Hbase简介
访问Hbase主要有三种方式
- 通过单个row key访问
- 通过row key的range
- 全表扫描
存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分利用排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
- 字典序对int排序的结果是1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。
- 要保持整形的自然序,行键必须用0作左填充。
列族
访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上的控制权限能帮助我们管理不同类型的应用:
- 我们允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、一些应用则只允许浏览数据(甚至可能因为隐私的原因不能浏览所有数据)。
时间戳和cell
- 通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引
- 时间戳也可以由客户显式赋值。
物理存储
- 当table中的行不断增多,就会有越来越多的Hregion(对应一个region)。
- Hregion是Hbase中分布式存储和负载均衡的最小单元。最小单元就表示不同的Hregion可以分布在不同的HRegion server上。但一个Hregion是不会拆分到多个server上的。
存储模型
- 一个table中的region会被随机分配给一个region server。
- region是分布式存储和负载均衡的最小单元。
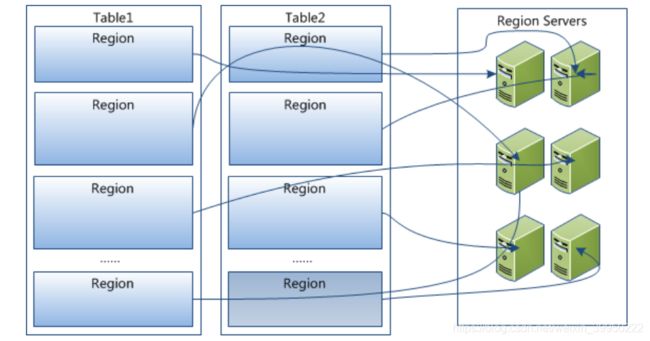
HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元。
- HRegion由一个或者多个Store组成,每个store保存一个columns family。
- 每个Strore又由一个memStore和0至多个StoreFile组成。如图:
- StoreFile以HFile格式保存在HDFS上。

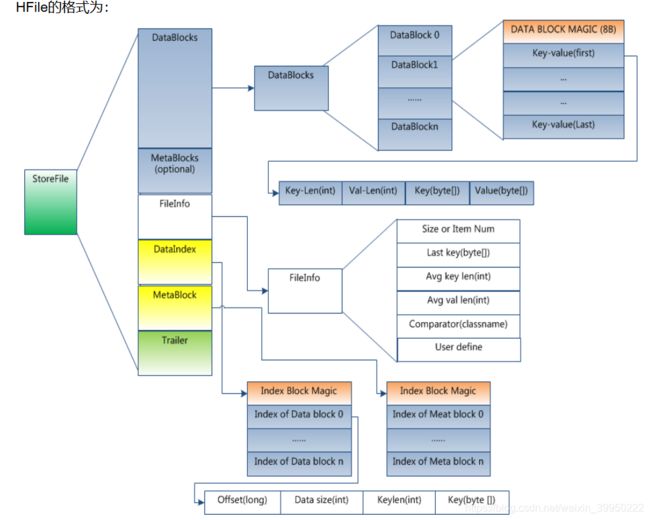
- 基于block的存储结构
- block的索引驻留内存
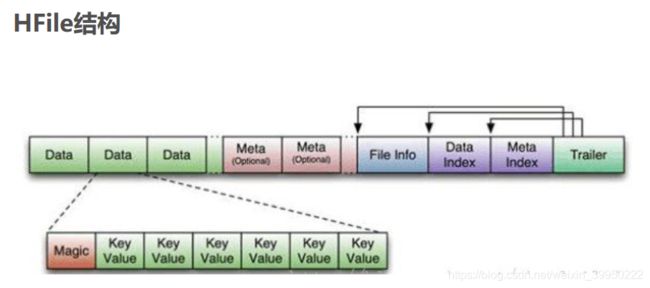
HFile分为六个部分:
- Data Block 段–--保存表中的数据,这部分可以被压缩
- Meta Block 段 (可选的)--–保存用户自定义的kv对,可以被压缩。
- File Info 段--–Hfile的元信息,不被压缩,用户也可以在这一部分添加自己的元信息。
- Data Block Index 段–--Data Block的索引。每条索引的key是被索引的block的第一条记录的key。
- Meta Block Index段 (可选的)--–Meta Block的索引。
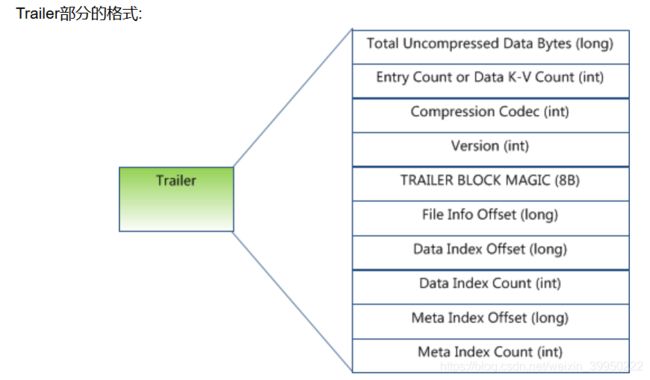
- Trailer–--这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个 block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。
HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。
Hlog(WAL log)
WAL机制
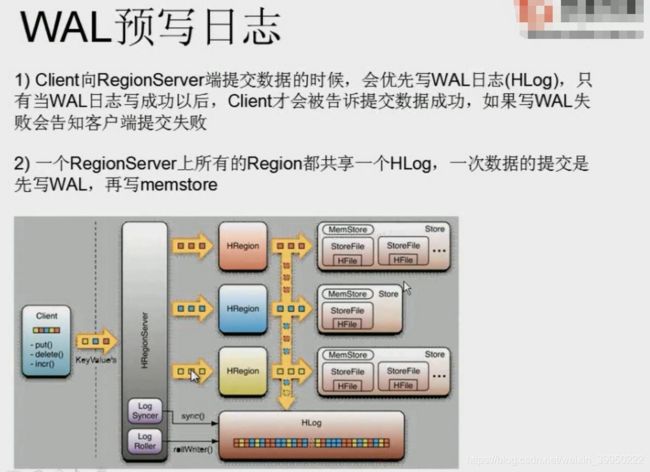
WAL 意为Write ahead log,Hlog记录数据的所有变更,一旦数据修改,就可以从Hlog中进行恢复。
每个Region Server维护一个Hlog,而不是每个Region一个(region server中会存在不同table中的region)。
这样不同region(来自不同table)的日志会混在一起
- 这样做的目的是不断追加单个文件相对于同时写多个文件而言,可以减少磁盘寻址次数,因此可以提高对table的写性能。????不理解
- 带来的麻烦是,如果一台region server下线,为了恢复其上的region,需要将region server上的Hlog进行拆分,然后分发到其它region server上进行恢复。
HLog文件
- 就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLog Key中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是”写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue。
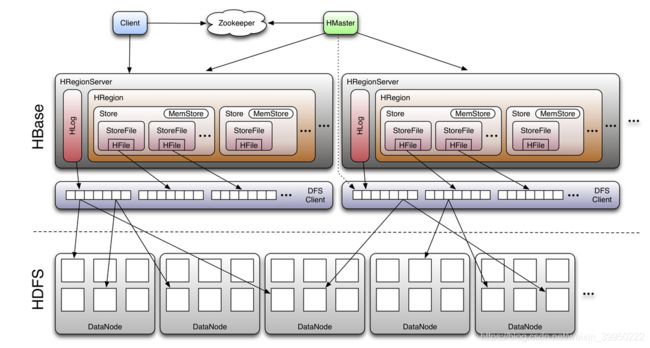
系统架构

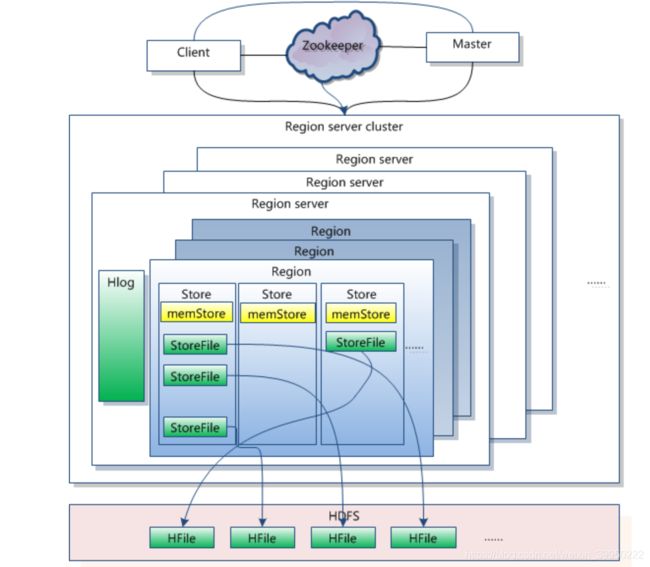
Client
- 包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如region的位置信息。
Zookeeper
- 保证任何时候,集群中只有一个master,(主备切换master,HA机制)
- 存储所有Region的寻址入口。root表--->meta表---->找到table中每个region对应的信息
- 实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
- 存储Hbase的schema和table元素据。?????????
Master
- 为Region server分配region
- 负责region server的负载均衡
- 发现失效的region server并重新分配其上的region
- 处理schema更新请求????管理用户对表的增删改查操作?????
Region Server
- Region server维护Master分配给它的region,处理对这些region的IO请求
- Region server负责切分在运行过程中变得过大的region(切分region)
可以看到,client访问hbase上数据的过程并不需要master参与,寻址访问zookeeper(寻址入口root表)和region server(meta表也在上面),数据读写访问region server,master仅仅维护着table和region的元数据信息,负载很低。
region定位
如何找到某个row key所有在region
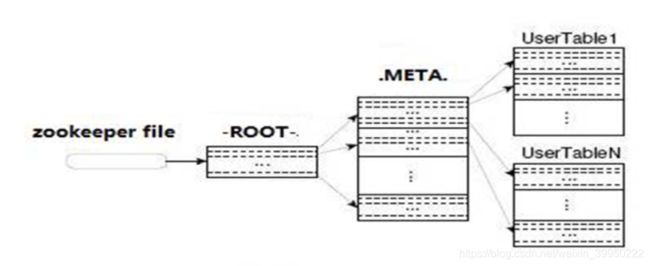
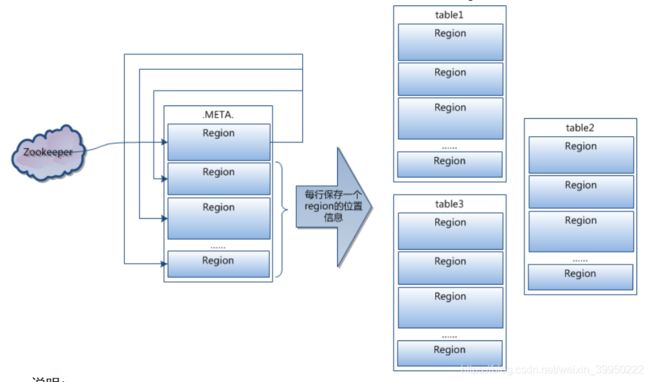
- root region永远不会被split,保证了最少需要三次跳转,就能定位到任意region 。(root每个row key保存了meta表中的一个region,meta表中region也是保存在region server中)
- META.表每行保存一个region的位置信息,row key 采用表名+表的最后一样编码而成。
- 为了加快访问,.META.表的全部region都保存在内存中。
- 假设,root表、META.表的一行在内存中大约占用1KB。并且每个region限制为128MB。
- 那么上面的三层结构可以保存的region数目为:
- (128MB/1KB) * (128MB/1KB) = = 2(34)个region
client会将查询过的位置信息保存缓存起来,缓存不会主动失效,因此如果client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的region(其中三次用来发现缓存失效,另外三次用来获取位置信息)。????????不懂为什么发现缓存失效需要三次???不是已经缓存知道了table中region的位置,直接访问就行了,不就是一次网络嘛???
HBase操作
1、flush
- 内存容量有限,需要定期将内存中的数据flush到磁盘,每次flush,每个region的每个column family都会产生一个HFile读取操作,region server会把多个HFile数据归并到一起。
2、compaction
- flush操作产生的HFile会越来越多,需要归并来减少HFile的数量,旧数据会被清理(更新数据)。
3、split
- HFile大小增长到某个阈值就会Split,同时把Region Split成两个region ,这两个region被分发到其他不同的region server上。
读写过程
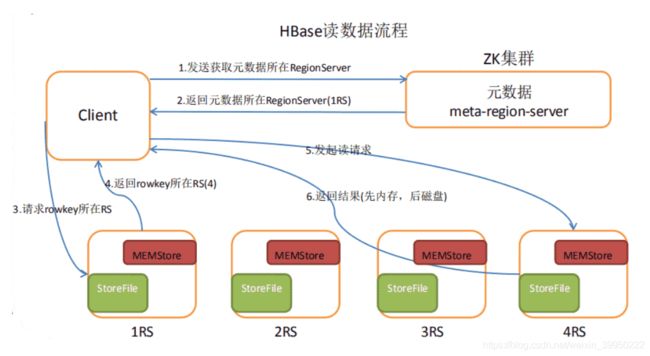
hbase使用MemStore和StoreFile存储对表的更新。
数据在更新时首先写入Log(WAL log)和内存(MemStore)中
MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。(于此同时,系统会在zookeeper中 记录一个redo point,表示这个时刻之前的变更已经持久化了。(minor compact))
- 当系统出现意外时,可能导致内存(MemStore)中的数据丢失,此时使用Log(WAL log)来恢复checkpoint之后的数据。
前面提到过StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。
- 当一个Store中的StoreFile数量达到一定的阈值后,就会进行一次合并(major compact),将对同一个key的修改合并到一起,形成一个大的StoreFile,触发compact之后,StoreFile越来越大,当StoreFile的大小达到一定阈值后,会将region等分成两个region。
- 在compact的时候进行数据的更新和删除,因此hbase只有增加数据,所有的删除和更新都是在compact中完成,使得用户的写操作只需要写入内存memstore就可以,提高hbase 的IO性能。
由于对表的更新是不断追加的,处理读请求时需要访问Store中全部的, StoreFile和MemStore,将他们的按照row key进行合并,由于StoreFile和MemStore都是经过排序的,并且StoreFile带有内存中索引,合并的过程还是比较快。
写请求处理过程
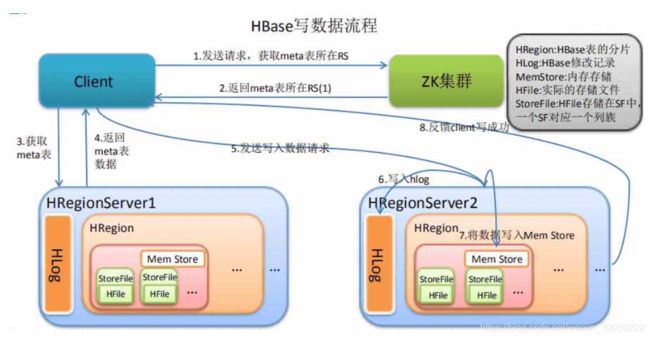
- client向region server提交写请求
- region server找到目标region
- region检查数据是否与schema一致
- 如果客户端没有指定版本,则获取当前系统时间作为数据版本
- 将更新写入WAL log(Hlog)
- 将更新写入Memstore
- 判断Memstore的是否需要flush为Store文件。
blockCache
一个regionserver上有一个BlockCache和N个memStore
blockcache包含三个级别的优先级队列:
- single:一个block被第一次访问,则放在这一级队列中
- multi:一个block被多次访问,从single队列移到该队列
- in memory:静态指定的(在column family上设置),不会像其他两种缓存因为cache而发生改变
- 一个block被访问的次数再多也不会放到in memory中。
- in memory上的block不管是第一次访问,都是在in memory中
blockcache实现的机制是分级缓存
- 避免缓存之间的相互影响,淘汰策略采用LRU算法,首先淘汰single,然后multi,最后是in memory。
regionserver上内存一部分用作blockcache,主要用作读,另一部分用作memstore,主要用于写(flush)。
- 读请求先去memstore中查数据,查不到就去blockcache中找,在找不到就去磁盘上读,并把读的结果放入blockcache,blockcache达到上限(headsize*hfile.block.cache.size*0.85)后,会启动淘汰机制(LRU算法),淘汰掉最老的一批数据
写入memstore的同时,会先写入Hlog中,避免当regionserver发生故障时memstore中未flush到storeFile的数据。
region分配
一个region只能分配给一个region server。
- master记录了当前有哪些可用的region server。以及当前哪些region分配给了哪些region server,哪些region还没有分配。当存在未分配的region,并且有一个region server上有可用空间时,master就给这个region server发送一个装载请求,把region分配给这个region server。region server得到请求后,就开始对此region提供服务。
region server上线
master使用zookeeper来跟踪region server状态。
- 当某个region server启动时,会首先在zookeeper上的server目录下建立代表自己的文件,并获得该文件的独占锁。
- 由于master订阅了zookeeper上server 目录上的变更消息,当server目录下的文件出现新增或删除操作时,master可以得到来自zookeeper的实时通知。因此一旦region server上线,master能马上得到消息。
region server下线
- 当region server下线时,它和zookeeper的会话断开,zookeeper会自动释放代表这台region server的文件上的独占锁。
- 而master不断轮询 server目录下文件的锁状态。如果master发现某个region server丢失了它自己的独占锁,(或者master连续几次和region server通信都无法成功)
- master就是尝试去获取代表这个region server的读写锁,一旦获取成功
就可以确定:
- region server和zookeeper之间的网络断开了。
- region server挂了。
的其中一种情况发生了,无论哪种情况,region server都无法继续为它的region提供服务了
- 此时master会删除zookeeper server目录下代表这台region server的文件,并将这台region server上的region分配给其它还活着的region server。
如果网络短暂出现问题导致region server丢失了它的锁,那么region server重新连接到zookeeper之后,只要代表它的文件还在,它就会不断尝试获取这个文件上的锁,一旦获取到了,就可以继续提供服务。
master上线
master启动进行以下步骤:
- 从zookeeper上获取唯一 一个代码master的锁,用来阻止其它master成为master。
- 扫描zookeeper上的server目录,获得当前可用的region server列表。
- 和2中的每个region server通信,获得当前已分配的region和region server的对应关系。
- 扫描.META.region的集合,计算得到当前还未分配的region,将他们放入待分配region列表。
master下线
由于master只维护表和region的元数据
- 而不参与表数据IO的过程,master下线仅导致所有元数据的修改被冻结,无法创建或删除表,无法修改表的schema,无法进行region的负载均衡,无法处理region上下线,无法进行region的合并(???什么合并,某一个region server故障,分配上面的region???)
- 唯一例外的是region的split可以正常进行,因为只有region server参与,表的数据读写还可以正常进行。
因此master下线短时间内对整个hbase集群没有影响。从上线过程可以看到
- master保存的信息全是可以冗余信息(都可以从系统其它地方收集到或者计算出来)
因此,一般hbase集群中总是有一个master在提供服务,还有一个以上 的’master’在等待时机抢占它的位置。
https://blog.csdn.net/scgaliguodong123_/article/details/46531547
八天hadoop第六天