SQL优化常用技巧--数据类型优化|索引优化|查询优化
mysql架构图
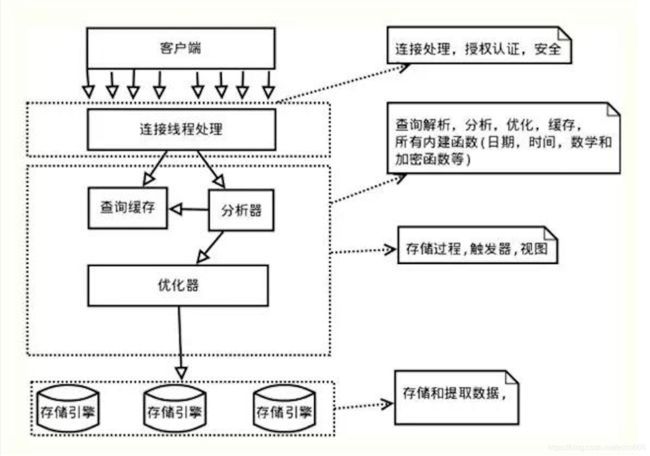
注意:根据存储引擎的不同,以下的优化方法不一定全部适用。一般情况是适用的。
一、数据类型优化
- 更小的通常更好。一般情况下,应该尽量使用可以正确存储数据的最小数据类型。更小的数据类型通常更快,因为它们占用更少的磁盘、内存和CPU缓存,处理时需要的CPU周期也更少。(但是要确保没有低估需要存储的值的范围,因为在schema中多个地方增加数据类型的范围是一个非常耗时和痛苦的操作)
- 使用varchar(5)和varchar(200)存储‘hello’的空间开销是一样的。但是更长的列会消耗更多的内存,因为mysql通常会分配固定大小的内存来保存内部值。
- 简单就好。简单数据类型的操作通常需要更少的CPU周期。例如:
- 整型比字符操作代价更低;
- 使用mysql内建的类型而不是字符串来存储日期和时间;
- 用整形存储IP地址。
- 尽量避免NULL。除非真实数据模型中有确切的需要,否则应该尽可能的避免使用NULL值。很多表都包含为NULL的列,因为可为NULL是列的默认属性,通常情况下最好指定列为NOT NULL.
- 当可为NULL的列被索引时,每个索引记录需要一个额外的字节,在MYISAM里甚至还可能导致固定大小的索引变成可变大小的索引。
- 如果计划在列上建索引,就应该尽量避免设计成可为NULL的列。
二、索引优化
参考博客
索引优化应该是对查询性能优化最有效的手段了。 --《高性能mysql》
1、索引设计的原则:
-
适合索引的列是出现在where子句中的列,或者连接子句中指定的列;
-
基数`较小的类,索引效果较差,没有必要在此列建立索引;
-
使用短索引。如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间;
-
不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进行更新甚至重构,索引列越多,这个时间就会越长。所以只保持需要的索引有利于查询即可。

desc tb_emp;

基数:单个列唯一键(distict_keys)的数量叫做基数。如下图所示,姓名的基数就是员工人数,职位基数小于员工人数。
select count(distinct ename),count(distinct job) from `tb_emp`;

2、索引优化规则:
show status like 'handler_read%';
show index from tb_emp;

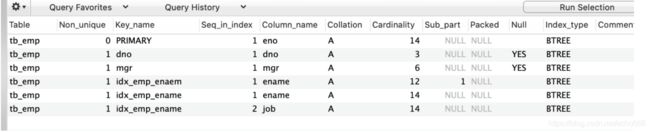
说明:
Handler_read_key:如果索引正在工作,Handler_read_key的值将很高。
Handler_read_rnd_next:数据文件中读取下一行的请求数,如果正在进行大量的表扫描,值将较高,则说明索引利用不理想。
- 如果MySQL估计使用索引比全表扫描还慢,则不会使用索引。
- 前导模糊查询不能命中索引。
like '%字段%'
explain select * from tb_emp where ename like '%莫%';

explain select * from tb_emp where ename like '李莫%';

说明:
1. type列,连接类型。一个好的sql语句至少要达到range级别。杜绝出现all级别
2. key列,使用到的索引名。如果没有选择索引,值是NULL。可以采取强制索引方式
3. key_len列,索引长度
4. rows列,扫描行数。该值是个预估值
5. extra列,详细说明。注意常见的不太友好的值有:Using filesort, Using temporary
- 复合索引的情况下,查询条件不包含索引列最左边部分(不满足最左原则),不会命中符合索引。
alter table tb_emp add index index_mul(ename,job,sal) ;
explain select * from tb_emp where ename ='李莫愁' and sal = 3500;

explain select * from tb_emp where job ='设计师' and sal = 3500;

-
union、in、or都能够命中索引,建议使用in(查询的CPU消耗:or>in>union。
-
用or分割开的条件,如果or前的条件中列有索引,而后面的列中没有索引,那么涉及到的索引都不会被用到。
explain select * from tb_emp where eno = 3088 or sal =3500;

因为or后面的条件列中没有索引,那么后面的查询肯定要走全表扫描,在 存在全表扫描的情况下,就没有必要多一次索引扫描增加IO访问。
- 负向条件查询不能使用索引,可以优化为in查询。
负向条件有:!=、<>、not in、not exists、not like等。
explain select * from tb_emp where ename != '李莫愁';

-
范围条件查询可以命中索引。范围条件有:<、<=、>、>=、between等。
-
如果是范围查询和等值查询同时存在,优先匹配等值查询列的索引:
explain select * from tb_emp where sal > 4000 and mgr > 4000;

explain select * from tb_emp where sal > 4000 and mgr = 5566;

- 数据库执行计算不会命中索引。
explain select * from tb_emp where sal > 4000;

explain select * from tb_emp where sal+1 > 4000;

计算逻辑应该尽量放到业务层处理,节省数据库的CPU的同时最大限度的命中索引。
3、创建索引的注意事项:
- 更新十分频繁的字段上不宜建立索引:因为更新操作会变更B+树,重建索引。这个过程是十分消耗数据库性能的。
- 区分度不大的字段上不宜建立索引:类似于性别这种区分度不大的字段,建立索引的意义不大。因为不能有效过滤数据,性能和全表扫描相当。另外返回数据的比例在30%以外的情况下,优化器不会选择使用索引。
- 业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。虽然唯一索引会影响insert速度,但是对于查询的速度提升是非常明显的。另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,在并发的情况下,依然有脏数据产生。
- 多表关联时,要保证关联字段上一定有索引。
- 创建索引时避免以下错误观念:索引越多越好,认为一个查询就需要建一个索引;宁缺勿滥,认为索引会消耗空间、严重拖慢更新和新增速度;抵制唯一索引,认为业务的唯一性一律需要在应用层通过“先查后插”方式解决;过早优化,在不了解系统的情况下就开始优化。
三、查询性能优化
-
查询性能低下最基本的原因是访问的数据太多。
-
是否向数据库请求了不需要的数据
-
在查询结果后面加上limit。
-
多表关联时返回全部的列
select * from tb_emp inner join tb_dept on tb_emp.dno=tb_dept.dno where tb_dept.dno=20; select tb_emp.* from tb_emp inner join tb_dept on tb_emp.dno=tb_dept.dno where tb_dept.dno=20; -
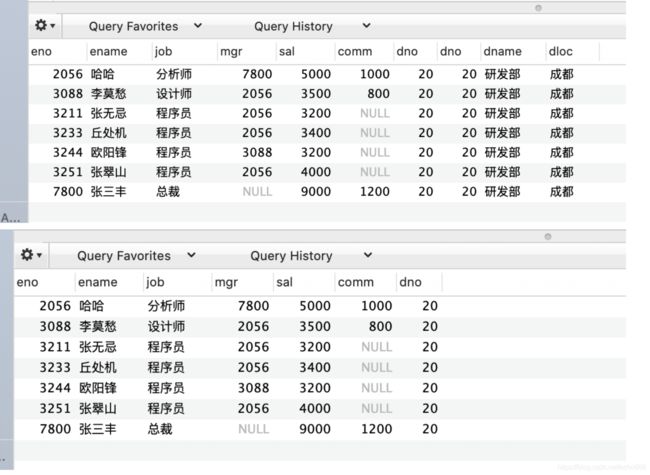
注意:总是取出全部的列。取出全部的列会让优化器无法完成索引覆盖扫描这类优化,还会为服务器带来额外的I/O、内存和CPU的消耗。因此,一些DBA是严格禁止select *的写法的。-
mysql是否在扫描额外的记录.如果查询需要扫描大量的数据但只返回少数的行,那么可以试试如下方法:
- 重写这个复杂查询
- 使用索引覆盖扫描
- 改变库表结构
-
-
重构查询的方式
-
一个复杂查询还是多个简单查询
-
切分查询,一次删除一万行数据一般来说是一个比较高效而且对服务器影响也最小的做法。
delete from messages where created < date_sub(now(),interval 3 month); rows_affected = 0 do { rows_affected = do_query( "delete from messages where created < date_sub(now(),interval 3 month) limit 10000)" }while rows_affected > 0- 分解关联查询(优点)
-
让缓存效率更高
-
将查询分解后,执行单个查询可以减少锁的竞争
-
在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展;
-
减少冗余记录的查询
-
相当于在应用中实现了哈希关联
-
select * from tag join tag_post on tag_post.tag_id=tag.id join post on tag_post.post_id=post.id where tag.tag='mysql'; select * from tag where tag='mysql'; select * from tag_post where tag_id=1234; select * from post where post.id in(123,456,9098,8904); -