【CVPR 2018】Learning Rich Features for Image Manipulation Detection(图像篡改检测)
今天来给大家分享一篇CVPR2018的论文,检测图像的篡改区域,用更快的R-CNN网络定位图像被篡改的部分,练就PS检测的火眼金睛。让PS痕迹无处可逃。这就将图像鉴伪,图像取证这方面与深度学习技术结合起来啦。针对这篇论文的分享,做了一个PPT,放到CSDN的下载专区,有论文的PDF(带部分注解),有PPT可修改。下载链接如下https://download.csdn.net/download/luolan9611/10681683
在分享论文前,先POU两个链接,说点和图像取证有关的:
1. “谁动了我的图片?” - 图像取证技术
在这篇文章中,介绍了一些常见的图像篡改的方法和检测篡改的技术,很有趣。
2. 深度学习在图像取证中的进展与趋势
这篇文章介绍了5篇深度学习应用于取证领域的工作,涉及到了取证问题中的相机源取证,中值滤波取证,重获取图像取证以及反反取证,还列有很多参考文献。
================================================== =============================================
一,概述
先给大家展示一下论文中提到的三种图像篡改手段:
拼接指的是把别的图里面的某个物体拼接到另一张图上。
复制举动是同一张图上,进行部分区域的拷贝,然后放到该图中的其它地方。
去除是指对像素进行修改,将某部分图像“移除”。

第一列是真实图像,第二列是P过的图,第三列是真实数据的掩膜展现出篡改的区域。
1.本文提出了一个双流Faster R-CNN网络并训练它端到端以检测给定图像的篡改区域。
2.双流指的是 RGB流和噪声流。RGB流的目的是从RGB图像输入中提取特征以找到诸如强对比度差异,非自然篡改边界等的篡改特征;噪声流是利用从富含隐写分析的模型滤波器(SRM)层提取的噪声特征来发现真实和篡改区域之间的噪声不一致。
3.作者通过双线性池化层融合来自两个流的特征,以进一步结合这两种模态的空间共现。
4.在四个标准图像处理数据集上的实验表明本文的双流框架优于每个单独的流,并且与其他方法相比,在压缩图像和resize大小的图像的检测上表现出了该方法的鲁棒性,达到了最先进的性能。
二、Method-双流Faster R-CNN
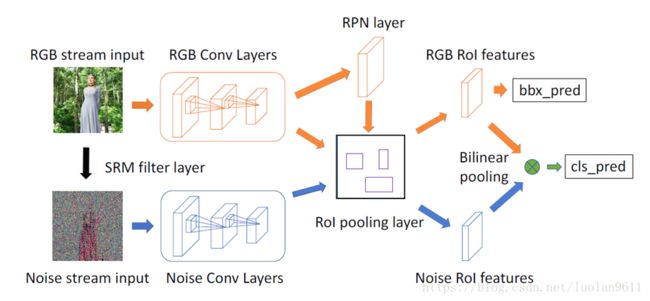
这是本文提出的方法,双流Faster R-CNN网络:
如上图所示,橘黄色的箭头连起来的是RGB流,蓝色的箭头连起来的是噪声流。每个单独的流其实都是一个Faster R-CNN。熟悉Faster R-CNN的朋友应该很容易看懂。
RGB流以RGB图像作为输入,利用对象边缘的异常高对比度(解释1),并将边界框回归到真实值。噪声流首先通过将输入RGB图像传递通过SRM滤波器层(解释2)来获得噪声特征图,并利用噪声特征来为操纵分类提供额外的证据。 RGB和噪声流共享来自RPN网络的相同区域提议,但RPN网络仅使用RGB特征作为输入(就是黄色箭头指向了RPN layer的那里)(解释3)。RoI池化层从RGB和噪声流中选择空间特征。预测的边界框(表示为'bbx pred')是从RGB RoI特征生成的。在RoI池之后的双线性池化层使网络能够组合来自两个流的空间共现特征。最后,通过完全连接的层和softmax层传递结果,网络产生预测的标签(表示为'cls pred')并确定预测区域是否已被操纵。

第一列:篡改区域在原始RGB图像上的展示
第二列:第一列图中红色bounding box的放大图。棒球运动员边缘的高度不自然提供了篡改的线索。
第三列:经过SRM filter过滤后的局部噪声特征,展现了篡改区域与真实区域局部噪声的不一致性。
第四列:正确标记的数据
解释1:看上图第一行第二个,棒球手的裤边,这里就是异常的高对比度。
解释2:图像在输入到噪声流前要先经过SRM过滤器过滤,得到局部噪声特征,才能作为噪声流的输入。看上图第二列。
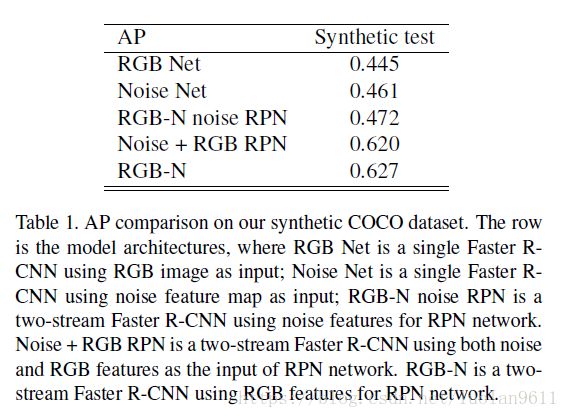
解释3:为什么只选择RGB特征座位RPN(区域候选模块)的输入呢?回答:是由实验对比出来的选择。本文作者做了单流网络、RPN采用不同输入的双流网络在检测篡改区域上的对比实验。结果如下表,不仅表明双流比单流的效果出色,也表明了仅采用RGB特征作为RPN输入的双流的效果是最好的。
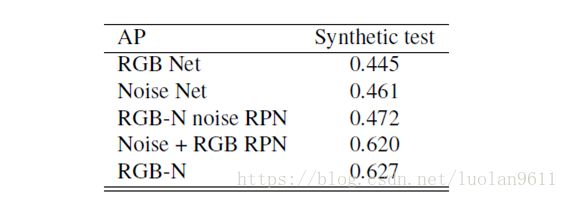
RGB Net指的是仅使用RGB单流检测篡改区域,
Noise Net仅使用噪声流,
RGB-N noise RPN是指双流,但采用noise特征作为RPN输入,
Noise+RGB RPN是指双流,同时采用noise和RGB特征作为RPN输入,
RGB-N是指双流,仅采用RGB特征作为RPN输入。(这是本文最终采用的方法)
2.1RGB流
RGB流是单一的Faster R-CNN网络,用于bounding box的回归和篡改分类。本文使用的是ResNet101网络从输入的RGB图像中学习特征。ResNet的最后一层用于篡改分类。RPN网络利用RGB流中的特征去提取ROI区域,用于boundng box的回归。RPN网络的loss值定义如下:(具体含义见论文)
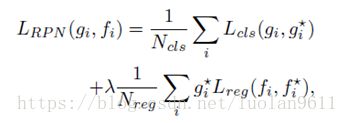
2.2噪声流
噪声流是利用从富含隐写分析的模型滤波器(SRM)层提取的噪声特征来发现真实和篡改区域之间的噪声不一致。SRM收集基本的噪声特征,量化并截断这些过滤器的输出,并提取附近的共现信息作为最终特征。本文只使用3个内核了获得不错的性能,且应用所有30个内核并没有显着提高性能。因此,作者选择了3个内核,并直接将这些内核提供给经过预先训练的网络训练在3通道输入上。SRM层的输出通道大小为3。更多和SRM相关的详见论文中引用的一篇论文。在这里pou一下用于提取噪声特征的3个SRM filter kernel。

2.3双线性池化
双线性池化把RGB流和噪声流结合到一起的同时保留了空间信息。双线性池化层输出为x,![]() , fRGB是RGB流的ROI特征,fN是噪声流的ROI特征。
, fRGB是RGB流的ROI特征,fN是噪声流的ROI特征。
总的loss函数![]()
(写博客写了这么长还没有写完,我的耐心都快被磨光了.......一个强迫症的耐心,唉)
三、实验部分
3.1预训练模型
当前的标准数据集没有足够的数据用于深度神经网络训练。为了在这些数据集上测试提出的网络,作者在合成数据集上预先训练模型。
1.使用COCO中的图像和注释自动创建合成数据集。最后,作者创建了42K篡改和真实的图像对。分开训练集和测试集。
2.模型的输出是带有置信度分数的边界框,表示检测到的区域是否已被篡改。要在感兴趣区域(RoI)中包含一些真实区域以便更好地进行比较,作者会在训练期间将默认边界框略微放大20像素,以便RGB和噪声流都能够了解篡改区域和真实区域之间的不一致性。
3.在这个合成数据集上端到端地训练我们的模型。在Faster R-CNN中使用的ResNet 101在ImageNet上进行了预训练。作者使用平均精度(AP)进行评估,其度量与COCO 检测评估相同。
这个预训练得到的表就是之前给大家pou过的那个
3.2在标准数据集上的实验
3.2.1 4个标准数据集
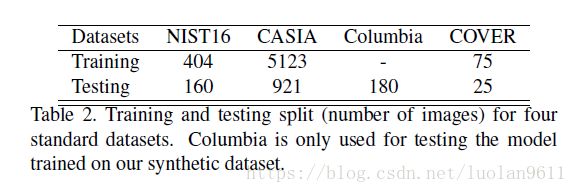
NIST16:该数据集包含了之前提到的三种图像篡改手段, 对该数据集中的操作进行后处理以隐藏可见迹线。 它们还提供用于评估的真实值篡改掩模。
CASIA:提供各种对象的拼接和复制移动( copy-move )图像。仔细选择篡改区域,并且还应用诸如过滤和模糊的一些后处理。通过对篡改图像和原始图像之间的差异进行阈值处理来获得地面实况掩模。本文使用CASIA 2.0进行训练,使用CASIA 1.0进行测试。
COVER:是一个相对较小的数据集,专注于copy-move.它覆盖与粘贴区域类似的对象,以隐藏篡改区域(参见图1中的第二行)。提供真实值掩模。
Columbia:哥伦比亚数据集侧重于基于未压缩图像的拼接。提供真实值掩模。
为了在这些数据集上微调本文的模型,本文从真实值掩模中提取边界框。训练集和测试集的划分见表2。
3.2.2 Baseline Models
•ELA:一种错误级别分析方法,旨在通过不同的JPEG压缩等级找出篡改区域和真实区域之间的压缩误差。
•NOI1:基于噪声不一致的方法,使用高通小波系数来模拟局部噪声。
•CFA1:CFA模式估计方法,它使用附近的像素来近似相机滤波器阵列模式,然后产生每个像素的篡改概率。
•MFCN:基于多任务边缘增强FCN的网络使用边缘二进制掩码和使用篡改区域掩码的篡改区域联合检测篡改边缘。
•J-LSTM:基于LSTM的网络联合训练补丁级别篡改边缘分类和像素级别篡改区域分割。
•RGB Net:单个Faster R-CNN网络,RGB图像作为输入。即,我们的RGB Faster R-CNN流。
•噪声网:单个Faster R-CNN网络,其噪声特征映射作为从SRM滤波器层获得的输入。在这种情况下,RPN网络使用噪声特征。
•Late Fusion:直接融合,结合RGB Net和噪声网络的所有检测到的边界框。来自两个流的重叠检测区域的置信度得分被设置为最大值。
•RGB-N:用于操作分类的RGB流和噪声流的双线性池和用于边界框回归的RGB流。即本文的完整模型。
3.2.3 评估标准
使用像素级别F1得分和接收器操作特性曲线下的面积(AUC)作为性能比较的评估指标。 F1得分是用于图像操纵检测的像素级评估度量,如[33,29]中所讨论的。 我们改变不同的阈值,并使用最高的F1分数作为每个图像的最终得分,遵循[33,29]中的相同协议。 我们将置信度分数分配给检测到的边界框中的每个像素,以进行像素级AUC评估。
3.2.4 实验结果

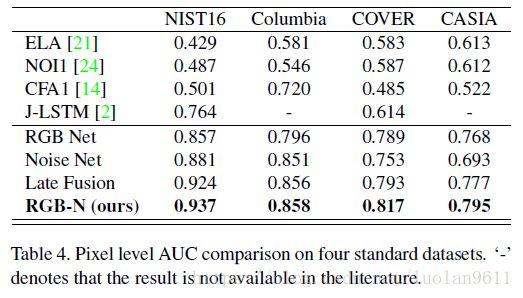
表3显示了本文的方法和baseline model之间的F1分数比较。 表4提供了AUC比较。从这两个表中可以清楚地看出,本文的方法优于传统方法,如ELA,NOI1和CFA1。 这是因为它们都专注于特定的篡改工件,这些篡改工件仅包含用于本地化的部分信息,这限制了它们的性能。 本文的方法在哥伦比亚和NIST16数据集上优于MFCN。表3也能看出双流的性能比单流好。

Table5:不同数据增强方法对性能的影响。图像翻转提高了性能,而JPEG压缩和噪声等其他增强方法对性能几乎没有改进。
表6 :在resize 和经过jpeg 压缩后的数据上进行实验,本文的方法表现最优。
表7 :移动复制的英文。本文提出的方法中最难检测的,篡改技术。解释是,一方面,复制的区域来自同一图像,这产生类似的噪声分布以混淆我们的噪声流另一方面,这两个区域通常具有相同的对比度。而且,该技术理想地需要将两个对象彼此进行比较(即,它需要同时找到并比较两个投资回报),这是当前方法不能做到的。因此,我们的RGB 流没有证据来区分这两个区域。
四,可视化结果展示

第一列是篡改后的图像,第二列的白色区域是篡改区域,第三列和第四列都是单流,最后一列是本文的双流方法可视化的结果。可以看到单流的检测不准确,双流的效果很不错。

终于写完啦!!!!!还是老样子,针对这篇论文的分享,做了一个PPT,放到CSDN的下载专区,有论文的PDF(带部分注解),有PPT可修改下载链接:https://download.csdn.net/download/luolan9611/10681683