hbase相关知识汇总
hbase相关知识汇总
- 介绍
- 架构
- 特性
- 自动分区
- LSM-Tree
- 自动合并
- 高可靠
- 读写过程
- 写请求
- 读请求
- 2.0特性
- Region Replica
- 读写链路 Off-heap
- In Memory Compaction
- 小对象存储 MOB
- Assignment MangerV2
介绍
HBase(Hadoop Database),是一个基于 Google BigTable 论文设计的高可靠性、高性能、可伸缩的分布式存储系统。
1、海量存储:单表可以存储百亿级别的量级,不用担心读取的性能下降。
2、面向列:数据在表中是按某列的数据聚集存储,数据即索引,只访问查询涉及的列时,可以大量降低系统的I/O。
3、稀疏性:传统行数存储的数据存在大量NULL的列,需要占用存储空间,造成存储空间的浪费,而HBase为空的列并不占用空间,因此表可以设计的很稀疏。
4、扩展性:HBase底层基于HDFS,支持扩展,并且可以随时添加或者减少节点。
5、高可靠:基于zookeeper的协调服务,能够保证服务的高可用行。HBase使用WAL和replication机制,前者保证数据写入时不会因为集群异常而导致写入数据的丢失,后者保证集群出现严重问题时,数据不会发生丢失和损坏。
6、高性能:底层的LSM数据结构,使得HBase具备非常高的写入性能。RowKey有序排列、主键索引和缓存机制使得HBase具备一定的随机读写性能。
架构
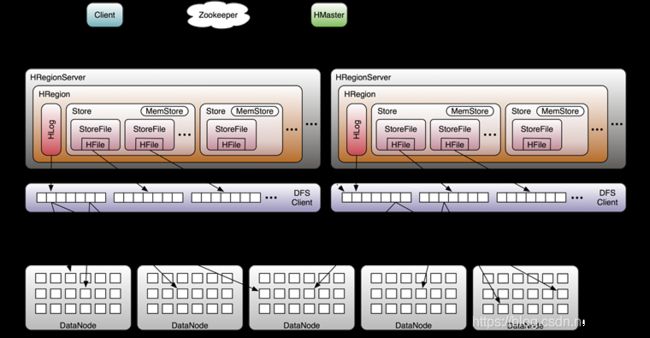
HMaster节点
HBase Master 用于协调多个 Region Server,侦测各个 Region Server 之间的状态,并平衡 Region Server 之间的负载。HBase Master 还有一个职责就是负责分配 Region 给 Region Server。HBase 允许多个 Master 节点共存,但是这需要 Zookeeper 的帮助。不过当多个 Master 节点共存时,只有一个 Master 是提供服务的,其他的 Master 节点处于待命的状态。当正在工作的 Master 节点宕机时,其他的 Master 则会接管 HBase 的集群。
HRegionServer节点
对于一个 Region Server 而言,其包括了多个 Region。Region Server 的作用只是管理表格,以及实现读写操作。Client 直接连接 Region Server,并通信获取 HBase 中的数据。对于 Region 而言,则是真实存放 HBase 数据的地方,也就说 Region 是 HBase 可用性和分布式的基本单位。如果当一个表格很大,并由多个 CF 组成时,那么表的数据将存放在多个 Region 之间,并且在每个 Region 中会关联多个存储的单元(Store)。
ZooKeeper节点
对于 HBase 而言,Zookeeper 的作用是至关重要的。首先 Zookeeper 是作为 HBase Master 的 HA 解决方案。也就是说,是 Zookeeper 保证了至少有一个 HBase Master 处于运行状态。并且 Zookeeper 负责 Region 和 Region Server 的注册以及存放整个HBase集群的元数据以及集群的状态信息。
特性
自动分区
在 HBase 中,使用的是自动分区功能。当访问量和请求量增加的时候它可以自动的进行数据分片,以应对数据和请求的爆发式增长。
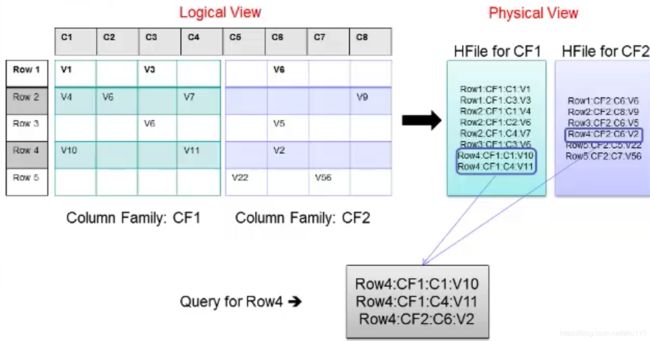
每一个 Region 都只存储一个 Column Family 的数据,并且是该 CF 中的一段(按 Row 的区间分成多个 Region)。Region 所能存储的数据大小是有上限的,当达到该上限时(Threshold),Region 会进行分裂,数据也会分裂到多个 Region 中,这样便可以提高数据的并行化,以及提高数据的容量。
LSM-Tree
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中即是小树,随着小树越来越大,会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。本质上就是通过把随机写的数据写到内存,然后定期flush到磁盘,对于磁盘来说,让所有的操作顺序化,而不是随机读写。
数据会先写到内存中,为了防止内存数据丢失,写内存的同时需要持久化到磁盘,对应HBase的MemStore和HLog;
MemStore中的数据达到一定的阈值之后,需要将数据刷写到磁盘,即生成HFile(也是一颗小的B+树)文件;
hbase中的minor(少量HFile小文件合并)major(一个region的所有HFile文件合并)执行compact操作,同时删除无效数据(过期及删除的数据),多棵小树在这个时机合并成大树,来增强读性能。
Bloom-filter:就是个带随机概率的bitmap,可以快速的告诉你,某一个小的有序结构里有没有指定数据的。于是就可以不用二分查找,而只需简单的计算几次就能知道数据是否在某个小集合里啦。效率得到了提升,但付出的是空间代价。
compact:小树合并为大树:因为小树性能有问题,所以要有个进程不断地将小树合并到大树上,这样大部分的老数据查询也可以直接使用log2N的方式找到,不需要再进行(N/m)*log2n的查询了。
自动合并
当我们不停地往HBase中写入数据,也就是往MemStore写入数据,HBase会检查MemStore是否达到了需要刷写到磁盘的阈值。如果达到刷写的条件,MemStore中的记录就会被刷写到磁盘,形成一个新的StoreFile。可想而知,随着MemStore的不断刷写,会形成越来越多的磁盘文件。HBase会通过合并已有的HFile来减少每次读数据的磁盘寻道时间,从而提高读速度,这个文件合并过程就称为Compaction。compaction其实就是用当前更高的磁盘IO来换取将来更低的磁盘寻道时间。
HBase的compaction分为minor和major两种。minor合并负责将几个小文件合并成一个较大的文件;major合并是将一个HStore中的所有文件合并成一个文件。每次触发compact检查。系统会自动决定执行哪一种compaction(合并)。有三种情况会触发compact检查:
MemStore被刷写到磁盘;
用户执行shell命令compact、major_compact或者调用了相应的API;
HBase后台线程周期性触发检查。
major合并中会删除那些被标记为删除的数据、超过TTL(time-to-live)时限的数据,以及超过了版本数量限制的数据,将HStore中所有的HFile重写成一个HFile。
高可靠
HBase 中的 HLog 机制是 WAL 的一种实现,而 WAL(一般翻译为预写日志)是事务机制中常见的一致性的实现方式。每个 Region Server 中都会有一个 HLog 的实例,Region Server 会将更新操作(如 Put,Delete)先记录到 WAL(也就是 HLog)中,然后将其写入到 Store 的 MemStore,最终 MemStore 会将数据写入到持久化的 HFile 中(MemStore 到达配置的内存阀值)。这样就保证了 HBase 的写的可靠性。
读写过程
有一个特殊的HBase目录表被称为META表,此表保存了所有region在集群中的位置。Zookeeper储存META表的位置。
在第一次读写的时候,
1:客户端从ZooKeeper获取承载META表的Region server
2:客户端将会查询.META.服务获取与其想要访问的row key相对应的region server。客户端将这条信息与META表位置一起缓存
3:客户端将会从对应的Region Server获取Row
对于未来的读操作,客户端使用缓存来取回META的位置和先前读取的行键。随着时间的推移,不需要读取META表,除非一个region被移动导致的查询失败。如果是这样的话它将会重新查询并更新缓存。
注 1:数据路由并不涉及Master,也就是说 DML 操作不需要 Master 参与。借助 hbase:meta,客户端直接与 Region Server 通信,完成数据路由、读写。
注 2:客户端获取 hbase:meta 地址后,会缓存该地址信息,以此减少对 ZooKeeper 的访问。同时,客户端根据 RowKey 查找 hbase:meta,获取对应的 Region Server 地址后,也会缓存该地址,以此减少对 hbase:meta 的访问。因为 hbase:meta 是存放在 Region Server 的一张表,其大小可能很大,因此不会缓存 hbase:meta 的完整内容。
写请求
当一个客户端发出Put请求时,第一步是将数据写入预写入日志WAL:
1.编辑好的文件将会被追加到位于磁盘上的WAL文件末尾
2.WAL用于在服务器奔溃是恢复尚未保存的数据
3.当数据写入至WAL后,就会被放入MemStore。然后,put请求确认就会返回给客户端。
读请求
一个HFile中包含的多层索引允许HBase在不用读取所有文件的情况下查找数据。
尾部块指向元数据块,并且被写入到文件中的持久化数据的末尾。尾部块同时也拥有着比如bloom过滤器和时间范围等信息。Bloom过滤器有助于跳过不包含某个确定行键的文件。如果文件不在读取的时间范围内,则时间范围对跳过文件非常有用。
当HFile被编辑时加载并保存在内存中。这允许使用单个磁盘查找进行搜索。
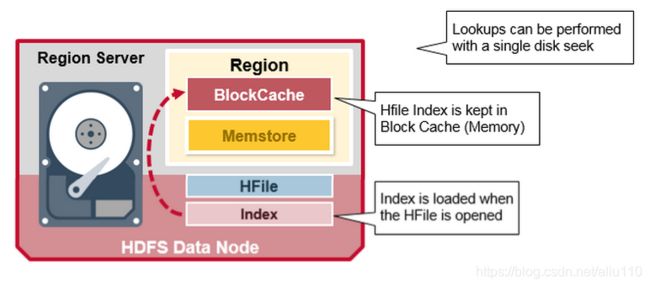
对应一行的KeyValue单元格可以在多个位置,单元格在已经持久化的HFiles中,最近更新的单元格在MemStore中,最近读的单元格在块内存中。所以当你读取一行时,系统如何知道获取对应的单元格并返回?在如下步骤中,read合并块内存,MemStore和HFiles中的键值
- 首先,扫描器查找在块缓存中(BlockCache)的行单元格 - 读缓存。最近读取的键值被缓存在这,当需要内存时,最近不经常使用的键值就会被回收。
- 接下来,扫描器就会在MemStore中查找最近写入内存的写缓存。
- 如果扫描器在MemStore和块缓存中没有找到所有的行单元格,那么HBase将会使用块缓存索引和bloom过滤器把HFiles加载到内存中,该文件可能含有目标单元格。
2.0特性
Region Replica
在 CAP 理论中,HBase 一直是一个 CP 系统,HBase依赖HDFS实现了数据的多副本,但是在计算层,HBase的region只能在一台RegionServer上线提供读写服务,来保持强一致。如果这台服务器发生宕机时,Region需要从WAL中恢复还缓存在memstore中未刷写成文件的数据,才能重新上线服务。所以 Server 宕机后需要一定的恢复时间。
Region replica的本质,就是让同一个region host在多个regionserver上。原来的region,称为Default Replica(主region),提供了与之前类似的强一致读写体验。而与此同时,根据配置的多少,会有一个或者多个region的副本,统称为 region replica,在另外的RegionServer上被打开。并且由Master中的LoadBalancer来保证region和他们的副本,不会在同一个RegionServer打开,防止一台服务器的宕机导致多个副本同时挂掉。
Region Replica的设计巧妙之处在于,额外的region副本并不意味着数据又会多出几个副本。这些region replica在RegionServer上open时,使用的是和主region相同的HDFS目录。也就是说主region里有多少HFile,那么在region replica中,这些数据都是可见的,都是可以读出来的。
region replica相对于主region,有一些明显的不同。
首先,region replica是不可写的。这其实很容易理解,如果region replica也可以写的话,那么同一个region会在多个regionserver上被写入,连主region上的强一致读写都没法保证了。
再次,region replica是不能被split和merge的。region replica是主region的附属品,任何发向region replica的split和merge请求都会被拒绝掉。只有当主region split/merge时,才会把这些region replica从meta表中删掉,建立新生成region的region的replica。
客户端可以做到,对多个副本同时发请求,然后做到选择最快速的那个副本,提供高可用读,宕机 0 影响,规避抖动,毛刺,降低 P999 延迟;缺点是需要额外耗费 CPU/Memory 资源,但不会占用额外空间。
读写链路 Off-heap
全链路 Off-heap,意思就是读写链路数据端到端 Off-heap,减少 java GC 带来的停顿,进一步降低 P999 延迟,提高吞吐。这个功能我们从两方面来实现的:写链路 Off-heap,我们使用在 RPC 层使用 Netty 的 Off-heap ByteBuffer,使用支持 Off-heap 的 Protobuf。同时使用 Off-heap 的 Chunk 来存储 Memstore 中的 KeyValue。
在读链路 Off-heap 方面,使用 Off-heap 的 Bucket Cache,HBase 自己管理内存的,我们从 Bucket Cache 读取数据的时候,先要从 Protobuf 做一次拷贝,因为可能读取的时候,发生内存不够了,再次分配的情况。在读取对 Bucket Cache 进行引用计数,保证读取的时候,内存不会被回收掉,读取时不再需要先拷贝到 heap,对 Bucket Cache 进行了一系列性能优化。
In Memory Compaction
把MemStrore使用的ConcurrentSkipListMap在内存中flush成更加紧凑的 CellArrayMap 这个结构,同时多个 CellArrayMap 会在内存中做 compaction,使内存的使用更加紧凑。然后通过 In memory 的 flush 和 compaction, 在内存中可以存储更多的数据,因此可以提高读性能,同时减少磁盘 IO,减轻 compaction 小文件造成的写放大。
小对象存储 MOB
之前我们建议在 HBase 上不要存很大的 KV 值,但是 MOB(Moderate Object Storage) 功能使 HBase 能高效地存储那些 100k~10M 中等大小的对象。这使得用户可以把文档、图片对象保存到 HBase 系统中。
用户写入的小对象 flush 成一个独立文件,原有的 KV 中的 value 只存这个对象的引用路径,对于存储对象文件, 更少地进行 compaction 来减少写入放大效应。
Assignment MangerV2
HBase 中的状态流转,建表删表,都需要在 Assignment MangerV2 上进行,之前旧 AM 系统参与角色多, 状态更新混乱,效率低,无事务保证,容易出现 RIT 问题。所以 AM V2 使用 ProcedureV2 来保证 Table/Region 状态转换在 master 重启后仍然能恢复执行,然后去除了 Zookeeper 做为中间角色,Master/RegionServer 直接交互,Region assign/unassgin 速度大大提升。