大数据和云计算技术周报(第155期)
导语
“大数据” 三个字其实是个marketing语言,从技术角度看,包含范围很广,计算、存储、网络都涉及,知识点广、学习难度高。
本期会给大家奉献上精彩的:Doris、分布式、大数据、Hbase、spark、hive、MongoDB、GC。全是干货,希望大家喜欢!!!
1HBase
本文主要介绍HBase及HBase on S3的架构,通过了解HBase的读写流程,阐述HBase on S3的最佳实践及典型应用场景。
https://mp.weixin.qq.com/s/VcILkRQGLf3UwSJJc9WGsA
2Spark
阿里巴巴高级技术专家李呈祥为大家带来Apache Spark 3.0中的SQL性能改进概览的介绍。以下由Spark+AI Summit中文精华版峰会的精彩内容整理。
https://mp.weixin.qq.com/s/yvQJopUT-9ezS2-53K3lTw
3Doris
本文侧重于以Doris引擎为“发动机”的数仓生产架构的改进与思考。
https://mp.weixin.qq.com/s/8XY2RfP9xjJ23dBNsXiSow
4分布式
两种原子提交算法:两阶段提交和三阶段提交。这两种算法的最大优点是易于理解和实现,但也有一些缺点。在2PC中,协调者(或至少是它的代替者)必须在整个提交过程中都存活,这会大大降低可用性。3PC在一些情况下取消了这个要求,但在网络分区的情况下可能发生脑裂。
https://mp.weixin.qq.com/s/xhcOp07GpKQF9YXYW7EijA
5Hive
本文将基于 SparkSQL(2.4.4) + Hive (2.3.6), 介绍物化视图在SparkSQL中的实现及应用。
https://mp.weixin.qq.com/s/ubYGmTPy2VE-udHKscf--w
6Spark
Spark通过DataSource和DataFrame API访问Iceberg table,或者进行Catalog相关的操作。由于Spark Data Source V2 API还在持续的演进和修改中,所以Iceberg在不同的Spark版本中的使用方式有所不同。
www.iteblog.com/archives/9824.html

7大数据
过往记忆大数据精选300篇,涵盖各大厂企业应用实践和各大数据组件神技传送。
https://mp.weixin.qq.com/s/g5ujDfBgD7ClNYv7L0RbHQ
8MongoDB
本文讲述了了解MongoDB WiredTiger存储引擎在磁盘上生成的文件及其内容有助于更好的实现数据迁移、备份与恢复、数据修复等工作,并说明WiredTiger存储引擎生成文件的格式及相关元数据文件,以及WiredTiger的wt工具编译过程。
https://mongoing.com/archives/74064

9AL
机器学习专家和行业人士最喜欢读哪些机器学习书籍呢?最近,有人咨询了十多位机器学习研究者,包括斯坦福毕业生、谷歌大脑前员工 Denny Britz,维基媒体基金会机器学习负责人、《Machine Learning with Python Cookbook》作者 Chris Albon,老照片修复神器 DeOldify 的创造者 Jason Antic 等等
https://mp.weixin.qq.com/s/yNTvu_V_uNY25rO42kEUDQ
10GC
从设计目标来看,我们知道ZGC适用于大内存低延迟服务的内存管理和回收。本文主要介绍ZGC在低延时场景中的应用和卓越表现,文章内容主要分为四部分:
1.GC之痛:介绍实际业务中遇到的GC痛点,并分析CMS收集器和G1收集器停顿时间瓶颈;
2.ZGC原理:分析ZGC停顿时间比G1或CMS更短的本质原因,以及背后的技术原理;
3.ZGC调优实践:重点分享对ZGC调优的理解,并分析若干个实际调优案例;
4.升级ZGC效果:展示在生产环境应用ZGC取得的效果
https://tech.meituan.com/2020/08/06/new-zgc-practice-in-meituan.html

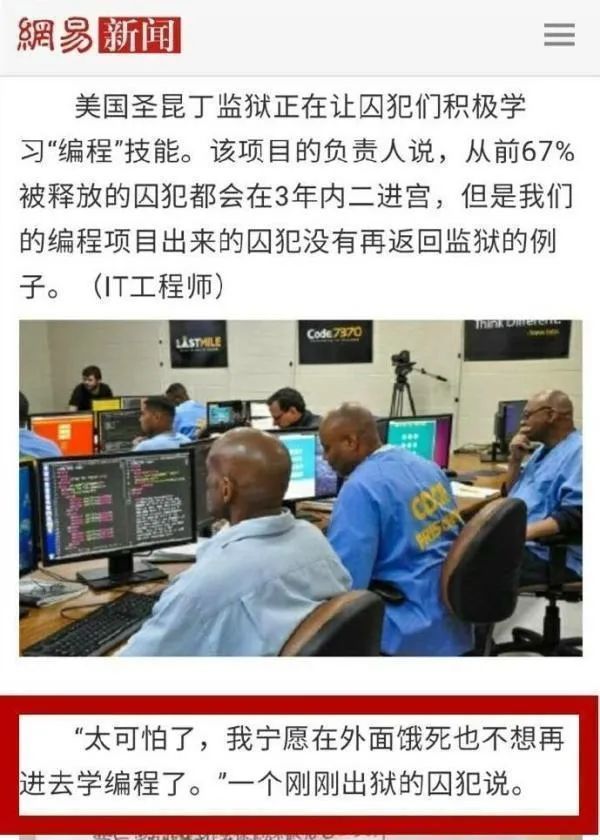
11开心一刻
致谢:
周蓬勃、王在道、孙亚飞、冯艺帆、陈少军、邓开表、张少华、薛述强、刘彬、刘超、廖程鹏、董言、吕西金、朱洁、蓝随、黄文辉、郭飞
猜你喜欢
#大数据和云计算机技术社区#博客精选(2017)
NoSQL 还是 SQL ?这一篇讲清楚
阿里的OceanBase解密
#大数据和云计算技术#: "四有"社区介绍
大数据和云计算技术周报(第56期)
新数仓系列:Hbase周边生态梳理(1)
《大数据架构详解》第2次修订说明
简单梳理跨数据中心数据库
云观察系列:漫谈运营商公有云发展史
云观察系列:百度云的一波三折
云观察系列:阿里云战略观察
超融合方案分析系列(7)思科超融合方案分析
加入技术讨论群
《大数据和云计算技术》社区群人数已经6000+,欢迎大家加下面助手微信,拉大家进群,自由交流。

喜欢QQ群的,可以扫描下面二维码:

欢迎大家通过二维码打赏支持技术社区(英雄请留名,社区感谢您,打赏次数超过108+):
