otter基于docker安装
项目介绍
名称:otter ['ɒtə(r)]
译意: 水獭,数据搬运工
语言: 纯java开发
定位: 基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库. 一个分布式数据库同步系统
工作原理

原理描述:
1. 基于Canal开源产品,获取数据库增量日志数据。 什么是Canal, 请点击
2. 典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上
3. 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.
安装
mysql
docker run --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=数据库密码 -d mysql:5.7.19 --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci;
新建otter数据库
otter-manager-schema.sql
ZK
docker run -d -p 2181:2181 --name=zookeeper --privileged zookeeperotter-manager
docker run --name otter-manager -d -p 8080:8080 -p 1099:1099 -e IP=当前服务器IP -e ZK_IP=ZK地址 -e DB_IP=数据库IP:3306 -e DB_USER=数据库账号 -e DB_PASSWD=数据库密码 aeert/otter-manager:4.2.18![]() 访问 http://当前服务器IP:8080 账号密码:admin/admin
访问 http://当前服务器IP:8080 账号密码:admin/admin

NODE
1. otter node会受otter manager进行管理,所以需要预先安装otter manager,参见:Otter Manager Quickstart.
2. 完成manager安装后,需要在manager页面为node定义配置信息,并生一个唯一id.
a. 首先访问manager页面的机器管理页面,点击添加机器按钮

几点说明:
- 机器名称:可以随意定义,方便自己记忆即可
- 机器ip:对应node节点将要部署的机器ip,如果有多ip时,可选择其中一个ip进行暴露. (此ip是整个集群通讯的入口,实际情况千万别使用127.0.0.1,否则多个机器的node节点会无法识别)
- 机器端口:对应node节点将要部署时启动的数据通讯端口,建议值:2088
- 下载端口:对应node节点将要部署时启动的数据下载端口,建议值:9090
- 外部ip :对应node节点将要部署的机器ip,存在的一个外部ip,允许通讯的时候走公网处理。
- zookeeper集群:为提升通讯效率,不同机房的机器可选择就近的zookeeper集群.
node这种设计,是为解决单机部署多实例而设计的,允许单机多node指定不同的端口
b. 机器添加完成后,跳转到机器列表页面,获取对应的机器序号nid
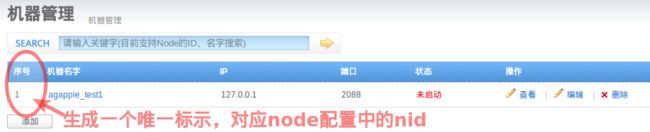
通过这两部操作,获取到了node节点对应的唯一标示,称之为node id,简称:nid. 记录该nid,后续启动nid时会使用
3. node节点进行跨机房传输时,会使用到HTTP多线程传输技术,目前主要依赖了aria2c做为其下载客户端,后续会推出java版本.
a. aria2 官方首页: http://aria2.sourceforge.net/
b. 下载页面: http://sourceforge.net/projects/aria2/files/stable/
当前测试过多个HTTP多线程下载客户端,比如wget,curl,axel,oget,proz,aria2c,测试结果aria2c下载效率最快,基本可以压满网卡.
注意:下载完成或者编译完成后,将对应的aria2c包加入到PATH路径即可.
安装
获取到node的ID后执行
docker run --name otter-node -d -p 2088:2088 -p 2090:2090 -p 9090:9090 -e id=node的ID -e address=当前服务器IP aeert/otter-node:4.2.18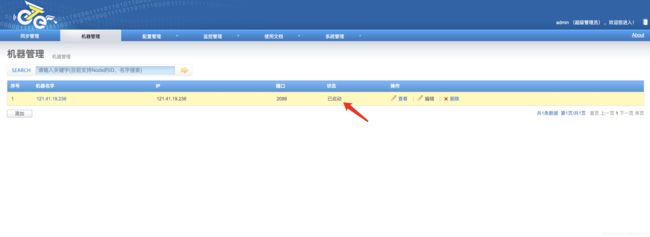
测试

新建数据库01、02,注意数据库已开启binlog,并且binlog_format为ROW
搭建一个数据库同步任务,源数据库ip为:10.20.144.25,目标数据库ip为:10.20.144.29. 源数据库已开启binlog,并且binlog_format为ROW.
mysql> show variables like '%binlog_format%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+2. 数据同步精确到一张表进行测试,测试的表名为test.example,简单包含两个子段,测试过程中才创建.
3. 配置完成后,手动在源库插入数据,然后快速在目标库进行查看数据,验证数据是否同步成功.
-------
视频中的演示文本:
CREATE TABLE `test`.`example` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(32) COLLATE utf8_bin DEFAULT NULL ,
PRIMARY KEY (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into test.example(id,name) values(null,'hello');
-----
Otter QuickStart 如何配置一个任务
-----
操作步骤:
1. 添加数据库
a. 源库 jdbc:mysql://10.20.144.25:3306
b. 目标库 jdbc:mysql://10.20.144.29:3306
2. 添加canal
a. 提供数据库ip信息
3. 添加同步表信息
a. 源数据表 test.example
b. 目标数据表 test.example
4. 添加channel
5. 添加pipeline
a. 选择node节点
b. 选择canal
6. 添加同步映射规则
a. 定义源表和目标表的同步关系
7. 启动
8. 测试数据
参考官网文档:alibaba/otter
QQ交流群号:132381997