分布式环境下,资源竞争者生存环境更复杂了,原有依赖单机的方案不再发挥作用,这时候就需要一个大家都认可的协调者出来,帮助解决竞争问题,那这个协调者称之为分布式锁。
上面这个例子就像两个职员产生的矛盾,只要公司的领导出面就可以解决。而当两个公司产生竞争矛盾的时候,就需要司法机关出面,是同一个道理。
简单的说,分布式锁就是解决分布式环境下资源竞争问题的手段。
分布式锁的应用场景
所有分布式环境下会出现资源竞争的地方都需要分布式锁的协调,除了上面介绍的 12306 放票,还有类似共享文档平台编辑问题、王者荣耀选择英雄、全局自增主键等应用需要用到。简单介绍一下在类似公司内部 Wiki 等多人协作编辑平台的使用场景。
Wiki 中的多人在线编辑
场景1:清明节前,团队要求我们在 Wiki 登记自己的休假情况,假设我们在 id=1 这个文档上记录我们的休假时间和联系电话。A、C 两个同学同时开始编辑,并且 A 和 C 在同一时间提交了结果,他们在提交前文档是空的。服务需要如何处理这两个请求呢?以谁的为准呢?会不会产生覆盖现象导致 A 的记录丢失了?
场景2:另一个 case,我是 Z 同学,在我前面别人都已经填完了,我有一个陋习,喜欢在保存的时候连续按3-5下 Ctrl+s,而每一个 Ctrl+s 都会触发一个请求,但是每个请求处理大概1s钟,但是实际请求都在 20ms 内发出去了。
问题同上面,如何保证不重复的追加记录呢?
假设你的存储服务和存储架构是这样的:

一般的处理代码是这样的:
//根据docid获取文件内容,从分布式文件系统取,时间不可控 nowFileContent = getFileByDocId(docId) //do something,类似diff,追加操作 newFileContent = doSomeThing() //存储到文件系统 setNewFileContent(docId,newFileContent)
对于场景1讲到的 A、C 两个请求同时到达代码段,但是由于网络原因,A 先拿到文档内容,C 在 A 写入前读到文件内容,所以最终的结果是两者会丢失一个写入。

所以需要对读写操作做一次加锁,保证事务的完整、一致。
下图是《现代操作系统》中的插图,这里的效果也希望如此。

Wiki 这类场景属于长耗时事务的资源处理问题,锁的出现保证不会因为事务中的读写间跨度耗时大导致写覆盖的情况,使得请求排队,顺序处理。
解决方案选择
我遇到的问题也是类 Wiki 这类长事务的问题,遇到问题第一想法是去看网上的解决方案。
网上 MySQL、ZK、Redis 各种实现方式很多,我需要选择哪种?怎么选择?我需要权衡哪些方面?
以前看分布式书的时候,一个被提到很多次的词是:trade-off,我理解是取舍或者是权衡吧。
作为一个 Web 开发者,我需要考虑的主要包含下面几个部分:
实现我的功能是否 OK,耗时是否满足在线需求?
实现难度、学习成本;
运维成本。
那么按照这几个标准来看一下现在的可选方案:
| 实现方式 | 功能要求 | 实现难度 | 学习成本 | 运维成本 |
|---|---|---|---|---|
| MySQL 的方案借助表锁/行锁实现 | 满足基本要求 | 不难 | 熟悉 | 小量OK、大量影响现有业务、1主多从架构,不方便扩容 |
| 通过 ZK 创建数据节点的方式实现 | 满足要求 | 熟悉 ZK API 即可 | 需要学习 | 重,需要堆机器,有跨机房请求 |
| Redis 使用 setnxex | 基本要求 | 不难 | 熟悉 | 扩容方便、现有服务 |
MySQL 单主架构,写都会到 master,有瓶颈。ZK 的方式需要自己搭建、运维,而且需要堆机器,利用率不高。最终采用了 Redis 来实现,流量/存储都可以扩容,运维也不需要自己。
实现
选好了方案,下面就是实现了。如果我们最终实现了这个锁,对它的要求是什么呢?
lock 实现必须要是原子操作,同时保证任何时候只有一个竞争者是独占的;
unlock 必须是原子的,同时保证只有自己可以解锁自己;
不能出现死锁,当进程挂掉之后不影响其他的加锁行为;
支持 Twemproxy 模式下的架构和单机;
耗时可以接受。
基于上述要求我的实现如下(只提供了大致,删除了敏感信息):
_objRedis = RedisFactory::getRedis(); $this->_redisKey = self::COMMON_REDISKEY_PREFIX.$ukey; $this->_unLockTime = $unlockTime ; //为单次加锁生成唯一guid $this->_guid = genGuid(); } /** * @brief 对给定的key进行加锁处理 * * @return * * true 表示加锁成功 * * 抛出异常则表示加锁未成功,根据业务选择自己的care的级别 * 异常错误码 : * 1.网络错误: ErrorCodes::REDIS_ERROR 视业务严谨度,这个错误是否忽略 * 2.锁被占用: ErrorCodes::LOCK_IS_USED 明确确定锁被别人占有 */ public function lock(){ /* * 设置锁的过程需要是原子的,所以采用了set来操作 * SET key value [EX seconds] [PX milliseconds] [NX|XX] * Redis 2.6.12 版本开始支持通过set 指定参数完成setexnx功能 * * php 语法 : $redis->set('key', 'value', Array('xx', 'px'=>1000)); * */ $setRet = $this->_objRedis->set($this->_redisKey,$this->_guid,array('nx', 'ex' => $this->_unLockTime)); //返回false表示请求锁失败 if(false === $setRet){ //锁被占用,抛异常 throw new Exception("get Lock Failed!Locking",Constants_ErrorCodes::LOCK_IS_USED); } //redis返回null,是网络、机器授权、语法错误等等 if(is_null($setRet)){ //网络错误、异常 throw new Exception("Request Redis Failed",Constants_ErrorCodes::REDIS_ERROR); } return $setRet ; } /** * @brief 解除对某个key的锁定,原则上不需要关心返回值,可以多次调用 * * @return * 1 redis会话成功,并且成功删除了key * 0 redis会话成功,但是待删除的key已经不存在 * */ public function unlock(){ //Reids 2.6 版本增加了对 Lua 环境的支持,解决了长久以来不能高效地处理 CAS (check-and-set)命令的缺点 $luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end" ; $delRet = $this->_objRedis->eval($luaScript,array($this->_redisKey,$this->_guid),1); if(is_null($delRet)){ //redis返回null,是网络、机器授权、语法错误等等 throw new Exception("Request Redis Failed",Constants_ErrorCodes::REDIS_ERROR); } return $delRet ; } }
代码写出来之后是否解决了上面的问题呢?我们来看一下单机和集群 Redis 方案下的使用。
单机 Redis 架构

对于上图的单点架构,读写不分离。
那么上面的代码对于上面要求是否满足?
lock 采用了set + nx + ex 参数 + redis 单线程可以保证 lock 是个原子操作,加锁成功即成功,失败即失败,满足要求1和要求3死锁处理,超时 key 失效;
unlock 采用 Lua 保证了 compare and del 这个操作是原子的,同时解决了自己删除自己的需求;
耗时上呢?都是一次请求,可以接受,同机房在 ms 级。
Twemproxy 模式下的多地域多分片主从架构
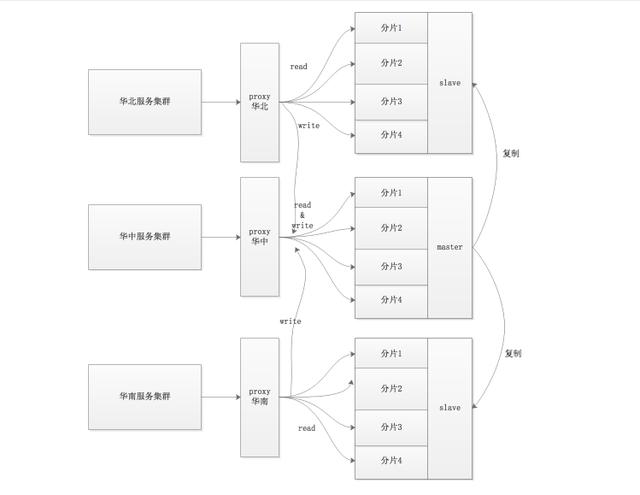
Twemproxy 是对 Redis/Memcache 的代理,主要负责根据 key 路由到分片的功能,存在它不支持的操作,例如 keys *。不支持的原因是它需要遍历所有分片才能完成操作,对于简单的 set/get 还是路由到相应的分片,工作原理一致。
对于 Lua 脚本呢? Lua 脚本是怎么路由的?支持吗?
我们使用 eval 来执行的时候,我发现我们集群的文档里这么写:
必须至少有一个 key 在 script 后面。命令将发往第一个 key 所在的分片。
也就是说使用 eval 来完成工作,命令是发向第一个 key 的,而我们的第一个 key 就是我们要处理的 key,所以这套代码在集群模式也是支持的。
但是对于集群来说,现在都是采用的最终一致性、单地域主多地域从、写走主地域的模式。
那么就是说写请求是跨地域的?这个我使用了多一步操作读来优化,因为读不跨地域、写跨地域,但是99%以上的请求主从延时都没这么大,当然99%这个比例是我猜测的。
具体代码如下:
function lock(){ //首先采用exist来看指定key是不是存在了 if($objRedis->exist($key)){ //key存在一定是被占了,抛异常 } //if not exist,并不能代表这个锁真的没被占用,可能是主从延时,这时候复用上面的代码更安全,减少一次跨机房写}
使用注意事项如下:
使用时候需要控制好自己的 lockTime,需要长于你的事务执行时间;
上层在获取锁失败的时候,需要自己去选择是阻塞还是抛弃这次请求,让用户端重试。
目前待解决问题有:
如果你的进程因为 CUP 吃紧而被挂起,而且挂起的时间超过了你设置的锁的失效时间,是不是仍然会出现问题?
如果集群模式一个分片挂了,会发生什么?
你有什么办法解决吗?欢迎留言讨论。
总结
总结一下我这次的分享,主要有以下几点总结:
分布式锁是指分布式业务环境下需要的锁,对支持锁的服务没有要求要分布式;
锁实际上是一个资源协调者的角色,管理并发态下的资源控制权;
方案选择就像投资,需要考虑投入产出比;
Redis 单机和集群方案有自己的优化点,根据场景做优化;
在写完文章后发现我的题目有点问题,更准确的叫法应该是《 Redis 实现分布式锁的思考》,如果骗了你,请告诉我。
参考
吴大山的博客 :提醒了我解铃还需系铃人(Lua脚本)
Twemproxy:Twemproxy 的代码,我没看完,但是搭建了服务测试。
架构技术是程序员绕不开的话题,关于分布式,微服务,源码,框架结构,设计模式等这些技术我都分享在群619881427,可免费下载。希望可以帮助在这个行业发展的朋友和童鞋们,在论坛博客等地方少花些时间找资料,把有限的时间,真正花在学习上,我把这些视频分享出来。相信对于已经工作和遇到技术瓶颈的码友,在这个群里一定有你需要的内容。