Spark Broadcast中writeBlocks为啥put两次?
Spark Broadcast中writeBlocks为啥put两次?
- 1 broadcast
- 2 剖析putSingle与putBytes
- 2.1 blockManager.putSingle
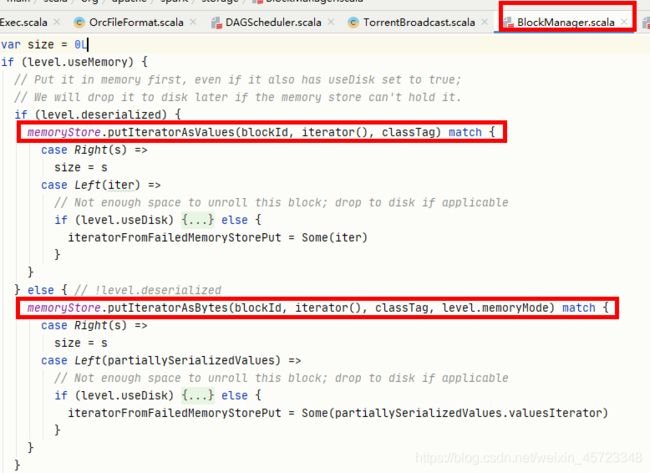
- memoryStore.putIteratorAsValues
- memoryStore.putIteratorAsBytes
- memoryStore.putBytes
- 3 总结
有兄弟在看代码的时候发现一个现象,在TorrentBroadcast广播实现类中为啥wirteBlocks方法中会向BlockManager put两次值呢?
现象如下所示:

要解释上面的问题,我需要从三个方面做详细描述:
- 解释什么是broadcast;
- 剖析putSingle与putBytes;
- 跑个例子来总结一下具体现象;
1 broadcast
什么是broadcast?
顾名思义,broadcast 就是将数据从一个节点发送到其他各个节点上去。这样的场景很多,比如 driver 上有一张表,其他节点上运行的 task 需要 lookup 这张表,那么 driver 可以先把这张表 copy 到这些节点,这样 task 就可以在本地查表了。
官方定义:
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used, for example, to give every node a copy of a large input dataset in an efficient manner. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost.
先回答下面几个问题就会明白什么是broadcast:
1、在spark什么东西能广播呢?换句话说广播有什么用呢?
Spark中因为算子中的真正逻辑是发送到Executor中去运行的,所以当Executor中需要引用外部变量时,需要使用广播变量。
–变量参数可以被广播,比如FileSourceScanExec在构造inputRDD时调用到OrcFileFormat#buildReaderWithPartitionValues内部就会将HadoopConf进行广播,如下图所示:
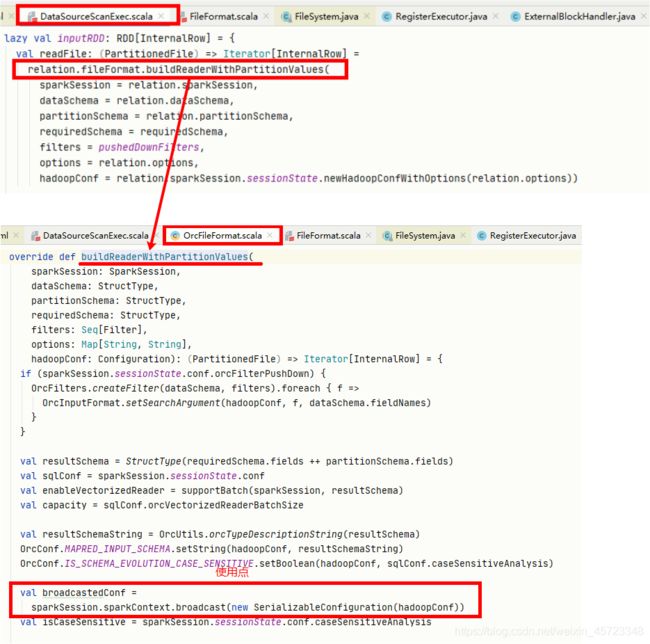
– 在提交任务之前会将序列化好的***task可以进行广播***,DAGScheduler#submitMissingTasks,如下图所示:
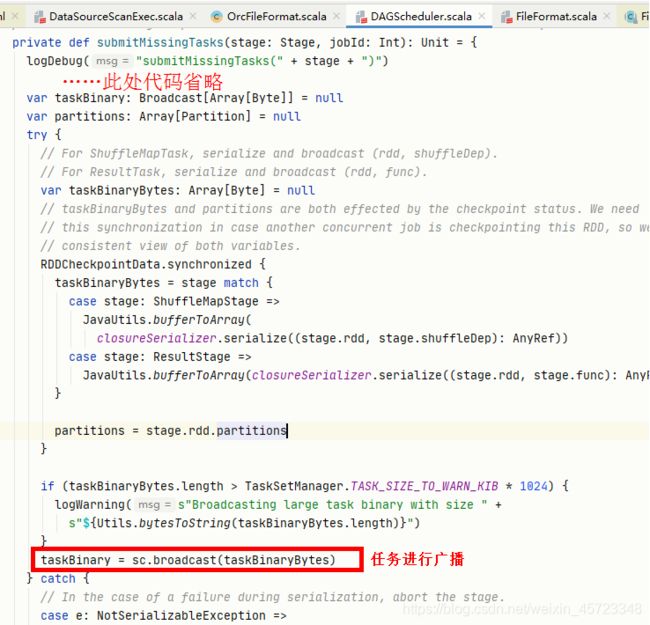
2、broadcast 到节点而不是 broadcast 到每个 task?
因为每个 task 是一个线程,而且同在一个进程运行 tasks 都属于同一个 application。因此每个节点(executor)上放一份就可以被所有 task 共享。
3、怎么实现 broadcast?
分发task时先分发的是data的元数据 ? 当调用val bdata= sc.broadcast(data)时就把 data 写入文件夹(Driver 先建一个本地文件夹用以存放需要 broadcast 的 data),同时写入 driver 自己的 blockManger 中(StorageLevel 为MEMORY_AND_DISK**),获得一个 blockId,类型为 BroadcastBlockId。当调用rdd.transformation(func)时,如果 func 用到了 data,那么 driver submitTask() 的时候会将 data 一同 func 进行序列化得到 serialized task,注意序列化的时候不会序列化bdata中包含的 data。
什么时候传送真正的 data?在 executor 反序列化 task 的时候,会同时反序列化 task 中的 bdata 对象,这时候会调用 bdata 的 readObject() 方法。该方法先去本地 blockManager 那里询问 bdata 的 data 在不在 blockManager 里面,如果不在就使用下面TorrentBroadcast** fetch 方式之一去将 data fetch 过来。得到 data 后,将其存放到 blockManager 里面,这样后面运行的 task 如果需要 bdata 就不需要再去 fetch data 了。如果在,就直接拿来用了。
4、TorrentBroadcast是个啥?
TorrentBroadcast,这个类似于大家常用的BitTorrent 技术,基本思想就是将 data 分块成 data blocks,然后假设有 executor fetch 到了一些 data blocks,那么这个 executor 就可以被当作 data server 了,随着 fetch 的 executor 越来越多,有更多的 data server 加入,data 就很快能传播到全部的 executor 那里去了。
在 TorrentBroadcast 里面使用blockManager.getRemote() => NIO ConnectionManager 传数据的方法来传递。
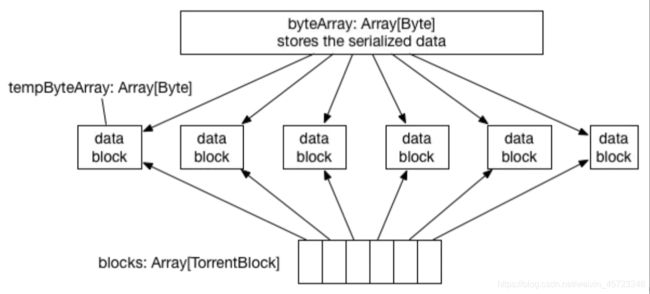
行了上面哔哔了那么多,很多兄弟肯定看得概念性的东西难受,不多说了,咱们撸一把代码,来点儿真实的,看看细节是如何实现的。
2 剖析putSingle与putBytes
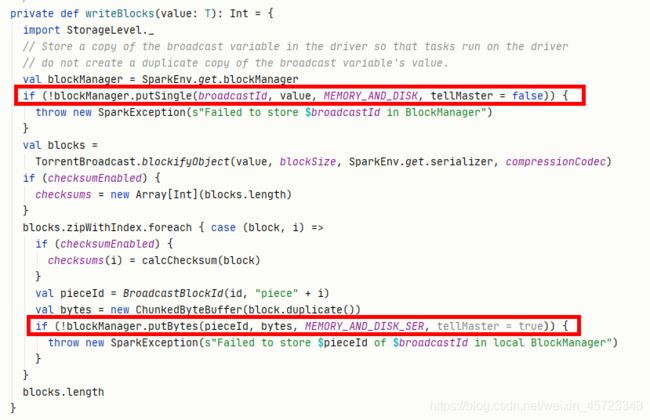
此方法的来源是什么?当然是Driver端发起,以提交任务为例子来看一下主线流程:
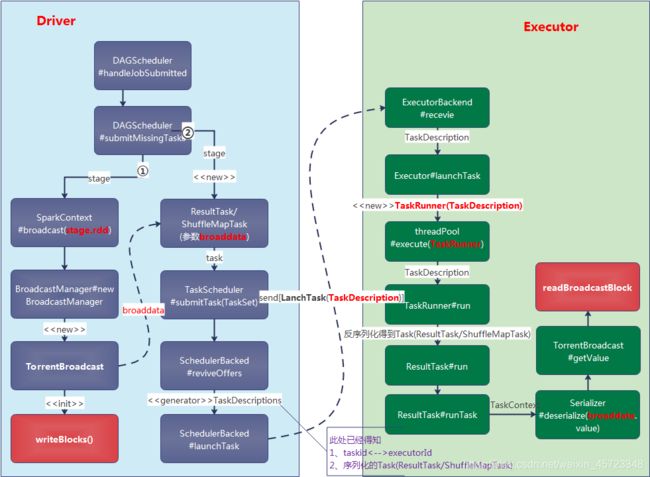
Driver端:先把 data 序列化到 byteArray,然后切割成 BLOCK_SIZE(由 spark.broadcast.blockSize = 4MB 设置)大小的 data block,完成分块切割后,就将分块信息(称为 meta 信息)存放到 driver 自己的 blockManager 里面,StorageLevel 为内存+磁盘,同时会通知 driver 自己的 blockManagerMaster 说 meta 信息已经存放好。
blockManager.putSingle(broadcastId, value, MEMORY_AND_DISK, tellMaster = false)
blockManager.putBytes(pieceId, bytes, MEMORY_AND_DISK_SER, tellMaster = true)
代码中tellMaster=true则会通知blockManagerMaster。通知 blockManagerMaster 这一步很重要,因为 blockManagerMaster 可以被 driver 和所有 executor 访问到,信息被存放到 blockManagerMaster 就变成了全局信息。
之后将每个分块 data block 存放到 driver 的 blockManager 里面,StorageLevel 为内存+磁盘。存放后仍然通知 blockManagerMaster 说 blocks 已经存放好。
Driver 端将serialized task按相应的调度策略(目前有FIFO,FAIR)分发到不同的Executor上执行,向相应的Executor发送【LaunchTask】命令,通知Executor可以执行任务。此时Driver的任务已经完成。
Executor端: 接收【LaunchTask】命令,则开始将 serialized task ,先反序列化 task,这时候会反序列化 serialized task 中包含有driver端为此任务构造好的broaddata,类型是 TorrentBroadcast,也就是去调用 Serialiser.readObject()。这个方法首先得到 broaddata对象,**然后发现broaddata 里面没有包含实际的 data。怎么办?**TorrentBroadcast#readBroadcastBlock方法先询问所在的 executor 里的 blockManager 是会否包含 data(通过查询 data 的 broadcastId),包含就直接从本地 blockManager 读取 data。否则,就通过本地 blockManager 去连接 driver 的 blockManagerMaster 获取 data 分块的 meta 信息,获取信息后,就开始了fetch datablocks 过程,执行真正的func流程。
其实到这里已经初步回答了为什么会调用两次的问题了,第一次调用仅仅是Driver端内部缓存block并没有通知 blockManagerMaster,但第二次则通知 blockManagerMaster(tellMaster=true)。但是具体细节是什么呢?下面两个小章节细细剖析一下put的细节。
2.1 blockManager.putSingle
blockManager.putSingle()按存储级别为序列化与非序列化分成两种处理流程:
- 非序列化:memoryStore.putIteratorAsValues
- 序列化:memoryStore.putIteratorAsBytes
memoryStore.putIteratorAsValues
这个方法主要是用于存储级别是非序列化的情况,即直接以java对象的形式将数据存放在jvm堆内存上。我们都知道,在jvm堆内存上存放大量的对象并不是什么好事,gc压力大,挤占内存,可能引起频繁的gc,但是也有明显的好处,就是省去了序列化和反序列化耗时,而且直接从堆内存取数据显然比任何其他方式(磁盘和直接内存)都要快很多,所以对于内存充足且要缓存的数据量本省不是很大的情况,这种方式也不失为一种不错的选择。
private[storage] def putIteratorAsValues[T](
blockId: BlockId,
values: Iterator[T],
classTag: ClassTag[T]): Either[PartiallyUnrolledIterator[T], Long] = {
// 用于存储java对象的容器,
val valuesHolder = new DeserializedValuesHolder[T](classTag)
putIterator(blockId, values, classTag, MemoryMode.ON_HEAP, valuesHolder) match {
// 存储成功
case Right(storedSize) => Right(storedSize)
// 存储失败的情况
case Left(unrollMemoryUsedByThisBlock) =>
// ValuesHolder内部的数组和vector会相互转换
// 数据写入完成后会将vector中的数据转移到数组中
val unrolledIterator = if (valuesHolder.vector != null) {
valuesHolder.vector.iterator
} else {
valuesHolder.arrayValues.toIterator
}
// 返回写入一半的迭代器、
// 外部调用者一半会选择关闭这个迭代器以释放被使用的内存
Left(new PartiallyUnrolledIterator(
this,
MemoryMode.ON_HEAP,
unrollMemoryUsedByThisBlock,
unrolled = unrolledIterator,
rest = values))
}
}
memoryStore.putIteratorAsBytes
看另一个方法。套路基本和putIteratorAsValues是一样一样的。
最大的区别在于ValuesHolder类型不同。非序列化形式存储使用的是DeserializedMemoryEntry,而序列化形式存储使用的是SerializedMemoryEntry。
private[storage] def putIteratorAsBytes[T](
blockId: BlockId,
values: Iterator[T],
classTag: ClassTag[T],
memoryMode: MemoryMode): Either[PartiallySerializedBlock[T], Long] = {
require(!contains(blockId), s"Block $blockId is already present in the MemoryStore")
// Initial per-task memory to request for unrolling blocks (bytes).
val initialMemoryThreshold = unrollMemoryThreshold
// 字节数组的块大小,默认是1m
val chunkSize = if (initialMemoryThreshold > Int.MaxValue) {
logWarning(s"Initial memory threshold of ${Utils.bytesToString(initialMemoryThreshold)} " +
s"is too large to be set as chunk size. Chunk size has been capped to " +
s"${Utils.bytesToString(Int.MaxValue)}")
Int.MaxValue
} else {
initialMemoryThreshold.toInt
}
// 字节数组的容器
val valuesHolder = new SerializedValuesHolder[T](blockId, chunkSize, classTag,
memoryMode, serializerManager)
putIterator(blockId, values, classTag, memoryMode, valuesHolder) match {
case Right(storedSize) => Right(storedSize)
case Left(unrollMemoryUsedByThisBlock) =>
// 部分展开,部分以序列化形式存储的block
Left(new PartiallySerializedBlock(
this,
serializerManager,
blockId,
valuesHolder.serializationStream,
valuesHolder.redirectableStream,
unrollMemoryUsedByThisBlock,
memoryMode,
valuesHolder.bbos,
values,
classTag))
}
}
上面两个方法都调用了MemoryStore.putIterator方法,这个方法主要做的事就是把数据一条一条往ValuesHolder中写,并周期性地检查内存,如果内存不够就通过内存管理器MemoryManager申请内存,每次申请当前内存量的1.5倍。
最后,将ValuesHolder中的数据转移到一个数组中(其实数据在SizeTrackingVector中也是以数组的形式存储,更为关键的是需要将存储的数据以统一的接口进行包装,以利于MemoryStore进行同一管理)。最后还有关键的一步,就是释放展开内存,重新申请存储内存。
UnrollMemory的申请主要方法如下:
memoryManager.acquireUnrollMemory(blockId, memory, memoryMode)
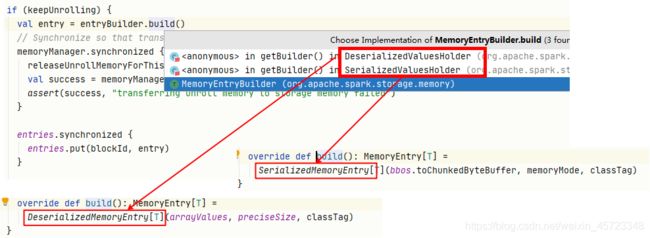
//MemoryStore类
// Note: all changes to memory allocations, notably putting blocks, evicting blocks, and
// acquiring or releasing unroll memory, must be synchronized on `memoryManager`!
private val entries = new LinkedHashMap[BlockId, MemoryEntry[_]](32, 0.75f, true)
按不同的存储形式,分成不同的处理流程:
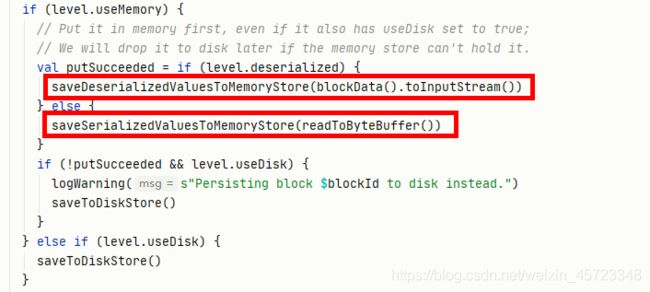
saveSerializedValuesToMemoryStore方法中根据不同的memoryMode看是在堆内还是堆外申请空间。此处调到了memoryStore.putBytes。
memoryStore.putBytes
def putBytes[T: ClassTag](
blockId: BlockId,
size: Long,
memoryMode: MemoryMode,
_bytes: () => ChunkedByteBuffer): Boolean = {
require(!contains(blockId), s"Block $blockId is already present in the MemoryStore")
// 首先向内存管理器申请内存
// 这里申请的是存储内存,因为要插入的字节数组,
// 所以不需要再展开,也就不需要申请展开内存
if (memoryManager.acquireStorageMemory(blockId, size, memoryMode)) {
// We acquired enough memory for the block, so go ahead and put it
val bytes = _bytes()
assert(bytes.size == size)
// 这里直接构建了一个SerializedMemoryEntry 并放到map中管理起来
val entry = new SerializedMemoryEntry[T](bytes, memoryMode, implicitly[ClassTag[T]])
entries.synchronized {
entries.put(blockId, entry)
}
logInfo("Block %s stored as bytes in memory (estimated size %s, free %s)".format(
blockId, Utils.bytesToString(size), Utils.bytesToString(maxMemory - blocksMemoryUsed)))
true
} else {
false
}
}
此处直接申请内存memoryManager.acquireStorageMemory(blockId, size, memoryMode),直接将构造好的SerializedMemoryEntry插入到上一章节提到的entries(LinkedHashMap[BlockId, MemoryEntry[_]])中。
再次看看这两个方法有什么不同,此处LinkedHashMap[BlockId, MemoryEntry[_]]中存的值不同,下图为一个例子跑出的结果截图:
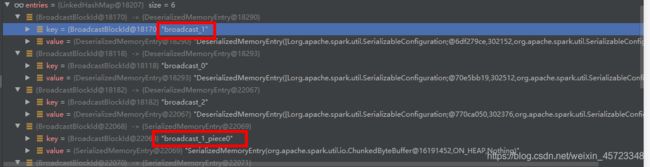
可以看到putSingle方法出来的key=broadcast_1,putBytes方法出来的key=broadcast_1_piece0。
3 总结
为什么不同呢?
putSingle方法处理完值仅仅是Driver端可用,并没有通知BlockManagerMaster可用,putBytes方法处理完的值已经是一块一块的broad-piece的值,也已经通知BlockManagerMaster可用,可以被其他Executor读取过来使用。
此处希望能帮助到不是很懂broadcast以及memorystore.put方法的同学们。
参考引用:
[1] https://blog.csdn.net/qq_31573519/article/details/82431352.
[2] https://www.cnblogs.com/zhuge134/p/11006860.html