Hbase
文章目录
- Hbase
- 来源:
- 应用:
- 行业:
- Hbase定义:
- Hbase特性:
- Hbase shell
- namespace
- DDL
- DML
- Hbase Java Api
- 依赖
- HbaseUtils
- HbaseDemo
- Hbase过滤器
- Hbase原理
- 架构
- Hbase读写流程
- 写数据流程
- Hbase的存储机制
- 存储模型
- 布隆过滤器
- 2.6.10 Hbase的寻址机制
- 读数据流程
- StoreFile合并
- Region分割
- Hbase2Hdfs
- Hdfs2Hbase
Hbase
来源:
- 解决随机近实时的高效的读写
- 解决非结构化的数据存储
应用:
-
可以存储非结构化的数据(用户、商品、文章的画像属性)
-
被用来做实时(整合flume、storm、streaming等)
-
存储历史明细数据(较少)
-
存储结果数据(数仓,Kylin预执行数据就是放到Hbase中)
行业:
- 通信、银行、金融等
Hbase定义:
- Hadoop的数据库
- Hadoop的分布式、开源的、多版本的非关系型数据库
- Hbase存储Key-Value格式,面向列存储,Hbase底层为字节数据,没有数据类型一说
Hbase特性:
- 线性和模块化可扩展性
- 严格一致的读写
- 表的自动和可配置分片
- RegionServer之间的自动故障转移支持
- 方便的基类,用于通过Apache HBase表备份Hadoop MapReduce作业
- 易于使用的Java API用于客户端访问
- 块缓存和布隆过滤器用于实时查询
- 通过服务器端过滤器查询谓词下推
- Thrift网关和支持XML,Protobuf和二进制数据编码选项的REST-ful Web服务
- 可扩展的基于Jruby的(JIRB)外壳
- 支持通过Hadoop指标子系统将指标导出到文件或Ganglia;或通过JMX
Hbase shell
namespace
1. list_namespace:查询所有命名空间
hbase(main):001:0> list_namespace
NAMESPACE
default
hbase
2. list_namespace_tables : 查询指定命名空间的表
hbase(main):014:0> list_namespace_tables 'hbase'
TABLE
meta
namespace
3. create_namespace : 创建指定的命名空间
hbase(main):018:0> create_namespace 'myns'
hbase(main):019:0> list_namespace
NAMESPACE
default
hbase
myns
4. describe_namespace : 查询指定命名空间的结构
hbase(main):021:0> describe_namespace 'myns'
DESCRIPTION
{NAME => 'myns'}
5. alter_namespace :修改命名空间的结构
hbase(main):022:0> alter_namespace 'myns', {METHOD => 'set', 'name' => 'eRRRchou'}
hbase(main):023:0> describe_namespace 'myns'
DESCRIPTION
{NAME => 'myns', name => 'eRRRchou'}
修改命名空间的结构=>删除name
hbase(main):022:0> alter_namespace 'myns', {METHOD => 'unset', NAME => 'name'}
hbase(main):023:0> describe_namespace 'myns'
6. 删除命名空间
hbase(main):026:0> drop_namespace 'myns'
hbase(main):027:0> list_namespace
NAMESPACE
default
hbase
7. 利用新添加的命名空间建表
hbase(main):032:0> create 'myns:t1', 'f1', 'f2'
DDL
1. 查询所有表
hbase(main):002:0> list
TABLE
HelloHbase
kylin_metadata
myns:t1
3 row(s) in 0.0140 seconds
=> ["HelloHbase", "kylin_metadata", "myns:t1"]
2. describe : 查询表结构
hbase(main):003:0> describe 'myns:t1'
{NAME => 'f1', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP
_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMP
RESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '6553
6', REPLICATION_SCOPE => '0'}
{NAME => 'f2', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP
_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMP
RESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '6553
6', REPLICATION_SCOPE => '0'}
3. 创建分片表
hbase(main):007:0> create 'myns:t2', 'f1', SPLITS => ['10', '20', '30', '40']
4. 修改表,添加修改列簇信息
hbase(main):009:0> alter 'myns:t1', {NAME=>'info1'}
hbase(main):010:0> describe 'myns:t1'
5. 删除列簇
hbase(main):014:0> alter 'myns:t1', {'delete' => 'info1'}
hbase(main):015:0> describe 'myns:t1'
6. 删除表
hbase(main):016:0> disable 'myns:t1'
hbase(main):017:0> drop 'myns:t1'
DML
用到的表创建语句:
hbase(main):011:0> create 'myns:user_info','base_info','extra_info'
1. 插入数据(put命令,不能一次性插入多条)
hbase(main):012:0> put 'myns:user_info','001','base_info:username','张三'
2. scan扫描
hbase(main):024:0> scan 'myns:user_info'
3. 通过指定版本查询
hbase(main):024:0> scan 'myns:user_info', {RAW => true, VERSIONS => 1}
hbase(main):024:0> scan 'myns:user_info', {RAW => true, VERSIONS => 2}
4. 查询指定列的数据
hbase(main):014:0> scan 'myns:user_info',{COLUMNS => 'base_info:username'}
5. 分页查询
hbase(main):021:0> scan 'myns:user_info', {COLUMNS => ['base_info:username'], LIMIT => 10, STARTROW => '001'}
6. get查询
hbase(main):015:0> get 'myns:user_info','001','base_info:username'
hbase(main):017:0> put 'myns:user_info','001','base_info:love','basketball'
hbase(main):018:0> get 'myns:user_info','001'
7. 根据时间戳查询 是一个范围,包头不包尾
hbase(main):029:0> get 'myns:user_info','001', {'TIMERANGE' => [1571650017702, 1571650614606]}
8. hbase排序
插入到hbase中去的数据,hbase会自动排序存储:
排序规则: 首先看行键,然后看列族名,然后看列(key)名; 按字典顺序
9. 更新数据
hbase(main):010:0> put 'myns:user_info', '001', 'base_info:name', 'rock'
hbase(main):011:0> put 'myns:user_info', '001', 'base_info:name', 'eRRRchou'
10. incr计数器
hbase(main):053:0> incr 'myns:user_info', '002', 'base_info:age3'
11. 删除
hbase(main):058:0> delete 'myns:user_info', '002', 'base_info:age3'
12. 删除一行
hbase(main):028:0> deleteall 'myns:user_info','001'
13. 删除一个版本
hbase(main):081:0> delete 'myns:user_info','001','extra_info:feature', TIMESTAMP=>1546922931075
14. 删除一个表
hbase(main):082:0> disable 'myns:user_info'
hbase(main):083:0> drop 'myns:user_info'
15. 判断表是否存在
hbase(main):084:0> exists 'myns:user_info'
16. 表生效和失效
hbase(main):085:0> enable 'myns:user_info'
hbase(main):086:0> disable 'myns:user_info'
17. 统计表行数
hbase(main):088:0> count 'myns:user_info'
18. 清空表数据
hbase(main):089:0> truncate 'myns:user_info'
Hbase Java Api
依赖
<dependencies>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>1.4.10version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>testscope>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.10version>
<scope>compilescope>
dependency>
dependencies>
HbaseUtils
public class HbaseUtils {
public static Configuration configuration = null;
public static ExecutorService executor = null;
public static HBaseAdmin hBaseAdmin = null;
public static Admin admin = null;
public static Connection conn = null;
public static Table table;
static {
//1. 获取连接配置对象
configuration = new Configuration();
//2. 设置连接hbase的参数
configuration.set("hbase.zookeeper.quorum", "mini01:2181,mini02:2181,mini03:2181");
//3. 获取Admin对象
try {
executor = Executors.newFixedThreadPool(20);
conn = ConnectionFactory.createConnection(configuration, executor);
hBaseAdmin = (HBaseAdmin)conn.getAdmin();
} catch (Exception e) {
e.printStackTrace();
}
}
public static HBaseAdmin getHbaseAdmin(){
return hBaseAdmin;
}
public static Table getTable(TableName tableName) throws IOException {
return conn.getTable(tableName);
}
public static void close(HBaseAdmin admin){
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void close(HBaseAdmin admin,Table table){
try {
if(admin!=null) {
admin.close();
}
if(table!=null) {
table.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void close(Table table){
try {
if(table!=null) {
table.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void showResult(Result result) throws IOException {
CellScanner scanner = result.cellScanner();
while(scanner.advance()){
Cell cell = scanner.current();
System.out.print("\t" + new String(CellUtil.cloneFamily(cell),"utf-8"));
System.out.print(" : " + new String(CellUtil.cloneQualifier(cell),"utf-8"));
System.out.print("\t" + new String(CellUtil.cloneValue(cell),"utf-8"));
}
}
}
HbaseDemo
public class HbaseDemo {
private HBaseAdmin hBaseAdmin = null;
private Admin admin = null;
@Before
public void init(){
hBaseAdmin = HbaseUtils.getHbaseAdmin();
}
@After
public void after(){
HbaseUtils.close(hBaseAdmin);
}
@Test
public void tableExists() throws IOException { //检查表是否存在
//4. 检验指定表是否存在,来判断是否连接到hbase
boolean flag = hBaseAdmin.tableExists("myns:user_info");
//5. 打印
System.out.println(flag);
}
@Test
public void listNamespace() throws IOException { //遍历命名空间
NamespaceDescriptor[] namespaceDescriptors = hBaseAdmin.listNamespaceDescriptors();
// 打印
for(NamespaceDescriptor namespaceDescriptor:namespaceDescriptors){
System.out.println(namespaceDescriptor);
}
}
@Test
public void listTables() throws Exception{ //获取表的名字
//获取指定命名空间下的表
TableName[] tables = hBaseAdmin.listTableNamesByNamespace("myns");
System.out.println("对应命名空间下的表名:");
for (TableName table:tables){
System.out.println(table);
}
tables = hBaseAdmin.listTableNames();
System.out.println("所有表名:");
for (TableName table:tables){
System.out.println(table);
}
}
@Test
public void createNamespace() throws Exception{ //创建namespace
hBaseAdmin.createNamespace(NamespaceDescriptor.create("eRRRchou").build());
}
@Test
public void createTable() throws Exception{ //创建表
HTableDescriptor descriptor = new HTableDescriptor(TableName.valueOf("myns:user_info"));
//创建列簇
HColumnDescriptor columnDescriptor1 = new HColumnDescriptor("base_info");
columnDescriptor1.setVersions(1, 5); //设置列簇版本从1到5
columnDescriptor1.setTimeToLive(24*60*60); //秒
//创建列簇
HColumnDescriptor columnDescriptor2 = new HColumnDescriptor("extra_info");
columnDescriptor2.setVersions(1, 5);
columnDescriptor2.setTimeToLive(24*60*60); // 秒为单位
//绑定关系
descriptor.addFamily(columnDescriptor1);
descriptor.addFamily(columnDescriptor2);
//创建表
hBaseAdmin.createTable(descriptor);
}
@Test
public void deleteTable() throws Exception{ //删除Family
hBaseAdmin.disableTable("myns:user_info");
hBaseAdmin.deleteTable("myns:user_info");
}
@Test
public void modifyFamily() throws Exception{ //修改列簇
TableName tableName = TableName.valueOf("myns:user_info");
//HTableDescriptor descriptor = new HTableDescriptor(tableName);//原来的列簇消失 new了个新的
HTableDescriptor descriptor = hBaseAdmin.getTableDescriptor(tableName); //获得原来的描述
HColumnDescriptor columnDescriptor = new HColumnDescriptor("extra_info");
columnDescriptor.setVersions(1, 5); //设置列簇版本从1到5
columnDescriptor.setTimeToLive(24*60*60); //秒
descriptor.addFamily(columnDescriptor);
hBaseAdmin.modifyTable(tableName,descriptor);
}
@Test
public void deleteFamily() throws Exception{ //删除Family
hBaseAdmin.deleteColumn("myns:user_info","extra_info");
}
@Test
public void deleteColumeFamily() throws Exception{ ///删除Family
TableName tableName = TableName.valueOf("myns:user_info");
HTableDescriptor tableDescriptor = hBaseAdmin.getTableDescriptor(tableName);
tableDescriptor.removeFamily("extra_info".getBytes());
hBaseAdmin.modifyTable(tableName,tableDescriptor);
}
@Test
public void listFamily() throws Exception{ //遍历Family
TableName tableName = TableName.valueOf("myns:user_info");
HTableDescriptor tableDescriptor = hBaseAdmin.getTableDescriptor(tableName);
HColumnDescriptor[] columnFamilies = tableDescriptor.getColumnFamilies();
for(HColumnDescriptor columnFamilie:columnFamilies){
System.out.println(columnFamilie.getNameAsString());
System.out.println(columnFamilie.getBlocksize());
System.out.println(columnFamilie.getBloomFilterType());
}
}
@Test
public void getTable() throws IOException {
Table table = HbaseUtils.getTable(TableName.valueOf("myns:user_info"));
HbaseUtils.close(table);
}
@Test
public void putDatas() throws IOException {
Table table = HbaseUtils.getTable(TableName.valueOf("myns:user_info"));
Put put = new Put(Bytes.toBytes("001"));
put.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("userName"),Bytes.toBytes("zhangsan"));
put.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("age"),Bytes.toBytes(18));
put.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("sex"),Bytes.toBytes("male"));
//提交
table.put(put);
HbaseUtils.close(table);
}
@Test
public void batchPutDatas() throws IOException {
Table table = HbaseUtils.getTable(TableName.valueOf("myns:user_info"));
//0. 创建集合
List<Put> list = new ArrayList<Put>();
//1. 创建put对象指定行键
Put rk004 = new Put(Bytes.toBytes("002"));
Put rk005 = new Put(Bytes.toBytes("003"));
Put rk006 = new Put(Bytes.toBytes("004"));
//2. 创建列簇
rk004.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("name"),Bytes.toBytes("gaoyuanyuan"));
rk005.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("age"),Bytes.toBytes("18"));
rk005.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("sex"),Bytes.toBytes("2"));
rk006.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("name"),Bytes.toBytes("fanbinbin"));
rk006.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("age"),Bytes.toBytes("18"));
rk006.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("sex"),Bytes.toBytes("2"));
//3. 添加数据
list.add(rk004);
list.add(rk005);
list.add(rk006);
table.put(list);
}
@Test
public void getData() throws Exception{
Table table = HbaseUtils.getTable(TableName.valueOf("myns:user_info"));
Get get = new Get(Bytes.toBytes("001"));
Result result = table.get(get);
NavigableMap<byte[], byte[]> base_infos = result.getFamilyMap(Bytes.toBytes("base_info"));
for(Map.Entry<byte[], byte[]> base_info:base_infos.entrySet()){
String k = new String(base_info.getKey());
String v = "";
if(k.equals("age")) {
v = String.valueOf(Bytes.toInt(base_info.getValue()));
}else{
v = new String(base_info.getValue());
}
System.out.println(k+":"+v);
}
}
@Test
public void getData2() throws IOException {
Table table = HbaseUtils.getTable(TableName.valueOf("myns:user_info"));
//1. 获Get对象
Get get = new Get(Bytes.toBytes("004"));
//2. 通过table获取结果对象
Result result = table.get(get);
//3. 获取表格扫描器
CellScanner cellScanner = result.cellScanner();
System.out.println("rowkey : " + result.getRow());
//4. 遍历
while (cellScanner.advance()) {
//5. 获取当前表格
Cell cell = cellScanner.current();
//5.1 获取所有的列簇
byte[] familyArray = cell.getFamilyArray();
System.out.println(new String(familyArray, cell.getFamilyOffset(), cell.getFamilyLength()));
//5.2 获取所有列
byte[] qualifierArray = cell.getQualifierArray();
System.out.println(new String(qualifierArray, cell.getQualifierOffset(), cell.getQualifierLength()));
//5.3 获取所有的值
byte[] valueArray = cell.getValueArray();
System.out.println(new String(valueArray, cell.getValueOffset(), cell.getValueLength()));
}
}
@Test
public void getData3() throws IOException {
Table table = HbaseUtils.getTable(TableName.valueOf("myns:user_info"));
//1. 获得Get对象
Get get = new Get(Bytes.toBytes("004"));
//2. 通过table获取结果对象
Result result = table.get(get);
//3. 获取表格扫描器
CellScanner cellScanner = result.cellScanner();
//4.遍历
while(cellScanner.advance()){
Cell cell = cellScanner.current();
//获取所有的列簇
System.out.println(new String(CellUtil.cloneFamily(cell),"utf8"));
System.out.println(new String(CellUtil.cloneQualifier(cell),"utf8"));
System.out.println(new String(CellUtil.cloneValue(cell),"utf8"));
}
}
@Test
public void batchGetData() throws IOException {
//1. 创建集合存储get对象
Table table = HbaseUtils.getTable(TableName.valueOf("myns:user_info"));
List<Get> gets = new ArrayList<Get>();
//2. 创建多个get对象
Get get1 = new Get(Bytes.toBytes("004"));
get1.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("name"));
get1.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("sex"));
get1.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("age"));
Get get2 = new Get(Bytes.toBytes("001"));
get2.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("name"));
get2.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("sex"));
Get get3 = new Get(Bytes.toBytes("003"));
get3.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("sex"));
get3.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("age"));
gets.add(get1);
gets.add(get2);
gets.add(get3);
Result[] results = table.get(gets);
for (Result result:results){
HbaseUtils.showResult(result);
}
}
@Test
public void scanTable() throws IOException {
//1. 创建扫描器
Scan scan = new Scan();
//2. 添加扫描的行数包头不包尾
Table table = HbaseUtils.getTable(TableName.valueOf("myns:user_info"));
scan.setStartRow(Bytes.toBytes("001"));
scan.setStopRow(Bytes.toBytes("006" + "\001")); //小技巧
//3. 添加扫描的列
scan.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("name"));
//4. 获取扫描器
ResultScanner scanner = table.getScanner(scan);
Iterator<Result> it = scanner.iterator();
while (it.hasNext()){
Result result = it.next();
HbaseUtils.showResult(result);
}
}
@Test
public void deleteData() throws IOException {
Table table = HbaseUtils.getTable(TableName.valueOf("myns:user_info"));
//1. 创建集合用于批量删除
List<Delete> dels = new ArrayList<Delete>();
//2. 创建删除数据对象
Delete del = new Delete(Bytes.toBytes("004"));
del.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("name"));
//3. 添加到集合
dels.add(del);
//4. 提交
table.delete(dels);
}
}
Hbase过滤器
@Test
public void filter() throws IOException {
//RegexStringComparator 正则
//SubstringComparator; subString比较器
//BinaryComparator 二进制比较器
//and条件
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
SingleColumnValueFilter nameFilter = new SingleColumnValueFilter(Bytes.toBytes("base_info"), Bytes.toBytes("name"),
CompareFilter.CompareOp.LESS_OR_EQUAL,Bytes.toBytes("gaoyuanyuan"));
filterList.addFilter(nameFilter);
Scan scan = new Scan();
scan.setFilter(filterList);
Table table = HbaseUtils.getTable(TableName.valueOf("myns:user_info"));
ResultScanner scanner = table.getScanner(scan);
Iterator<Result> it = scanner.iterator();
while (it.hasNext()){
Result result = it.next();
HbaseUtils.showResult(result);
}
}
@Test
public void familyFilter() throws IOException {
//RegexStringComparator 正则
//SubstringComparator; subString比较器
//BinaryComparator 二进制比较器
//and条件
RegexStringComparator regexStringComparator = new RegexStringComparator("^base");
//2. 创建FamilyFilter:结果中只包含满足条件的列簇信息
FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.EQUAL, regexStringComparator);
//4.创建扫描器进行扫描
Scan scan = new Scan();
//5. 设置过滤器
scan.setFilter(familyFilter);
//6. 获取表对象
Table table = HbaseUtils.getTable(TableName.valueOf("myns:user_info"));
//7. 扫描表
ResultScanner scanner = null;
try {
scanner = table.getScanner(scan);
//8. 打印数据
Iterator<Result> iterator = scanner.iterator();
while (iterator.hasNext()) {
Result result = iterator.next();
HbaseUtils.showResult(result);
}
} catch (IOException e) {
} finally {
try {
table.close();
} catch (IOException e) {
}
}
}
@Test
public void rowFiter() throws IOException {
//1. 创建RowFilter
BinaryComparator binaryComparator = new BinaryComparator(Bytes.toBytes("002"));
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, binaryComparator);
//4.创建扫描器进行扫描
Scan scan = new Scan();
//5. 设置过滤器
scan.setFilter(rowFilter);
//6. 获取表对象
Table table = HbaseUtils.getTable(TableName.valueOf("myns:user_info"));
//7. 扫描表
ResultScanner scanner = null;
try {
scanner = table.getScanner(scan);
//8. 打印数据
Iterator<Result> iterator = scanner.iterator();
while (iterator.hasNext()) {
Result result = iterator.next();
HbaseUtils.showResult(result);
}
} catch (IOException e) {
} finally {
try {
table.close();
} catch (IOException e) {
}
}
}
Hbase原理
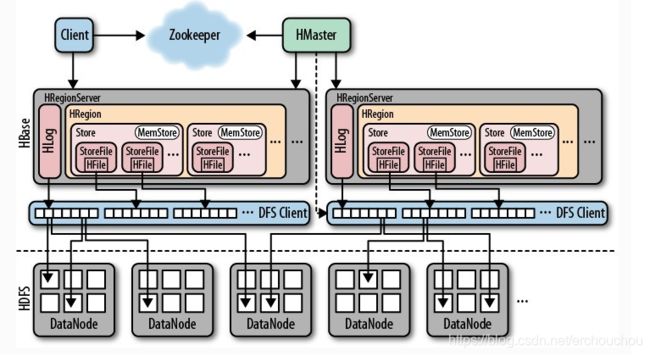
架构
1、Hmaster
- 负责管理Hbase的元数据,表结构,表的Region信息
- 负责表的创建,删除和修改
- 负责为HRegionServer分配Region,分配后将元数据写入相应位置
2、HRegionServer
- 含有多个HRegion
- 处理Client端的读写请求(根据从HMaster返回的元数据找到对应的HRegionServer)
- 管理Region的Split分裂、StoreFile的Compaction合并。
3、HRegion
- 一个HRegion里可能有1个或多个Store。
- HRegionServer维护一个HLog。
- HRegion是分布式存储和负载的最小单元。
- 表通常被保存在多个HRegionServer的多个Region中。
4、Store
- Store是存储落盘的最小单元,由内存中的MemStore和磁盘中的若干StoreFile组成。
- 一个Store里有1个或多个StoreFile和一个memStore。
- 每个Store存储一个列族。
Hbase读写流程
写数据流程
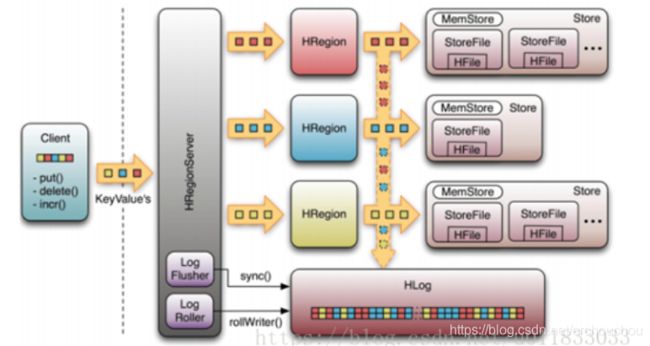
-
Client访问ZK,根据ROOT表获取meta表所在Region的位置信息,并将该位置信息写入Client Cache。
(注:为了加快数据访问速度,我们将元数据、Region位置等信息缓存在Client Cache中)。 -
Client读取meta表,再根据meta表中查询得到的Namespace、表名和RowKey等相关信息,获取将要写入Region的位置信息(此过程即Region三层定位,如下图),最后client端会将meta表写入Client Cache。
-
Hbase使用memstore和storefile存储对表的更新,数据在更新时首先写入hlog和memstore,memstore是排序的。
-
当memstore积累到一定的阈值时,就会创建一个新的memstore,并将老的memstore加入flush队列,由单独的线程flush到磁盘上,成为一个StoreFile
-
系统Zookeeper中记录一个checkpoint,表示这个时刻之前的数据变更已经持久化,发生故障只需要恢复checkpoint的数据
-
storefile是只读的,一旦创建之后就不可修改,当一个store的storefile达到一定的阀值后,就会进行一次合并操作,将对同一个key的修改合并到一起,同时进行版本合并和数据删除,形成一个大的storefile。当storefile的大小达到一定的阀值后,又会对storefile进行切分操作,等分为两个storefile。
-
Hbase中只有增添数据,所有的更新和删除操作都是在后续的合并中进行的,使得用户的写操作只要进入内存就可以立刻返回,实现了hbase的高速存储。
(1) Client通过Zookeeper的调度,向RegionServer发出写数据请求,在Region中写数据。
(2) 数据被写入Region的MemStore,直到MemStore达到预设阈值。
(3) MemStore中的数据被Flush成一个StoreFile。
(4) 随着StoreFile文件的不断增多,当其数量增长到一定阈值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除。
(5) StoreFiles通过不断的Compact合并操作,逐步形成越来越大的StoreFile。
(6) 单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个新的Region。父Region会下线,新Split出的2个子Region会被HMaster分配到相应的RegionServer上,使得原先1个Region的压力得以分流到2个Region上。
Hbase的存储机制
存储模型

1. 每一次的插入操作都会先进入MemStore(内存缓冲区),
2. 当 MemStore达到上限的时候,Hbase会将内存中的数据输出为有序的StoreFile文件数据(根据Rowkey、版本、列名排序,这里已经和列簇无关了因为Store里都属于同一个列簇)。
3. 这样会在Store中形成很多个小的StoreFile,当这些小的File数量达到一个阀值的时 候,Hbase会用一个线程来把这些小File合并成一个大的File。这样,Hbase就把效率低下的文件中的插入、移动操作转变成了单纯的文件输出、 合并操作。
由上可知,在Hbase底层的Store数据结构中,
1) 每个StoreFile内的数据是有序的,
2) 但是StoreFile之间不一定是有序的,
3) Store只 需要管理StoreFile的索引就可以了。
这里也可以看出为什么指定版本和Rowkey可以加强查询的效率,因为指定版本和Rowkey的查询可以利用 StoreFile的索引跳过一些肯定不包含目标数据的数据。

布隆过滤器
它的时间复杂度是O(1),但是空间占用取决其优化的方式。它是布隆过滤器的基础。
布隆过滤器(Bloom Filter)的核心实现是一个超大的位数组(或者叫位向量)和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k
假设集合里面有3个元素{x, y, z},哈希函数的个数为3。
Step1:将位数组初始化,每位都设置为0。
Step2:对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,哈希值对应位数组上面的一个点,将该位置标记为1。
Step3:查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。
Step4:如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。
可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
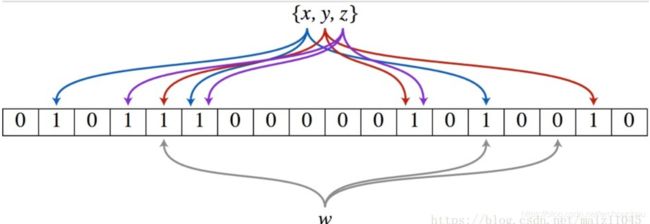
- 布隆过滤器应用在Hbase
当我们随机读get数据时,如果采用hbase的块索引机制,hbase会加载很多块文件。如果采用布隆过滤器后,它能够准确判断该HFile的所有数据块中,是否含有我们查询的数据,从而大大减少不必要的块加载,从而增加hbase集群的吞吐率。这里有几点细节:
1. 布隆过滤器的存储在哪?
对于hbase而言,当我们选择采用布隆过滤器之后,HBase会在生成StoreFile(HFile)时包含一份布隆过滤器结构的数据,称其为MetaBlock;MetaBlock与DataBlock(真实的KeyValue数据)一起由LRUBlockCache维护。所以,开启bloomfilter会有一定的存储及内存cache开销。但是在大多数情况下,这些负担相对于布隆过滤器带来的好处是可以接受的。
2. 采用布隆过滤器后,hbase如何get数据?
在读取数据时,hbase会首先在布隆过滤器中查询,根据布隆过滤器的结果,再在MemStore中查询,最后再在对应的HFile中查询。
3. 采用ROW还是ROWCOL布隆过滤器?
这取决于用户的使用模式。如果用户只做行扫描,使用更加细粒度的行加列布隆过滤器不会有任何的帮助,这种场景就应该使用行级布隆过滤器。当用户不能批量更新特定的一行,并且最后的使用存储文件都含有改行的一部分时,行加列级的布隆过滤器更加有用。
tip:
ROW和ROWCOL只是名字上有联系,但是ROWCOL并不是ROW的扩展,也不能取代ROW
2.6.10 Hbase的寻址机制
读数据流程
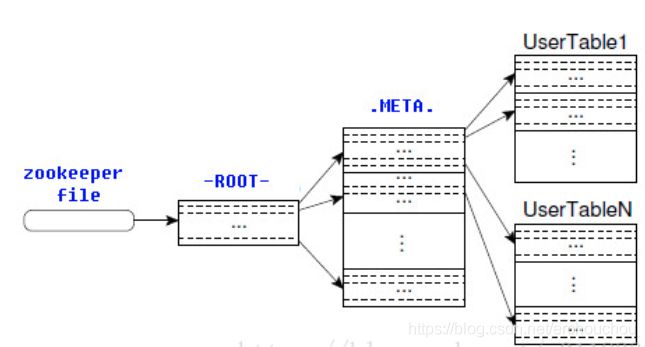
(1) Client访问Zookeeper,查找-ROOT-表,获取.META.表信息。
(2) 从.META.表查找,获取存放目标数据的Region信息,从而找到对应的RegionServer。
(3) 通过RegionServer获取需要查找的数据。
(4) Regionserver的内存分为MemStore和BlockCache两部分,MemStore主要用于写数据,BlockCache主要用于读数据。读请求先到MemStore中查数据,查不到就到BlockCache中查,再查不到就会到StoreFile上读,并把读的结果放入BlockCache。
StoreFile合并
目的:减少StoreFile数量,提升数据读取效率。
Compaction分为两种:
major compaction
将Store下面所有StoreFile合并为一个StoreFile,此操作会删除其他版本的数据(不同时间戳的)
minor compaction
选取Store下的部分StoreFile,将它们合并为一个StoreFile,此操作不会删除其他版本数据。
Region分割
目的:实现数据访问的负载均衡。
做法:利用Middle Key将当前Region划分为两个等分的子Region。需要指出的是:Split会产生大量的I/O操作,Split开始前和Split完成后,HRegionServer都会通知HMaster。Split完成后,由于Region映射关系已变更,故HRegionServer会更新meta表。
Hbase2Hdfs
class HbaseMapper extends TableMapper<Text, NullWritable> {
private Text k = new Text();
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
//0. 定义字符串存放最终结果
StringBuffer sb = new StringBuffer();
//1. 获取扫描器进行扫描解析
CellScanner cellScanner = value.cellScanner();
//2. 推进
while (cellScanner.advance()) {
//3. 获取当前单元格
Cell cell = cellScanner.current();
//4. 拼接字符串
sb.append(new String(CellUtil.cloneQualifier(cell)));
sb.append(":");
sb.append(new String(CellUtil.cloneValue(cell)));
sb.append("\t");
}
//5. 写出
k.set(sb.toString());
context.write(k, NullWritable.get());
}
}
public class Hbase2Hdfs implements Tool {
private Configuration configuration;
private final static String HBASE_CONNECT_KEY = "hbase.zookeeper.quorum";
private final static String HBASE_CONNECT_VALUE = "mini01:2181,mini02:2181,mini03:2181";
private final static String HDFS_CONNECT_KEY = "fs.defaultFS";
private final static String HDFS_CONNECT_VALUE = "hdfs://mini01/";
private final static String MAPREDUCE_CONNECT_KEY = "mapreduce.framework.name";
private final static String MAPREDUCE_CONNECT_VALUE = "yarn";
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(configuration, "hbase2hdfs");
job.setJarByClass(Hbase2Hdfs.class);
TableMapReduceUtil.initTableMapperJob("myns:user_info", getScan(), HbaseMapper.class,
Text.class, NullWritable.class, job);
FileOutputFormat.setOutputPath(job,new Path("/hbaseout/04"));
boolean b = job.waitForCompletion(true);
return b ? 1 : 0;
}
@Override
public void setConf(Configuration configuration) {
configuration.set(HBASE_CONNECT_KEY, HBASE_CONNECT_VALUE); // 设置连接的hbase
configuration.set(HDFS_CONNECT_KEY, HDFS_CONNECT_VALUE); // 设置连接的hadoop
configuration.set(MAPREDUCE_CONNECT_KEY, MAPREDUCE_CONNECT_VALUE); // 设置使用的mr运行平台
this.configuration = configuration;
}
@Override
public Configuration getConf() {
return configuration;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(HBaseConfiguration.create(), new Hbase2Hdfs(), args);
}
private static Scan getScan() {
return new Scan();
}
}
Hdfs2Hbase
public class Hdfs2Hbase implements Tool {
private void createTable(String tablename) {
//1. 获取admin对象
HBaseAdmin admin = HbaseUtils.getHbaseAdmin();
//2.
try {
boolean isExist = admin.tableExists(TableName.valueOf(tablename));
if(isExist) {
admin.disableTable(TableName.valueOf(tablename));
admin.deleteTable(TableName.valueOf(tablename));
}
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf(tablename));
HColumnDescriptor columnDescriptor2 = new HColumnDescriptor("age_info");
columnDescriptor2.setBloomFilterType(BloomType.ROW);
columnDescriptor2.setVersions(1, 3);
tableDescriptor.addFamily(columnDescriptor2);
admin.createTable(tableDescriptor);
} catch (IOException e) {
e.printStackTrace();
}finally {
HbaseUtils.close(admin);
}
}
public static class HBaseMapper extends Mapper<LongWritable, Text,Text,LongWritable>{
Text text = new Text();
LongWritable lw = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] datas = line.split(",");
text.set(datas[0]);
lw.set(Long.parseLong(datas[1]));
context.write(text,lw);
}
}
public static class HBaseReducer extends TableReducer<Text, LongWritable, ImmutableBytesWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//1. 计数器
long count = 0l;
//2. 迭代
Iterator<LongWritable> iterator = values.iterator();
//3. 输出一定要是可以修改hbase的对象,put,delete
Put put = new Put(Bytes.toBytes(key.toString()));
String value = values.iterator().next().toString();
//4. 将结果集写入put对象
put.addColumn(Bytes.toBytes("age_info"), Bytes.toBytes("age"), Bytes.toBytes(value));
//5. 写
context.write(new ImmutableBytesWritable(Bytes.toBytes(key.toString())), put);
}
}
//1. 创建配置对象
private Configuration configuration;
private final static String HBASE_CONNECT_KEY = "hbase.zookeeper.quorum";
private final static String HBASE_CONNECT_VALUE = "mini01:2181,mini02:2181,mini03:2181";
//private final static String HDFS_CONNECT_KEY = "fs.defaultFS";
// private final static String HDFS_CONNECT_VALUE = "hdfs://mini01/";
//private final static String MAPREDUCE_CONNECT_KEY = "mapreduce.framework.name";
// private final static String MAPREDUCE_CONNECT_VALUE = "yarn";
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(configuration);
job.setJarByClass(Hdfs2Hbase.class);
job.setMapperClass(HBaseMapper.class);
job.setReducerClass(HBaseReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
String tablename = "user_infomation";
createTable(tablename);
FileInputFormat.setInputPaths(job,new Path("D://information.txt"));
TableMapReduceUtil.initTableReducerJob(tablename,HBaseReducer.class,job);
return job.waitForCompletion(true)?1:0;
}
@Override
public void setConf(Configuration conf) {
conf.set(HBASE_CONNECT_KEY, HBASE_CONNECT_VALUE); // 设置连接的hbase
//conf.set(HDFS_CONNECT_KEY, HDFS_CONNECT_VALUE); // 设置连接的hadoop
//conf.set(MAPREDUCE_CONNECT_KEY, MAPREDUCE_CONNECT_VALUE); // 设置使用的mr运行平台
this.configuration = conf;
}
@Override
public Configuration getConf() {
return configuration;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(HBaseConfiguration.create(), new Hdfs2Hbase(), args);
}
}