HBase-Region详解
HBase-Region详解
Region的概念
Region是HBase数据管理的基本单位。数据的move,数据的balance,数据的split,都是按照region来进行操作的。
region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。
一个表中可以包含一个或多个Region。
每个Region只能被一个RS(RegionServer)提供服务,RS可以同时服务多个Region,来自不同RS上的Region组合成表格的整体逻辑视图。
regionServer 其实是hbase的服务,部署在一台物理服务器上,region有一点像
关系型数据的分区,数据存放在region中,当然region下面还有很多结构,确切来
说数据存放在memstore和hfile中。我们访问hbase的时候,先去hbase 系统表查找
定位这条记录属于哪个region,然后定位到这个region属于哪个服务器,然后就到
哪个服务器里面查找对应region中的数据
每个region 有三个主要要素:
它所属于哪张表
它所包含的的第一行(第一个region 没有首行)
它所包含的最后一行(末一个region 没有末行)
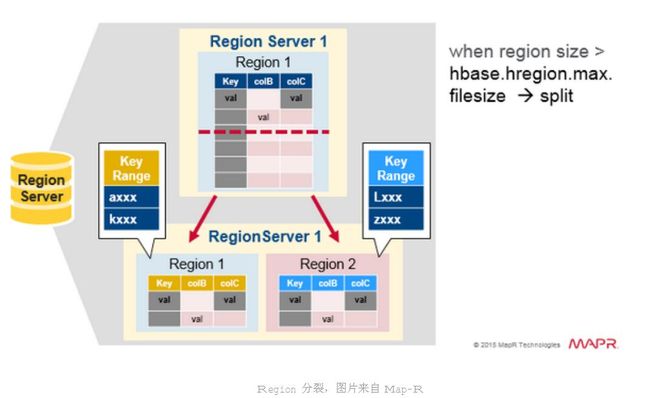
当表初写数据时,此时表只有一个region ,当随着数据的增多,region 开始变大,等到它达到限定的阀值大小时,变化把region 分裂为两个大小基本相同的region,
而这个阀值就是storefile 的设定大小(参数:hbase.hregion.max.filesize 新版本默认10G) ,在第一次分裂region之前,所有加载的数据都放在原始区域的那台服务器上,随着表的变大
region 的个数也会相应的增加,而region 是Hbase集群分布数据的最小单位。
(但region 也是由block组成,具体这个block和hdfs block什么样的关系后面再说,region是属于单一的regionserver,除非这个regionserver 宕机,或者其它方式挂掉,再或者执行balance时,才可能会将这部分region的信息转移到其它机器上。)
* 这也就是 为什么region比较少的时候,导致region分配不均,总是分派到少数的节点上,读写并发效果不显著,这就是hbase 读写效率比较低的原因。
Region的结构

1 层级结构

· Table (HBase 表)
· Region(表的Regions)
o Store(Region中以列族为单位的单元)
§ MemStore (用于写缓存)
§ StoreFile (StoreFiles for each Store for each Region for the table)
§ Block (读写的最小单元)
2 重要成员
2.1 Region
Region是HBase数据存储和管理的基本单位
2.1.1 Region的数量设计
设计的本意是每个Server运行小数量(2-200)个大容量(5-20Gb)的Region,理由如下:
· 每个MemStore需要2MB的堆内存,2MB是配置的,假如有1000拥有两个列族的Region,那么就需要3.9GB的堆内存,还是没有存储任何数据的情况下
· HMaster要花大量的时间来分配和移动Region
· 过多Region会增加ZooKeeper的负担
· 每个Region会对应一个MapReduce任务,过多Region会产生太多任务
2.1.2 Region的分配
2.1.2.1 启动时的分配步骤
Master启动时调用 AssignmentManager。
AssignmentManager 查看hbase:meta中已经分配好的Region
如果Regiond的分配依然有效的话 (如果RegionServer 仍然在线的话) 维持当前分配
如果分配失效,LoadBalancerFactory 会被调用来分配region. 负载均衡器(HBase 1.0默认使用StochasticLoadBalancer ) 分配任务到Region Server中
如果需要的话,Region Server分配信息会更新到hbase:meta中。RegionServer启动时调用启动代码来启动region。
2.1.2.2 RegionServer失效时的分配步骤
1. Region Server挂掉后它上面的regions变得不可用。
2. Master检测到Region Server挂掉了。
3. 失效Region Server上的region分配会被认为无效并采用跟启动时同样顺序的步骤分配region
4. 正在进行的查询操作会重新执行,不会丢失
5. 切换动作要在以下时间内完成:
ZooKeeper session timeout + split time + assignment/replay time
2.1.3 Region的位置选择
Region的位置选择通过HDFS的复制机制完成
1)步骤:
1. 第一个副本写在本地节点
2. 第二副本写到另一个机上任意节点
3. 第三个副本写到跟第二副本相同机架不同节点的其他节点
4. 后面的副本将写到集群中的任意节点中。
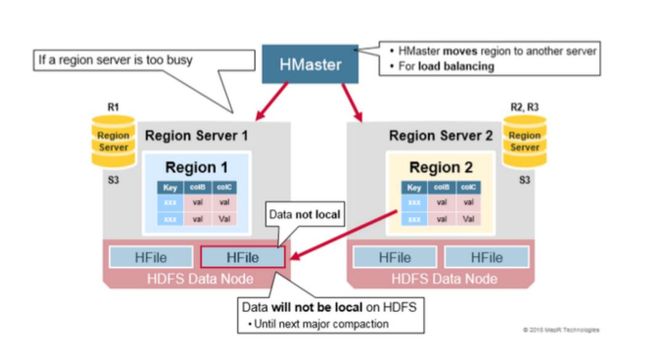
2)要点:
· 选址是在flush或者compaction之后执行的
· 当RegionServer失效后,其上的Region被转移到其他的RegionServer,那么此时被转移的Region不具备数据本地性,直到下一次compaction执行之后才重新具备数据本地性
2.1.4 Region的切分
· 当Region的大小达到指定的阀值时,RegionServer会执行Region的切分
· 该操作有RegionServer单独执行,Master不参与
· 分裂执行完毕后,会将子Region添加到hbase:meta并且汇报给Master
· 可以自定义切分策略,可以在hbase-site.xml设置
<property>
<name>hbase.regionserver.region.split.policyname>
<value>org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicyvalue>property>
· 支持手动执行切分
· 可以指定切分点
2.1.5 Region的合并
2.1.5.1 意义
· 当存在大量没有数据的region时,执行region的合并来避免region过多
· 之所以会存在大量没有数据的region是因为为了避免region到达阀值引起分裂的开销,创建表格时先进行预分区。
2.1.5.2 步骤
1. 客户端发送指令给Master
2. Master收到指令后将要合并的region移动到指定的RegionServer
3. Master发送Merge请求给指定的RegionServer执行合并操作
4. 最后将被合并的regions从hbase:meta中删除并添加合并后的region
2.2 Store
· 以列族为单元,即对应表中每个region中一个列族
· 包含一个MemStore和0到多个StoreFile(HFile)
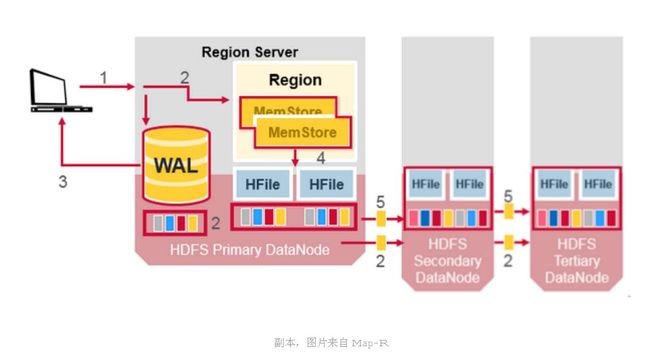
2.2.1 MemStore
· 将修改信息缓存在内存当中
· 信息格式为Cell/KeyValue
· 当flush触发时,MemStore会生成快照保存起来,新的MemStore会继续接收修改信息,指导flush完成之后快照会被删除
· 当一个MemStore flush发生时,属于同一个region的memStore会一起flush
2.2.2.1 MemStore Flush的触发情况
· MemStore的大小达到单个MemStore阀值
· RegionServer中所有MemStore的使用率超过RS中MemStore上限值,该Server上所有MemStore会执行flush直到完成或者小于RS中MemStore安全值
· RegionServer中WAL超过WAL阀值
单个MemStore阀值:hbase.hregion.memstore.flush.size
RS中MemStore上限值:hbase.regionserver.global.memstore.upperLimit
RS中MemStore安全值:hbase.regionserver.global.memstore.lowerLimit
WAL阀值:hbase.regionserver.max.logs
2.3 StoreFile/HFile
2.3.1 格式
2.3.1.1 概念:
· Data Block Size:数据块大小。默认为64KB。因为查询key是按照顺序查询的,所以需要选择合适的Size来避免一个Block包含过多Key/Value对。
· Maximum Key Length:最大key长度。10-100字节是比较合适的大小,key的形式:rowkey+column family:qualifier+timestamp
· Maximum File Size:最大File大小。Trailer、File-Info和Data-Index都会在读取和写入时存到内存中,所以最好保证File的大小在合理的范围,避免占用过多内存。
· Compression Algorithm:压缩算法。
· 好处:
o 减少磁盘I/O
o 提高传输效率和减少磁盘空间
o 减少读取请求的返回量
· 支持的压缩库
o GZ
o LZO
2.3.1.2 HFile 结构
结构图如下:
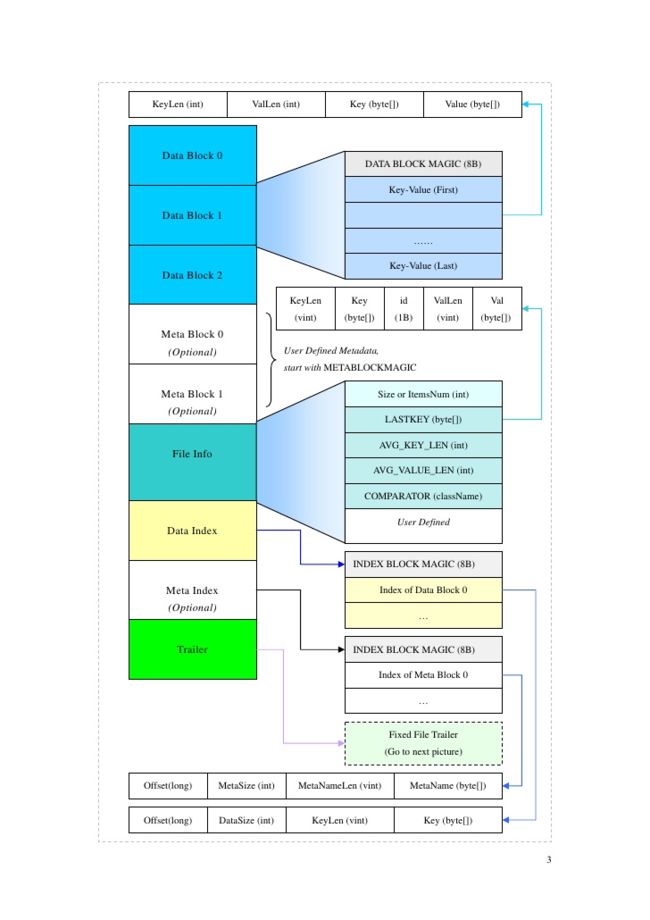
HFile结构图

Trailer结构
· Data Block:存储键值对的长度和值
· Meta Block:用户定义元数据
· File Info:关于HFile的元数据
· Data Index:Data Block的索引,也就是每个Block的第一个Key的偏移量
· Trailer:固定的源数据,用于存储以上每个部分的偏移量,读取HFile时首先要读取Trailer。
2.3.2 KeyValue

KeyValue以字节数组的形式存储,包含以下部分:
· keylength
· valuelength
· key
· value
Key的格式如下:
· rowlength
· row (也就是the rowkey)
· columnfamilylength
· columnfamily
· columnqualifier
· timestamp
· keytype (例如 Put, Delete, DeleteColumn, DeleteFamily)
2.4 Scan 步骤
1. 当客户端提交scan请求时,HBase会创建为每个Region创建RegionScanner 实例来处理scan请求
· RegionScanner 包含一组StoreScanner实例,每个列族对应一个StoreScanner实例
· 每个StoreScanner实例包含一组StoreFileScanner实例, 每个toreFileScanner实例对应每个列族的HFile, 同时包含一组对应MemStore的KeyValueScanner。
· The two lists are merged into one, which is sorted in ascending order with the scan object for the MemStore at the end of the list.
· 当StoreFileScanner实例被构造, 会生成MultiVersionConcurrencyControl 读取点, 就是当前的memstoreTS, 用来过滤掉
2.5 Compaction
2.5.1 Minor Compaction(次压缩)
HBase会自动挑选小的临近的HFiles将它们重新写到一些大的HFiles中。这个过程称为次压缩。次压缩通过将更小的files写到一些大的flies进行合并操作来实现减少file的数量。

2.5.2 Major Compaction(主压缩)
· 合并一个Region中每一个列族的所有HFile写到一个HFile中
· 会删除掉那些标记删除和过期的cells。提高了读取性能
· 将所有数据进行了重写,产生大量的I/O开销或者网络开销,称为写放大
· 自动执行,通常安排在周末或者晚上

2.6 Region 负载均衡
当region分裂之后,RS之间的region数量差距变大时,HMaster便会执行负载均衡来调整部分region的位置,使得每个RS的region数量保持在合理范围之内,负载均衡会引起region的重新定位,使得涉及的region不具备数据本地性,即HFile和region不在同一个DataNode。这种情况会在major compaction 之后得到解决。