HBase之HFile详解
HFile是HBase存储数据的文件组织形式。HFile经历了三个版本,其中V2在0.92引入,V3在0.98引入。HFileV1版本的在实际使用过程中发现它占用内存多,HFile V2版本针对此进行了优化,HFile V3版本基本和V2版本相同,只是在cell层面添加了Tag数组的支持。

一 HFile 文件结构
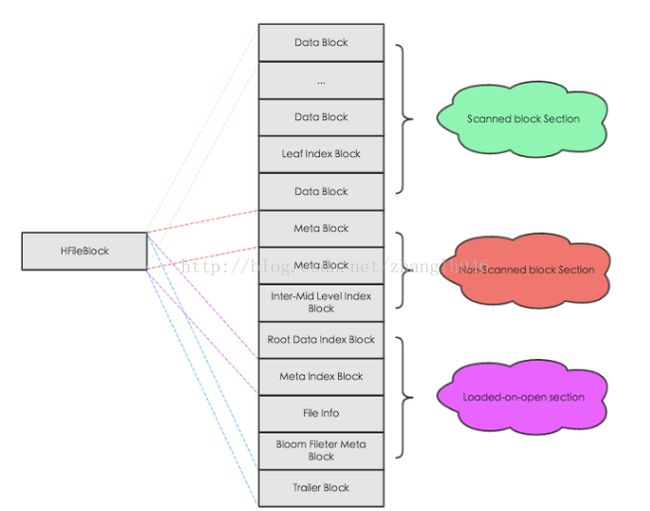
从以上图片可以看出HFile主要分为四个部分:
Scanned Block Section: 顺序扫描HFile,这个section的所有数据块都被读取,包括Leaf Index Block 和 Bloom Block
Non-Scanned Block Section: 顺序扫描HFile,这个section的数据不会被读取,主要包括元数据数据块等
Load-On-Open-Section: 这部分数据在HRegionServer启动时候,实例化HRegion并创建HStore的时候会将所有HFile的Load-On-Open-Section里的数据加载进内存,主要存放了Root Data Index, Meta Index,FileInfo以及BloomFilter的元数据等
Trailer: 这部分主要记录HFile的一些基本信息,各个部分的偏移量和寻址信息
从物理角度看,如图示:
二 HFileBlock
HFile会被切分为多个大小相等的block,每一个block大小可以在创建表列簇的时候通过blockSize参数指定,默认是64K,较大的blockSize有利于scan,较小的有利于随即查询(get)。
所有的block都有相同的数据结构,HBase将block块抽象成HFile
Block。HFileBlock支持2种类型:一种类型不支持checksum,一种不支持。我们选用不支持checksum的HFileBlock解释,下面是HFile
Block的内部结构:
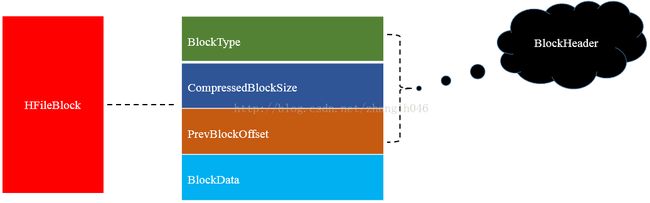
从上图可知,HFileBlock主要分为2个部分: Block Header 和 Block Dada. 其中Block Header 用来存储元数据,包括block 类型,压缩block大小,上一个block的偏移量等; 而Block Data主要存储具体的数据。
Block Type: 主要用来记录该Block的类型,HBase总共有8种Block
Type, 每一种block type对应的block都存储不同的数据内容,有的存储用户数据,有的存储索引数据,有的存储meta元数据。对于任意一种类型的HFileBlock,都有着相同结构的Block Header,但是 Block Data结构可能去不相同,以下是简单的Block Type介绍:
2.1 Trailer Block
主要记录了HFile的基本信息以及各个部分的偏移量等

HFile在读取数据的时候,首先会解析Trailer Block,并加载到内存,然后再进一步加载Load-On-Open section的数据,具体步骤如下:
2.1.1 首先加载HFile版本信息: HBase中version包含major version和minor version两部分,前者决定了HFile的主版本v1,v2 or v3,后者决定了在主版本的基础上是否支持一些微小的修正,比如是否支持checkum等。
2.1.2 根据HFile版本信息,获取trailer的长度,因为版本的trailer长度或许不一样,然后再根据trailer长度加载整个HFile Trailer Block
2.1.3 加载Load-On-Open section到内存,起始偏移量是trailer中记录的LoadOnOpenDataOffset,结束位置是HFile的length – trailer的length
2.2 Data Block
Data Block是HBase中数据存储的最小单元,它存储的是用户KeyValue数据,数据结构如图所示:
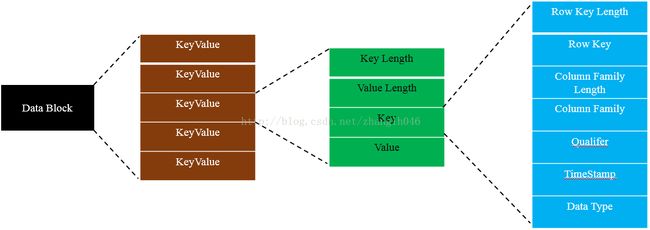
KeyValue: 是由四部分组成的
2.2.1 Key Length: 存储key的长度,本身是4个字节
2.2.2 Value Length: 存储value的长度,本身是4个字节
2.2.3 Key: 存储数据的key,由Row Key Length+Row Key+Column Family Length +Column Family+Column Qualifier + TimeStamp+Key Type
2.2.3.1 Row Key Length: 存储row key的长度,总共2字节
2.2.3.2 Row : 存储row的实际内容,其大小为row key length
2.2.3.3 Column Family Length:存储列簇 Column Family的长度,占1字节
2.2.3.4 Column Family:存储Column Family实际内容,大小为Column Family Length;
2.2.3.5 Column Qualifier:存储Column Qualifier对应的数据,既然key中其他所有字段的大小都知道了,整个key的大小也知道了,那么这个Column Qualifier大小也是明确的了,无需再存储其length
2.2.3.6 Time Stamp:存储时间戳Time Stamp,占8字节
2.2.3.7 Key Type:存储Key类型Key Type,占1字节,Type分为Put、Delete、DeleteColumn、DeleteFamilyVersion、DeleteFamily等类型,标记这个KeyValue的类型
KEY基础设施大小(存储各个部分长度的大小):
KEY_INFRASTRUCTURE_SIZE = ROW_LENGTH_SIZE + FAMILY_
LENGTH_SIZE + TIMESTAMP_SIZE + TYPE_SIZE;
也就是:存储 row key的长度的大小 + 存储 column family 的长度的大小 + 存储timestamp长度的大小 + 存储key type长度的大小 = 2 + 1 + 8 + 1 = 12字节
KEY数据结构大小 = KEY_INFRASTRUCTURE_SIZE + ROW KEY LENGTH + COLUMN FAMILY LENGTH + COLUMNQUALIFIER LENGTH + TIMESTAMP LENGTH + KEY TYPE LENGTH
也就是:KEY基础设施大小 + ROW KEY数据长度 + COLUMN FAMILY 数据长度 + COLUMN QUALIFEIR 数据长度 + 时间戳长度 + KEY TYPE数据长度
2.2.4 Value 存储单元格CELL实际对应的值
2.3 BloomFilter Meta Block & Bloom Block
BloomFilter对于HBase随机读的性能至关重要,他可以避免读取一些不会用到HFile,减少实际的IO次数,提高随机读的性能。
它的原理就是通过位数组来实现过滤,初始状态每一位都是0

然后BloomFilter对一个集合使用k个独立的hash函数,分别将集合中的每一个元素进行映射到{1,m}的范围。对于任何一个元素,然后根据映射的数字到位数组确定位置,然后在该位置被置为1
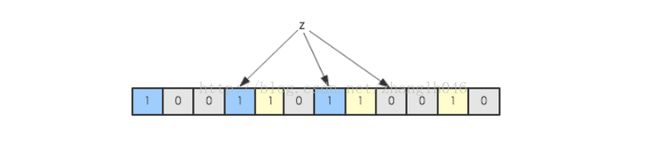
下图中集合S只有两个元素x和y,分别被3个hash函数进行映射,映射到的位置分别为(0,2,6)和(4,7,10),对应的位会被置为1:

现在假如要判断另一个元素是否是在此集合中,只需要被这3个hash函数进行映射,查看对应的位置是否有0存在,如果有的话,表示此元素肯定不存在于这个集合,否则有可能存在。下图所示就表示z肯定不在集合{x,y}中:
HBase中每个HFile都有对应的位数组,KeyValue在写入HFile时会先经过几个hash函数的映射,映射后将对应的数组位改为1,get请求进来之后再进行hash映射,如果在对应数组位上存在0,说明该get请求查询的数据不在该HFile中。
HFile中的位数组就是Bloom Block存储的值,可以想象,一个HFile文件越大,里面存储的KeyValue就越多,位数组也就会越大。一旦太大就不适合直接加载到内存,因此HFile V2在设计上将位数组进行了拆分,拆分成多个独立的数组(根据key进行拆分,一部分连续的key使用一个位数组),这样一个HFile就会包含多个位数组,根据key进行查询,首先会定位到具体的某一个位数组,只需要加载此位数组到内存即可
在结构上,每一个位数组对应HFile一个Bloom Block,为了方便根据key定位具体需要加载哪个位数组,HFile V2又设计了对应的索引
Bloom Index Block,对应的内存和逻辑结构如下:

2.3.1 TotalByteSize: 表示位数组大小
2.3.2 NumChunks: 表示Bloom Block个数
2.3.3 HashCount: 表示hash函数个数、
2.3.4 HashType: 表示hash函数类型
2.3.5 TotalKeyCount: 表示Bloom Filter已经包含的key数据
2.3.6 TotalMaxKeys: 表示Bloom Filter 当前包含最多的key的数目
Bloom Index Entry:
BlockOffset: 表示对应的Bloom Block在HFile中偏移量
FirstKey: 表示BloomBlock中第一个Key
根据上文所说,一次get请求进来,首先会根据key在所有的索引条目中进行二分查找,查找到对应的Bloom Index Entry,就可以定位到该key对应的位数组,加载到内存进行过滤判断。