本文阿宝哥会为小伙伴们隆重介绍用于图片处理的十个 “小帮手”,他们各个身怀绝技,拥有模糊、压缩、裁剪、旋转、合成、比对等技能。相信认识他们之后,你将能够轻松应对大多数的图片处理场景。
不过在介绍 “小帮手” 前,阿宝哥会先介绍一些图片相关的基础知识。此外,为了让小伙伴们能够学习更多图片相关的知识,阿宝哥精心准备了 “阿宝哥有话说” 章节。该章节你将会学到以下知识:
- 如何区分图片的类型(非文件后缀名);
- 如何获取图片的尺寸(非右键查看图片信息);
- 如何预览本地图片(非图片阅读器);
- 如何实现图片压缩(非图片压缩工具);
- 如何操作位图像素数据(非 PS 等图片处理软件);
- 如何实现图片隐写(非肉眼可见)。
十个图片处理 “小帮手” 已经已经迫不及待想与你见面,还在犹豫什么?赶紧出发吧!
一、基础知识
1.1 位图
位图图像(bitmap),亦称为点阵图像或栅格图像,是由称作像素(图片元素)的单个点组成的。 这些点可以进行不同的排列和染色以构成图样。当放大位图时,可以看见赖以构成整个图像的无数单个方块。扩大位图尺寸的效果是增大单个像素,从而使线条和形状显得参差不齐。
用数码相机拍摄的照片、扫描仪扫描的图片以及计算机截屏图等都属于位图。 位图的特点是可以表现色彩的变化和颜色的细微过渡,产生逼真的效果,缺点是在保存时需要记录每一个像素的位置和颜色值,占用较大的存储空间。常用的位图处理软件有 Photoshop、Painter 和 Windows 系统自带的画图工具等。
分辨率是位图不可逾越的壁垒,在对位图进行缩放、旋转等操作时,无法生产新的像素,因此会放大原有的像素填补空白,这样会让图片显得不清晰。
(图片来源:https://zh.wikipedia.org/wiki...)
图中的小方块被称为像素,这些小方块都有一个明确的位置和被分配的色彩数值,小方格颜色和位置就决定该图像所呈现出来的样子。
可以将像素视为整个图像中不可分割的单位或者是元素。不可分割的意思是它不能够再切割成更小单位抑或是元素,它是以一个单一颜色的小格存在。 每一个点阵图像包含了一定量的像素,这些像素决定图像在屏幕上所呈现的大小。
1.2 矢量图
所谓矢量图,就是使用直线和曲线来描述的图形,构成这些图形的元素是一些点、线、矩形、多边形、圆和弧线等,它们都是通过数学公式计算获得的,具有编辑后不失真的特点。 例如一幅画的矢量图形实际上是由线段形成外框轮廓,由外框的颜色以及外框所封闭的颜色决定画显示出的颜色。
矢量图以几何图形居多,图形可以无限放大,不变色、不模糊。 常用于图案、标志、VI、文字等设计。常用软件有:CorelDraw、Illustrator、Freehand、XARA、CAD 等。
这里我们以 Web 开发者比较熟悉的 SVG(Scalable Vector Graphics —— 可缩放矢量图形)为例,来了解一下 SVG 的结构:

可缩放矢量图形(英语:Scalable Vector Graphics,SVG)是一种基于可扩展标记语言(XML),用于描述二维矢量图形的图形格式。SVG 由 W3C 制定,是一个开放标准。
SVG 主要支持以下几种显示对象:
- 矢量显示对象,基本矢量显示对象包括矩形、圆、椭圆、多边形、直线、任意曲线等;
- 嵌入式外部图像,包括 PNG、JPEG、SVG 等;
- 文字对象。
了解完位图与矢量图的区别,下面我们来介绍一下位图的数学表示。
1.3 位图的数学表示
位图的像素都分配有特定的位置和颜色值。每个像素的颜色信息由 RGB 组合或者灰度值表示。
根据位深度,可将位图分为1、4、8、16、24 及 32 位图像等。每个像素使用的信息位数越多,可用的颜色就越多,颜色表现就越逼真,相应的数据量越大。
1.3.1 二值图像
位深度为 1 的像素位图只有两个可能的值(黑色和白色),所以又称为二值图像。二值图像的像素点只有黑白两种情况,因此每个像素点可以由 0 和 1 来表示。
比如一张 4 * 4 二值图像:
1 1 0 1
1 1 0 1
1 0 0 0
1 0 1 01.3.2 RGB 图像
RGB 图像由三个颜色通道组成,其中 RGB 代表红、绿、蓝三个通道的颜色。8 位/通道的 RGB 图像中的每个通道有 256 个可能的值,这意味着该图像有 1600 万个以上可能的颜色值。有时将带有 8 位/通道(bpc)的 RGB 图像称作 24 位图像(8 位 x 3 通道 = 24 位数据/像素)。通常将使用 24 位 RGB 组合数据位表示的的位图称为真彩色位图。
RGB 彩色图像可由三种矩阵表示:一种代表像素中红色的强度,一种代表绿色,另一种代表蓝色。

(图片来源:https://freecontent.manning.c...)
图像处理的本质实际上就是对这些像素矩阵进行计算。 其实位图中的图像类型,除了二值图像和 RGB 图像之外,还有灰度图像、索引图像和 YUV 图像。这里我们不做过多介绍,感兴趣的小伙伴,可以自行查阅相关资料。
二、图片处理库
2.1 AlloyImage
基于 HTML 5 的专业级图像处理开源引擎。
AlloyImage 基于 HTML5 技术的专业图像处理库,来自腾讯 AlloyTeam 团队。它拥有以下功能特性:
- 基于多图层操作 —— 一个图层的处理不影响其他图层;
- 与 PS 对应的 17 种图层混合模式 —— 便于 PS 处理教程的无缝迁移;
- 多种基本滤镜处理效果 —— 基本滤镜不断丰富、可扩展;
- 基本的图像调节功能 —— 色相、饱和度、对比度、亮度、曲线等;
- 简单快捷的 API —— 链式处理、API 简洁易用、传参灵活;
- 多种组合效果封装 —— 一句代码轻松实现一种风格;
- 接口一致的单、多线程支持 —— 单、多线程切换无需更改一行代码,多线程保持快捷 API 特性。
对于该库 AlloyTeam 团队建议的使用场景如下:
- 桌面软件客户端内嵌网页运行方式 >>> 打包 Webkit 内核:用户较大头像上传风格处理、用户相册风格处理(处理时间平均 < 1s);
- Win8 Metro 应用 >>> 用户上传头像,比较小的图片风格处理后上传(Win8 下 IE 10 支持多线程);
- Mobile APP >>> Andriod 平台、iOS 平台小图风格 Web 处理的需求,如 PhoneGap 应用,在线头像上传时的风格处理、Mobile Web 端分享图片时风格处理等。
使用示例
// $AI或AlloyImage初始化一个AlloyImage对象
var ps = $AI(img, 600).save('jpg', 0.6);
// save将合成图片保存成base64格式字符串
var string = AlloyImage(img).save('jpg', 0.8);
// saveFile将合成图片下载到本地
img.onclick = function(){
AlloyImage(this).saveFile('处理后图像.jpg', 0.8);
}http://alloyteam.github.io/Al...

(图片来源:http://alloyteam.github.io/Al...)
2.2 blurify
blurify.js is a tiny(~2kb) library to blurred pictures, support graceful downgrade fromcssmode tocanvasmode.
blurify.js 是一个用于图片模糊,很小的 JavaScript 库(约 2 kb),并支持从 CSS 模式到 Canvas 模式的优雅降级。该插件支持三种模式:
- css 模式:使用
filter属性,默认模式; - canvas 模式:使用
canvas导出 base64; - auto 模式:优先使用 css 模式,否则自动切换到 canvas 模式。
使用示例
import blurify from 'blurify';
new blurify({
images: document.querySelectorAll('.blurify'),
blur: 6,
mode: 'css',
});
// or in shorthand
blurify(6, document.querySelectorAll('.blurify'));https://justclear.github.io/b...

(图片来源:https://justclear.github.io/b...)
看到这里是不是有些小伙伴觉得只是模糊处理而已,觉得不过瘾,能不能来点更酷的。嘿嘿,有求必应!阿宝哥立马来个 “酷炫叼” 的库 —— midori,该库用于为背景图创建动画,使用 three.js 编写并使用 WebGL。本来是想给个演示动图,无奈单个 Gif 太大,只能放个体验地址,感兴趣的小伙伴自行体验一下。
midori 示例地址: https://aeroheim.github.io/mi...
2.3 cropperjs
JavaScript image cropper.
Cropper.js 是一款非常强大却又简单的图片裁剪工具,它可以进行非常灵活的配置,支持手机端使用,支持包括 IE9 以上的现代浏览器。它可以用于满足诸如裁剪头像上传、商品图片编辑之类的需求。
Cropper.js 支持以下特性:
- 支持 39 个配置选项;
- 支持 27 个方法;
- 支持 6 种事件;
- 支持 touch(移动端);
- 支持缩放、旋转和翻转;
- 支持在画布上裁剪;
- 支持在浏览器端通过画布裁剪图像;
- 支持处理 Exif 方向信息;
- 跨浏览器支持。
可交换图像文件格式(英语:Exchangeable image file format,官方简称 Exif),是专门为数码相机的照片设定的文件格式,可以记录数码照片的属性信息和拍摄数据。Exif 可以附加于 JPEG、TIFF、RIFF 等文件之中,为其增加有关数码相机拍摄信息的内容和索引图或图像处理软件的版本信息。Exif 信息以 0xFFE1 作为开头标记,后两个字节表示 Exif 信息的长度。所以 Exif 信息最大为 64 kB,而内部采用 TIFF 格式。
使用示例
// import 'cropperjs/dist/cropper.css';
import Cropper from 'cropperjs';
const image = document.getElementById('image');
const cropper = new Cropper(image, {
aspectRatio: 16 / 9,
crop(event) {
console.log(event.detail.x);
console.log(event.detail.y);
console.log(event.detail.width);
console.log(event.detail.height);
console.log(event.detail.rotate);
console.log(event.detail.scaleX);
console.log(event.detail.scaleY);
},
});https://fengyuanchen.github.i...

2.4 compressorjs
JavaScript image compressor.
compressorjs 是 JavaScript 图像压缩器。使用浏览器原生的 canvas.toBlob API 进行压缩工作,这意味着它是有损压缩。通常的使用场景是,在浏览器端图片上传之前对其进行预压缩。
在浏览器端要实现图片压缩,除了使用 canvas.toBlob API 之外,还可以使用 Canvas 提供的另一个 API,即 toDataURL API,它接收 type 和 encoderOptions 两个可选参数。
其中 type 表示图片格式,默认为 image/png。而 encoderOptions 用于表示图片的质量,在指定图片格式为 image/jpeg 或 image/webp 的情况下,可以从 0 到 1 的区间内选择图片的质量。如果超出取值范围,将会使用默认值 0.92,其他参数会被忽略。
相比 canvas.toDataURL API 来说,canvas.toBlob API 是异步的,因此多了个 callback 参数,这个 callback 回调方法默认的第一个参数就是转换好的 blob 文件信息。canvas.toBlob 的签名如下:
canvas.toBlob(callback, mimeType, qualityArgument)使用示例
import axios from 'axios';
import Compressor from 'compressorjs';
//
document.getElementById('file').addEventListener('change', (e) => {
const file = e.target.files[0];
if (!file) {
return;
}
new Compressor(file, {
quality: 0.6,
success(result) {
const formData = new FormData();
// The third parameter is required for server
formData.append('file', result, result.name);
// Send the compressed image file to server with XMLHttpRequest.
axios.post('/path/to/upload', formData).then(() => {
console.log('Upload success');
});
},
error(err) {
console.log(err.message);
},
});
});https://fengyuanchen.github.i...

2.5 fabric.js
Javascript Canvas Library, SVG-to-Canvas (& canvas-to-SVG) Parser.
Fabric.js 是一个框架,可让你轻松使用 HTML5 Canvas 元素。它是一个位于 Canvas 元素之上的交互式对象模型,同时也是一个 SVG-to-canvas 的解析器。
使用 Fabric.js,你可以在画布上创建和填充对象。所谓的对象,可以是简单的几何形状,比如矩形,圆形,椭圆形,多边形,或更复杂的形状,包含数百或数千个简单路径。然后,你可以使用鼠标缩放,移动和旋转这些对象。并修改它们的属性 —— 颜色,透明度,z-index 等。此外你还可以一起操纵这些对象,即通过简单的鼠标选择将它们分组。
Fabric.js 支持所有主流的浏览器,具体的兼容情况如下:
- Firefox 2+
- Safari 3+
- Opera 9.64+
- Chrome(所有版本)
- IE10,IE11,Edge
使用示例
http://fabricjs.com/kitchensink

(图片来源:https://github.com/fabricjs/f...)
2.6 Resemble.js
Image analysis and comparison
Resemble.js 使用 HTML Canvas 和 JavaScript 来实现图片的分析和比较。兼容大于 8.0 的 Node.js 版本。
使用示例
// 比较两张图片
var diff = resemble(file)
.compareTo(file2)
.ignoreColors()
.onComplete(function(data) {
console.log(data);
/*
{
misMatchPercentage : 100, // %
isSameDimensions: true, // or false
dimensionDifference: { width: 0, height: -1 },
getImageDataUrl: function(){}
}
*/
});http://rsmbl.github.io/Resemb...

2.7 Pica
Resize image in browser with high quality and high speed
Pica 可用于在浏览器中调整图像大小,没有像素化并且相当快。它会自动选择最佳的可用技术:webworkers,webassembly,createImageBitmap,纯 JS。
借助 Pica,你可以实现以下功能:
- 减小大图像的上传大小,节省上传时间;
- 在图像处理上节省服务器资源;
- 在浏览器中生成缩略图。
使用示例
const pica = require('pica')();
// 调整画布/图片的大小
pica.resize(from, to, {
unsharpAmount: 80,
unsharpRadius: 0.6,
unsharpThreshold: 2
})
.then(result => console.log('resize done!'));
// 调整大小并转换为Blob
pica.resize(from, to)
.then(result => pica.toBlob(result, 'image/jpeg', 0.90))
.then(blob => console.log('resized to canvas & created blob!'));http://nodeca.github.io/pica/...

2.8 tui.image-editor
Full-featured photo image editor using canvas. It is really easy, and it comes with great filters.
tui.image-editor 是使用 HTML5 Canvas 的全功能图像编辑器。它易于使用,并提供强大的过滤器。同时它支持对图像进行裁剪、翻转、旋转、绘图、形状、文本、遮罩和图片过滤等操作。
tui.image-editor 的浏览器兼容情况如下:
- Chrome
- Edge
- Safari
- Firefox
- IE 10+
使用示例
// Image editor
var imageEditor = new tui.ImageEditor("#tui-image-editor-container", {
includeUI: {
loadImage: {
path: "img/sampleImage2.png",
name: "SampleImage",
},
theme: blackTheme, // or whiteTheme
initMenu: "filter",
menuBarPosition: "bottom",
},
cssMaxWidth: 700,
cssMaxHeight: 500,
usageStatistics: false,
});
window.onresize = function () {
imageEditor.ui.resizeEditor();
};https://ui.toast.com/tui-imag...

2.9 gif.js
JavaScript GIF encoding library
gif.js 是运行在浏览器端的 JavaScript GIF 编码器。它使用类型化数组和 Web Worker 在后台渲染每一帧,速度真的很快。该库可工作在支持:Web Workers,File API 和 Typed Arrays 的浏览器中。
gif.js 的浏览器兼容情况如下:
- Google Chrome
- Firefox 17
- Safari 6
- Internet Explorer 10
- Mobile Safari iOS 6
使用示例
var gif = new GIF({
workers: 2,
quality: 10
});
// add an image element
gif.addFrame(imageElement);
// or a canvas element
gif.addFrame(canvasElement, {delay: 200});
// or copy the pixels from a canvas context
gif.addFrame(ctx, {copy: true});
gif.on('finished', function(blob) {
window.open(URL.createObjectURL(blob));
});
gif.render();http://jnordberg.github.io/gi...

2.10 Sharp
High performance Node.js image processing, the fastest module to resize JPEG, PNG, WebP and TIFF images. Uses the libvips library.
Sharp 的典型应用场景是将常见格式的大图像转换为尺寸较小,对网络友好的 JPEG,PNG 和 WebP 格式的图像。由于其内部使用 libvips ,使得调整图像大小通常比使用 ImageMagick 和 GraphicsMagick 设置快 4-5 倍 。除了支持调整图像大小之外,Sharp 还支持旋转、提取、合成和伽马校正等功能。
Sharp 支持读取 JPEG,PNG,WebP,TIFF,GIF 和 SVG 图像。输出图像可以是 JPEG,PNG,WebP 和 TIFF 格式,也可以是未压缩的原始像素数据。
使用示例
// 改变图像尺寸
sharp(inputBuffer)
.resize(320, 240)
.toFile('output.webp', (err, info) => { ... });
// 旋转输入图像并改变图片尺寸
sharp('input.jpg')
.rotate()
.resize(200)
.toBuffer()
.then( data => { ... })
.catch( err => { ... }); https://segmentfault.com/a/11...
该示例是来自阿宝哥 18 年写的 “Sharp 牛刀小试之生成专属分享图片” 这篇文章,主要是利用 Sharp 提供的图片合成功能为每个用户生成专属的分享海报,感兴趣的小伙伴可以阅读一下原文哟。
const sharp = require("sharp");
const TextToSVG = require("text-to-svg");
const path = require("path");
// 加载字体文件
const textToSVG = TextToSVG.loadSync(path.join(__dirname, "./simhei.ttf"));
// 创建圆形SVG,用于实现头像裁剪
const roundedCorners = new Buffer(
''
);
// 设置SVG文本元素相关参数
const attributes = { fill: "white" };
const svgOptions = {
x: 0,
y: 0,
fontSize: 32,
anchor: "top",
attributes: attributes
};
/**
* 使用文本生成SVG
* @param {*} text
* @param {*} options
*/
function textToSVGFn(text, options = svgOptions) {
return textToSVG.getSVG(text, options);
}
/**
* 图层叠加生成分享图片
* @param {*} options
*
*/
async function genShareImage(options) {
const { backgroudPath, avatarPath, qrcodePath,
userName, words, likes, outFilePath
} = options;
// 背景图片
const backgroudBuffer = sharp(path.join(__dirname, backgroudPath)).toBuffer({
resolveWithObject: true
});
const backgroundImageInfo = await backgroudBuffer;
// 头像图片
const avatarBuffer = await genCircleAvatar(path.join(__dirname, avatarPath));
// 二维码图片
const qrCodeBuffer = await sharp(path.join(__dirname, qrcodePath))
.resize(180)
.toBuffer({
resolveWithObject: true
});
// 用户名
const userNameSVG = textToSVGFn(userName);
// 用户数据
const userDataSVG = textToSVGFn(`写了${words}个字 收获${likes}个赞`);
const userNameBuffer = await sharp(new Buffer(userNameSVG)).toBuffer({
resolveWithObject: true
});
const userDataBuffer = await sharp(new Buffer(userDataSVG)).toBuffer({
resolveWithObject: true
});
const buffers = [avatarBuffer, qrCodeBuffer, userNameBuffer, userDataBuffer];
// 图层叠加参数列表
const overlayOptions = [
{ top: 150, left: 230 },
{ top: 861, left: 227 },
{
top: 365,
left: (backgroundImageInfo.info.width - userNameBuffer.info.width) / 2
},
{
top: 435,
left: (backgroundImageInfo.info.width - userDataBuffer.info.width) / 2
}
];
// 组合多个图层:图片+文字图层
return buffers
.reduce((input, overlay, index) => {
return input.then(result => {
console.dir(overlay.info);
return sharp(result.data)
.overlayWith(overlay.data, overlayOptions[index])
.toBuffer({ resolveWithObject: true });
});
}, backgroudBuffer)
.then((data) => {
return sharp(data.data).toFile(outFilePath);
}).catch(error => {
throw new Error('Generate Share Image Failed.');
});
}
/**
* 生成圆形的头像
* @param {*} avatarPath 头像路径
*/
function genCircleAvatar(avatarPath) {
return sharp(avatarPath)
.resize(180, 180)
.overlayWith(roundedCorners, { cutout: true })
.png()
.toBuffer({
resolveWithObject: true
});
}
module.exports = {
genShareImage
};三、阿宝哥有话说
3.1 如何区分图片的类型
计算机并不是通过图片的后缀名来区分不同的图片类型,而是通过 “魔数”(Magic Number)来区分。 对于某一些类型的文件,起始的几个字节内容都是固定的,跟据这几个字节的内容就可以判断文件的类型。
常见图片类型对应的魔数如下表所示:
| 文件类型 | 文件后缀 | 魔数 |
|---|---|---|
| JPEG | jpg/jpeg | 0xFFD8FF |
| PNG | png | 0x89504E47 |
| GIF | gif | 0x47494638(GIF8) |
| BMP | bmp | 0x424D |
这里我们以阿宝哥的头像(abao.png)为例,验证一下该图片的类型是否正确:

在日常开发过程中,如果遇到检测图片类型的场景,我们可以直接利用一些现成的第三方库。比如,你想要判断一张图片是否为 PNG 类型,这时你可以使用 is-png 这个库,它同时支持浏览器和 Node.js,使用示例如下:
Node.js
// npm install read-chunk
const readChunk = require('read-chunk');
const isPng = require('is-png');
const buffer = readChunk.sync('unicorn.png', 0, 8);
isPng(buffer);
//=> trueBrowser
(async () => {
const response = await fetch('unicorn.png');
const buffer = await response.arrayBuffer();
isPng(new Uint8Array(buffer));
//=> true
})();3.2 如何获取图片的尺寸
图片的尺寸、位深度、色彩类型和压缩算法都会存储在文件的二进制数据中,我们继续以阿宝哥的头像(abao.png)为例,来了解一下实际的情况:
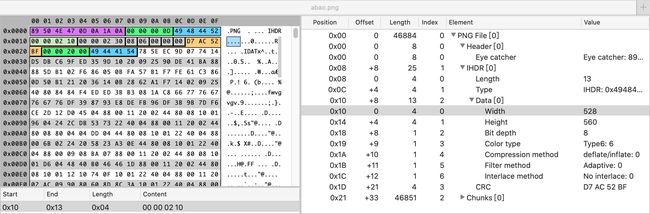
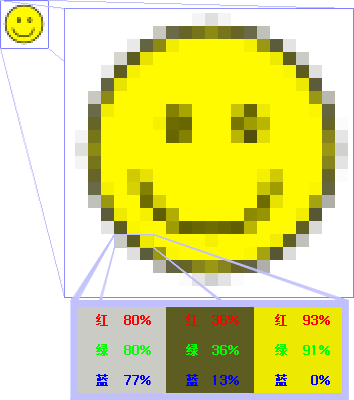
528(十进制) => 0x0210560(十进制)=> 0x0230
因此如果想要获取图片的尺寸,我们就需要依据不同的图片格式对图片二进制数据进行解析。幸运的是,我们不需要自己做这件事,image-size 这个 Node.js 库已经帮我们实现了获取主流图片类型文件尺寸的功能:
同步方式
var sizeOf = require('image-size');
var dimensions = sizeOf('images/abao.png');
console.log(dimensions.width, dimensions.height);异步方式
var sizeOf = require('image-size');
sizeOf('images/abao.png', function (err, dimensions) {
console.log(dimensions.width, dimensions.height);
});image-size 这个库功能还是蛮强大的,除了支持 PNG 格式之外,还支持 BMP、GIF、ICO、JPEG、SVG 和 WebP 等格式。
3.3 如何预览本地图片
利用 HTML FileReader API,我们也可以方便的实现图片本地预览功能,具体代码如下:
![]()
在完成本地图片预览之后,可以直接把图片对应的 Data URLs 数据提交到服务器。针对这种情形,服务端需要做一些相关处理,才能正常保存上传的图片,这里以 Express 为例,具体处理代码如下:
const app = require('express')();
app.post('/upload', function(req, res){
let imgData = req.body.imgData; // 获取POST请求中的base64图片数据
let base64Data = imgData.replace(/^data:image\/\w+;base64,/, "");
let dataBuffer = Buffer.from(base64Data, 'base64');
fs.writeFile("image.png", dataBuffer, function(err) {
if(err){
res.send(err);
}else{
res.send("图片上传成功!");
}
});
});3.4 如何实现图片压缩
在一些场合中,我们希望在上传本地图片时,先对图片进行一定的压缩,然后再提交到服务器,从而减少传输的数据量。在前端要实现图片压缩,我们可以利用 Canvas 对象提供的 toDataURL() 方法,该方法接收 type 和 encoderOptions 两个可选参数。
其中 type 表示图片格式,默认为 image/png。而 encoderOptions 用于表示图片的质量,在指定图片格式为 image/jpeg 或 image/webp 的情况下,可以从 0 到 1 的区间内选择图片的质量。如果超出取值范围,将会使用默认值 0.92,其他参数会被忽略。
下面我们来看一下具体如何实现图片压缩:
function compress(base64, quality, mimeType) {
let canvas = document.createElement("canvas");
let img = document.createElement("img");
img.crossOrigin = "anonymous";
return new Promise((resolve, reject) => {
img.src = base64;
img.onload = () => {
let targetWidth, targetHeight;
if (img.width > MAX_WIDTH) {
targetWidth = MAX_WIDTH;
targetHeight = (img.height * MAX_WIDTH) / img.width;
} else {
targetWidth = img.width;
targetHeight = img.height;
}
canvas.width = targetWidth;
canvas.height = targetHeight;
let ctx = canvas.getContext("2d");
ctx.clearRect(0, 0, targetWidth, targetHeight); // 清除画布
ctx.drawImage(img, 0, 0, canvas.width, canvas.height);
let imageData = canvas.toDataURL(mimeType, quality / 100);
resolve(imageData);
};
});
}对于返回的 Data URL 格式的图片数据,为了进一步减少传输的数据量,我们可以把它转换为 Blob 对象:
function dataUrlToBlob(base64, mimeType) {
let bytes = window.atob(base64.split(",")[1]);
let ab = new ArrayBuffer(bytes.length);
let ia = new Uint8Array(ab);
for (let i = 0; i < bytes.length; i++) {
ia[i] = bytes.charCodeAt(i);
}
return new Blob([ab], { type: mimeType });
}在转换完成后,我们就可以压缩后的图片对应的 Blob 对象封装在 FormData 对象中,然后再通过 AJAX 提交到服务器上:
function uploadFile(url, blob) {
let formData = new FormData();
let request = new XMLHttpRequest();
formData.append("image", blob);
request.open("POST", url, true);
request.send(formData);
}3.5 如何操作位图像素数据
如果想要操作图片像素数据,我们可以利用 CanvasRenderingContext2D 提供的 getImageData 来获取图片像素数据,其中 getImageData() 返回一个 ImageData 对象,用来描述 canvas 区域隐含的像素数据,这个区域通过矩形表示,起始点为(sx, sy)、宽为 sw、高为 sh。其中 getImageData 方法的语法如下:
ctx.getImageData(sx, sy, sw, sh);相应的参数说明如下:
- sx:将要被提取的图像数据矩形区域的左上角 x 坐标。
- sy:将要被提取的图像数据矩形区域的左上角 y 坐标。
- sw:将要被提取的图像数据矩形区域的宽度。
- sh:将要被提取的图像数据矩形区域的高度。
在获取到图片的像素数据之后,我们就可以对获取的像素数据进行处理,比如进行灰度化或反色处理。当完成处理后,若要在页面上显示处理效果,则我们需要利用 CanvasRenderingContext2D 提供的另一个 API —— putImageData。
该 API 是 Canvas 2D API 将数据从已有的 ImageData 对象绘制到位图的方法。 如果提供了一个绘制过的矩形,则只绘制该矩形的像素。此方法不受画布转换矩阵的影响。putImageData 方法的语法如下:
void ctx.putImageData(imagedata, dx, dy);
void ctx.putImageData(imagedata, dx, dy, dirtyX, dirtyY, dirtyWidth, dirtyHeight);相应的参数说明如下:
- imageData:
ImageData,包含像素值的数组对象。 - dx:源图像数据在目标画布中的位置偏移量(x 轴方向的偏移量)。
- dy:源图像数据在目标画布中的位置偏移量(y 轴方向的偏移量)。
- dirtyX(可选):在源图像数据中,矩形区域左上角的位置。默认是整个图像数据的左上角(x 坐标)。
- dirtyY(可选):在源图像数据中,矩形区域左上角的位置。默认是整个图像数据的左上角(y 坐标)。
- dirtyWidth(可选):在源图像数据中,矩形区域的宽度。默认是图像数据的宽度。
- dirtyHeight(可选):在源图像数据中,矩形区域的高度。默认是图像数据的高度。
介绍完相关的 API,下面我们来举一个实际例子:
图片反色和灰度化处理
需要注意的在调用 getImageData 方法获取图片像素数据时,你可能会遇到跨域问题,比如:
Uncaught DOMException: Failed to execute 'getImageData' on 'CanvasRenderingContext2D': The canvas has been tainted by cross-origin data.对于这个问题,你可以阅读 张鑫旭 大神 “解决canvas图片getImageData,toDataURL跨域问题” 这一篇文章。
3.6 如何实现图片隐写
隐写术是一门关于信息隐藏的技巧与科学,所谓信息隐藏指的是不让除预期的接收者之外的任何人知晓信息的传递事件或者信息的内容。 隐写术的英文叫做 Steganography,来源于特里特米乌斯的一本讲述密码学与隐写术的著作 Steganographia,该书书名源于希腊语,意为 “隐秘书写”。
下图是阿宝哥采用在线的图片隐写工具,将 “全栈修仙之路” 这 6 个字隐藏到原始的图片中,然后使用对应的解密工具,解密出隐藏信息的结果:

(在线图片隐写体验地址:https://c.p2hp.com/yinxietu/)
目前有多种方案可以实现图片隐写,以下是几种常见的方案:
- 附加式的图片隐写;
- 基于文件结构的图片隐写;
- 基于 LSB 原理的图片隐写;
- 基于 DCT 域的 JPG 图片隐写;
- 数字水印的隐写;
- 图片容差的隐写。
篇幅有限,这里我们就不继续展开,分别介绍每种方案,感兴趣的小伙伴可以阅读 “隐写术之图片隐写(一)” 这篇文章。
四、参考资源
- Baike - 矢量图
- Wiki - 可缩放矢量图形
- 隐写术之图片隐写(一)
- 不能说的秘密——前端也能玩的图片隐写术
- 又拍图片管家亿级图像之搜图系统的两代演进及底层原理
- image-manipulation-libraries-for-javascript