缓存——redis
1、数据结构
String存入字符类型
list 链表 (双向链表)
set无序集合
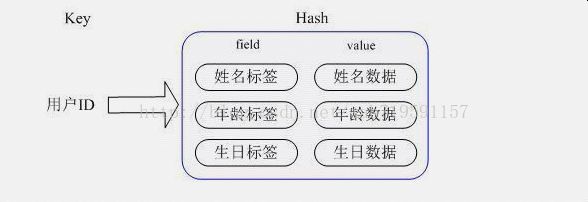
Hash 方便存对象 键值对
Zset有序集合
2、大对象存储使用哪种结构,为什么
Hset,可以使用命令进行对象中数据的更改
hset 则是以hash 散列表的形式存储
例如 吧张三的年龄改为30 则可以使用命令: hset user_1 age 30
在比如如果要缓存应用整个首页 html ,或则某个商品的详情介绍(一般来说商品的详情介绍是makdown语法的富文本信息,或 html 格式的富文本信息) 则使用 则可以使用 set
又或则 应用中的 某个热点数据,都可以使用 set 存储一大段数据。
3、怎么实现线程隔离
Setnx命令进行实现
利用redis实现分布式事务锁,解决高并发环境下库存扣减:
问题描述:
某电商平台,首发一款新品手机,每人限购2台,预计会有10W的并发,在该情况下,如果扣减库存,保证不会超卖
解决方案一
利用数据库锁机制,对记录进行锁定,再进行操作
SELECT * from goods where ID =1 for update;
UPDATE goods set stock = stock - 1;
利用排它锁将并行转化为串行操作,但该方案的性能和用户体验较差
解决方案二
利用redis 实现分布式锁,
使用setnx命令(在key不存在时,创建并设置value 返回1,key存在时,会反回0)来获取锁,在业务逻辑中,我们可以通过这样的方案来操作
Jedis client = jedisPool.getResource(); while(client.setnx("lock",String.valueOf(System.currentTimeMillis())) == 0){ Thread.sleep(10000); } //coding here client.del("lock")方案二进阶
考虑到死锁问题,即线程A获取锁后,宕机了,导致锁一直无法释放,我们可以通过get命令获取锁的时间戳,通过他进行超时判断,并进行释放
Long TIMEOUT_SECOUND = 120000L; Jedis client = jedisPool.getResource();while(client.setnx("lock",String.valueOf(System.currentTimeMillis())) == 0){ Long lockTime = Long.valueOf(client.get("lock"));if (lockTime!=null && System.currentTimeMillis() > lockTime+TIMEOUT_SECOUND) {client.del("lock");}Thread.sleep(10000);
} //coding here client.del("lock")方案二加强
方案2的算法中,为了确保在非超时情况下,锁只能由有锁的线程进行释放,可以在value的时间戳中,拼上线程特征码
Long TIMEOUT_SECOUND = 120000L;String featureCode = "machine01"; Jedis client = jedisPool.getResource(); while(client.setnx("lock",featureCode+":"+String.valueOf(System.currentTimeMillis())) == 0){ Long lockTime = Long.valueOf(client.get("lock").substring(9)); if (lockTime!=null && System.currentTimeMillis() > lockTime+TIMEOUT_SECOUND) {client.del("lock");}Thread.sleep(10000);
} //coding here if (featureCode.equals(client.get("lock").substring(0, 8))) { client.del("lock"); }
4、怎么实现队列
PUSH/POP
Redis中五大数据结构之一—列表,其PUSH和POP命令遵循FIFO先进先出原则。当我们需要发布消息的时候执行LPUSH(消息从左边进入队列),消息接收端执行RPOP获得消息(消息从右侧弹出)。对于列表,Redis提供了带有阻塞的命令(命令前加B)。因此,生产者lpush消息,消费者brpop(从列表中弹出最右端元素,如无元素则一直阻塞到timeout)消息,并设定超时时间timeout,可以减少redis的压力。
优点:消息可以持久化。
缺点:一条消息只能被一个消费者接受,消费者完全靠手速来获得。是一种比较简陋的消息队列。
PUB/SUB
Redis自带有PUB/SUB机制,即发布-订阅模式。这种模式生产者(producer)和消费者(consumer)是1-M的关系,即一条消息会被多个消费者消费,当只有一个消费者时即可以看做一个1-1的消息队列。
PUB/SUB机制模型如下,Channel可以看成一个用发布消息的频道,只要client订阅了(subscribe)这个频道,就能获得次频道的消息。
最基本的使用
订阅一个或多个频道:
subscribe channel [channel2 channel3 。。。。 ]
client1订阅channel:
client2订阅channel1:
client3发布消息到channel 和channel1:
command:publish channel “content”
可以看到,client1和client2都得到了消息。
5、redis的使用场景
一般的数据缓存(类似memcache)
二、队列应用
非实时业务如发放积分或需要削峰降流的秒杀等场景都会用到队列。
三、发布订阅
四、计数器
由于mysql等累加往往扛不住高并发,所以需要原子性操作的reids来统计数量。
五、排行榜
关于有序集实现redis排行榜,微博的热榜就是很好的例子。
六、资源锁
这个秒杀的时候往往也会用到,防止超卖等现象发生,当然还有很多其他防并发的用途。
6、redis的常见问题,击穿、雪崩等
(一)缓存和数据库间数据一致性问题
分布式环境下(单机就不用说了)非常容易出现缓存和数据库间的数据一致性问题,针对这一点的话,只能说,如果你的项目对缓存的要求是强一致性的,那么请不要使用缓存。我们只能采取合适的策略来降低缓存和数据库间数据不一致的概率,而无法保证两者间的强一致性。合适的策略包括 合适的缓存更新策略,更新数据库后要及时更新缓存、缓存失败时增加重试机制,例如MQ模式的消息队列。
(二)缓存击穿问题
缓存击穿表示恶意用户模拟请求很多缓存中不存在的数据,由于缓存中都没有,导致这些请求短时间内直接落在了数据库上,导致数据库异常。这个我们在实际项目就遇到了,有些抢购活动、秒杀活动的接口API被大量的恶意用户刷,导致短时间内数据库宕机了,好在数据库是主从结构,同时也有进行接口限流,hold的住。
解决方案的话:
方案1、使用互斥锁排队
业界比价普遍的一种做法,即根据key获取value值为空时,锁上,从数据库中load数据后再释放锁。若其它线程获取锁失败,则等待一段时间后重试。这里要注意,分布式环境中要使用分布式锁,单机的话用普通的锁(synchronized、Lock)就够了。
方案2、布隆过滤器(推荐)
bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小
(三)缓存雪崩问题
缓存在同一时间内大量键过期(失效),接着来的一大波请求瞬间都落在了数据库中导致连接异常。
解决方案:
方案1、也是像解决缓存穿透一样加锁排队,实现同上;
方案2、建立备份缓存,缓存A和缓存B,A设置超时时间,B不设值超时时间,先从A读缓存,A没有读B,并且更新A缓存和B缓存;
方案3、设置缓存超时时间的时候加上一个随机的时间长度,比如这个缓存key的超时时间是固定的5分钟加上随机的2分钟,酱紫可从一定程度上避免雪崩问题;
(四)缓存并发问题
这里的并发指的是多个redis的client同时set key引起的并发问题。其实redis自身就是单线程操作,多个client并发操作,按照先到先执行的原则,先到的先执行,其余的阻塞。当然,另外的解决方案是把redis.set操作放在队列中使其串行化,必须的一个一个执行,具体的代码就不上了,当然加锁也是可以的
7、redis事务
1 什么是redis的事务?
redis事务是一些列redis命令的集合,并且有如下两个特点:
a)事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
b)事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
2、redis事务的用法
redis事务是通过MULTI,EXEC,DISCARD和WATCH四个原语实现的。
MULTI命令用于开启一个事务,它总是返回OK。
MULTI执行之后,客户端可以继续向服务器发送任意多条命令,这些命令不会立即被执行,而是被放到一个队列中,当EXEC命令被调用时,所有队列中的命令才会被执行。
另一方面,通过调用DISCARD,客户端可以清空事务队列,并放弃执行事务。
1)正常执行
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> SET key1 1
QUEUED
127.0.0.1:6379> HSET key2 field1 1
QUEUED
127.0.0.1:6379> SADD key3 1
QUEUED
127.0.0.1:6379> EXEC
1) OK
2) (integer) 1
3) (integer) 1
EXEC 命令的回复是一个数组,数组中的每个元素都是执行事务中的命令所产生的回复。 其中,回复元素的先后顺序和命令发送的先后顺序一致。
当客户端处于事务状态时,所有传入的命令都会返回一个内容为 QUEUED 的状态回复(status reply),这些被入队的命令将在 EXEC命令被调用时执行。
2)放弃事务
当执行 DISCARD 命令时,事务会被放弃,事务队列会被清空,并且客户端会从事务状态中退出:
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> SET key1 1
QUEUED
127.0.0.1:6379> DISCARD
OK
127.0.0.1:6379> EXEC
(error) ERR EXEC without MULTI
3)入队错误回滚
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set key1 1
QUEUED
127.0.0.1:6379> HSET key2 1
(error) ERR wrong number of arguments for 'hset' command
127.0.0.1:6379> SADD key3 1
QUEUED
127.0.0.1:6379> EXEC
(error) EXECABORT Transaction discarded because of previous errors.
对于入队错误,redis 2.6.5版本后,会记录这种错误,并且在执行EXEC的时候,报错并回滚事务中所有的命令,并且终止事务。
3)执行错误放过
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> HSET key1 field1 1
QUEUED
127.0.0.1:6379> HSET key2 field1 1
QUEUED
127.0.0.1:6379> EXEC
1) (error) WRONGTYPE Operation against a key holding the wrong kind of value
2) (integer) 1
当遇到执行错误时,redis放过这种错误,保证事务执行完成。
这里要注意此问题,与mysql中事务不同,在redis事务遇到执行错误的时候,不会进行回滚,而是简单的放过了,并保证其他的命令正常执行。这个区别在实现业务的时候,需要自己保证逻辑符合预期。
3、使用WATCH
WATCH 命令可以为 Redis 事务提供 check-and-set (CAS)行为。
被 WATCH 的键会被监视,并会发觉这些键是否被改动过了。 如果有至少一个被监视的键在 EXEC 执行之前被修改了, 那么整个事务都会被取消, EXEC 返回空多条批量回复(null multi-bulk reply)来表示事务已经失败。
127.0.0.1:6379> WATCH key1
OK
127.0.0.1:6379> set key1 2
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set key1 3
QUEUED
127.0.0.1:6379> set key2 3
QUEUED
127.0.0.1:6379> EXEC
(nil)
使用上面的代码, 如果在 WATCH 执行之后, EXEC 执行之前, 有其他客户端修改了 key1 的值, 那么当前客户端的事务就会失败。 程序需要做的, 就是不断重试这个操作, 直到没有发生碰撞为止。
这种形式的锁被称作乐观锁, 它是一种非常强大的锁机制。 并且因为大多数情况下, 不同的客户端会访问不同的键, 碰撞的情况一般都很少, 所以通常并不需要进行重试。
8、redis中元素排序
redis支持对list,set,sorted set元素的排序
sort 排序命令格式:
sort key [BY pattern] [LIMIT start count] [GET pattern] [ASC|DESC] [ALPHA] [STORE dstkey]
1) sort key (list)
这是最简单的情况,没有任何选项对集合自身元素排序并返回排序结果,默认为value升序。
2) [ASC|DESC] [ALPHA] (list)
sort默认的排序方式(asc)是从小到大排的,当然也可以按照逆序或者按字符顺序排。
逆序可以加上desc选项,想按字母顺序排可以加alpha选项,alpha可以和desc一起用。
sort 默认以分数(数值)排序,字母使用默认的sort排序,会报错!
3) [BY pattern] (set)
除了可以按集合元素自身值(数字,字母)排序外,还可以将集合元素内容按照给定pattern组合成新的key,并按照新key中对应的内容进行排序。
4) [GET pattern]
上面的例子都是返回的mimvp集合中的数值元素,也可以通过get选项去获取指定pattern作为新key(mimvp_*)对应的字符串值。
5) [LIMIT start count] (limit)
上面例子返回结果都是全部元素,limit选项可以限定返回结果的数量。
start下标是从 0 开始,这里的limit选项(limit 1 2)意思是从第二个元素开始获取2个。
…………..
9、Redis是否要设置内存大小限制?
两个问题:
1、如何确认redis占用多大内存了?
2、是否要设置redis内存限制
>>1、Redis的INFO – Redis命令可以查看当前内存使用情况
2、实际生产环境中,需要配置maxmemory,一般不超过机器的最大内存。radis是基于内存的,需要提前做好内存容量规划,防止out of max memory,通常实际内存达到最大内存的3/4时就要考虑加大内存或者拆分数据。
这个涉及到容量规划和运维管理两方面
1. 如果你运行redis的服务器内存在你可以预见的业务增长空间可以存放所有业务数据,理论上不设置也无妨。若无法保证,那么不设置maxmemory的限制,很有可能会导致redis-server 在运行一段时间后oom
2. 实际运营过程中, 一个redis实例数据太大其实是不方便管理的,也不太安全的。比如,做个全备的时间可能不短,一个实例挂了, 在切换到备机之前,所有用户都会受到影响。 一般采用多实例,数据分片的架构会比较好点。
针对可以设定内存大小的,设置最大内存,同时可以开启lru机制,考虑关闭dump备份,启用aof备份机制针对不可以设定最大内存大小的,往往这类场景数据也是不可以丢失的,那么可以考虑做切片,引入codis、redis-cluster等方案解决单机内存瓶颈问题。
10、radis与mencache的区别
redis和memecache的不同在于:
1、存储方式:
memecache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小
redis有部份存在硬盘上,这样能保证数据的持久性。
2、数据支持类型:
redis在数据支持上要比memecache多的多。
3、使用底层模型不同:
新版本的redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
4、运行环境不同:
Redis目前官方只支持Linux 上去行,从而省去了对于其它系统的支持,这样的话可以更好的把精力用于本系统 环境上的优化,虽然后来微软有一个小组为其写了补丁。但是没有放到主干上
11、redis数据结构zset的内部实现
Redis对象由redisObject结构体表示。
typedef struct redisObject {
unsigned type:4; // 对象的类型,包括 /* Object types */ unsigned encoding:4; // 底部为了节省空间,一种type的数据,可以采用不同的存储方式 unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; // 引用计数 void *ptr;} robj;Redis目前使用的编码方式:
#define OBJ_ENCODING_RAW /* Raw representation */ 简单动态字符串
#define OBJ_ENCODING_INT /* Encoded as integer */ 整数
#define OBJ_ENCODING_HT /* Encoded as hash table */ 字典
#define OBJ_ENCODING_ZIPLIST /* Encoded as ziplist */ 压缩列表
#define OBJ_ENCODING_INTSET /* Encoded as intset */ 整数集合
#define OBJ_ENCODING_SKIPLIST /* Encoded as skiplist */ 跳跃表
#define OBJ_ENCODING_EMBSTR /* Embedded sds string encoding */ embstr编码的简单动态字符串
#define OBJ_ENCODING_QUICKLIST /* Encoded as linked list of ziplists */
本质上,Redis就是基于这些数据结构而构造出一个对象存储系统。redisObject结构体有个ptr指针,指向对象的底层实现数据结构,encoding属性记录对象所使用的编码,即该对象使用什么数据结构作为底层实现。
有序集合对象的编码可以是ziplist或者skiplist