汽车之家各种车型参数爬虫
汽车之家各种车型参数爬虫
结果如下:
本案例使用jupyter notebook,用到requests,BeautifulSoup,lxml,urlencode ,pandas五个库,爬取下来的数据如下图所示:
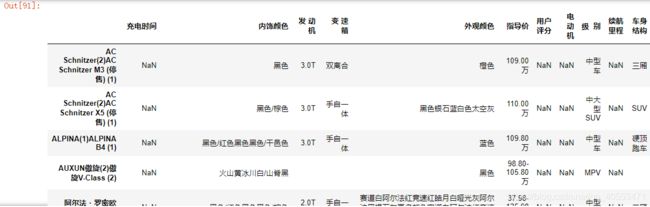
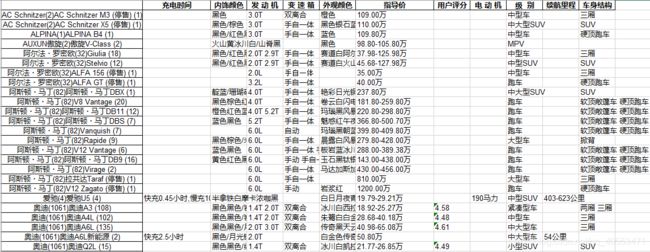
详细过程:
整个过程分成三个部分:
1,爬取汽车之家各个品牌(譬如奥迪)汽车对应的链接
2,爬取每一个品牌下各个汽车系列(譬如奥迪A3)的链接
3,使用2得到的链接爬取每个汽车系列的参数(譬如奥迪A3的发动机,价格,变速箱,颜色,用户评分等等)
先引入所需要的库,其中最后一个库的作用是将我们后面要用到的parms参数转化为字符串形式,代码如下:
import requests#request包
from bs4 import BeautifulSoup
import pandas as pd#pandas库用来储存结果
import lxml
from urllib.parse import urlencode
1,爬取汽车之家各个品牌(譬如奥迪)汽车对应的链接。
如图所示,我们要的是这一部分内容,那这一部分的内容怎么得到呢?
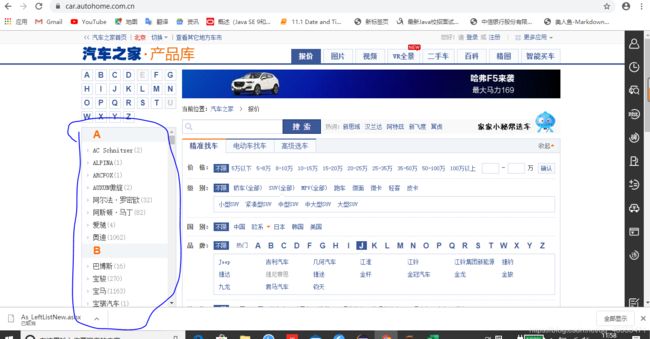
右键——检查——network——然后刷新浏览器,服务器会返回很多个包,下图所示的这个包即为我们想用的
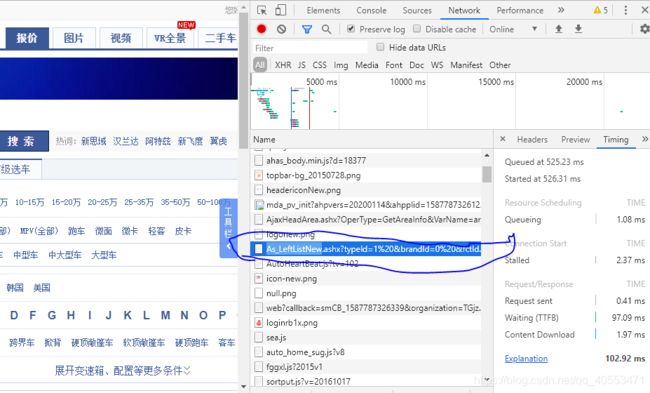
它的页面如下图所示,然后我们直接复制它的链接即可进行爬取,链接如下: https://car.autohome.com.cn/AsLeftMenu/As_LeftListNew.ashx?typeId=1%20&brandId=0%20&fctId=0%20&seriesId=0.

编写爬虫方法:
def getLongPage():
url = 'https://car.autohome.com.cn/AsLeftMenu/As_LeftListNew.ashx?typeId=1%20&brandId=0%20&fctId=0%20&seriesId=0'
headers = {
'Referer': 'https://car.autohome.com.cn/',
'Sec-Fetch-Mode': 'no-cors',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
try:
r = requests.get(url ,headers = headers)
if r.status_code == 200:
r.encoding = r.apparent_encoding#此处将编码改成网页的编码样式,防止出现乱码
soup = BeautifulSoup(r.text, "lxml")
return soup
except:
print("爬取失败!")
使用爬虫方法并解析返回的soup,我们使用find_all方法找到每一个’li’下面的’a’,并获取该节点下的文本,以及它的参数‘href’的值,由第二张图我们可以知道,这里的链接只有一部分,我们需要在它的前面加上’https://car.autohome.com.cn’ ,构成完整的链接
page = getLongPage()
carResult = {}
for i in page.find_all('li'):
for j in i.find_all('a'):
carResult[j.text] = 'https://car.autohome.com.cn' + j.get('href')
carResult
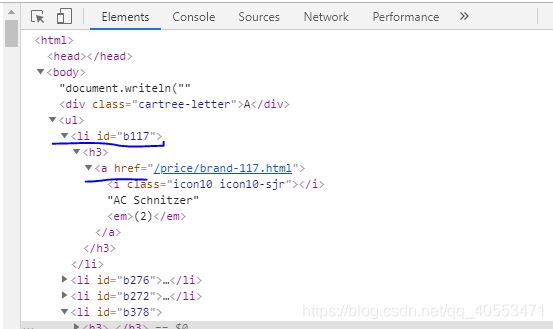
carResult的结果也就是各个品牌的url如下图所示:

2,爬取每一个品牌下各个汽车系列(譬如奥迪A3)的链接
我们以奥迪为例子,点击奥迪会看到奥迪品牌下面还会有奥迪A4,Q5,Q3,等车型,那我们如何拿到这些车型对应的链接呢。过程如下:
首先我们确定我们要的东西在哪里,点击奥迪汽车的链接https://car.autohome.com.cn/price/brand-33.html进入对应页面,鼠标右键——检查——Network——刷新浏览器页面,此时你会看到返回的很多个包,找到以下的包,我们要的东西就在里面
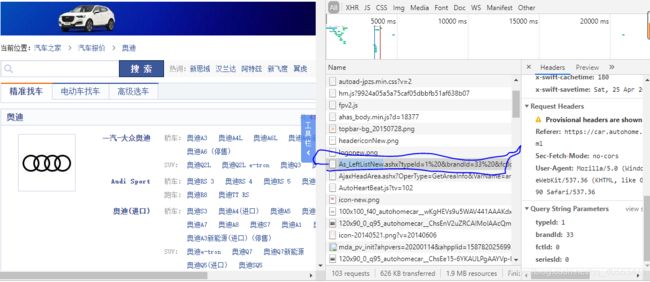
点进去的页面如下图:

接着我们进行可以爬取,获取奥迪旗下每一个车型的链接,但是我们想要的是所有品牌的汽车旗下各系列的车,我们该怎么办呢,我们在奥迪汽车的页面可以看到如下的一个参数,经过观察我们可以发现,这里的这个33就是咱们第一部分奥迪汽车对应的链接(https://car.autohome.com.cn/price/brand-33.html)中的33,其他的汽车品牌也是一样,所以我们将它们封装进一个方法,代码如下
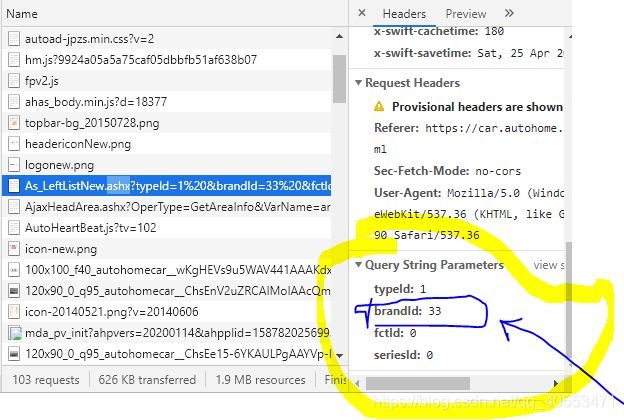
base_url = 'https://car.autohome.com.cn/AsLeftMenu/As_LeftListNew.ashx?'
def get_car(url_b,car_Result2,n):
headers = {
'authority': 'car.autohome.com.cn',
'method': 'GET',
'scheme': 'https',
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'fvlid=156974583432110wygoXZiH; sessionid=D7FE9717-245E-4F8D-8D42-AAF453D1F470%7C%7C2019-09-29+16%3A30%3A35.298%7C%7C0; autoid=851072202da5829e1b4e6cbb05975388; cookieCityId=110100; __ah_uuid_ng=c_D7FE9717-245E-4F8D-8D42-AAF453D1F470; area=460106; ahpau=1; sessionuid=D7FE9717-245E-4F8D-8D42-AAF453D1F470%7C%7C2019-09-29+16%3A30%3A35.298%7C%7C0; ahsids=3170; sessionip=153.0.3.115; Hm_lvt_9924a05a5a75caf05dbbfb51af638b07=1585205934,1585207311,1585266321; clubUserShow=87236155|692|2|%E6%B8%B8%E5%AE%A2|0|0|0||2020-03-27+08%3A35%3A50|0; clubUserShowVersion=0.1; sessionvid=0F2198AC-5A75-47E2-B476-EAEC2AF05F04; Hm_lpvt_9924a05a5a75caf05dbbfb51af638b07=1585269508; ahpvno=45; v_no=8; visit_info_ad=D7FE9717-245E-4F8D-8D42-AAF453D1F470||0F2198AC-5A75-47E2-B476-EAEC2AF05F04||-1||-1||8; ref=www.baidu.com%7C0%7C0%7C0%7C2020-03-27+08%3A38%3A40.425%7C2019-10-07+22%3A52%3A34.733',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
parms = {
'typeId': 1 ,
'brandId': url_b[url_b.index('brand-')+6: url_b.index('.html')],#截取第一部分的链接中的参数,譬如(奥迪汽车是33)
'fctId': 0 ,
'seriesId': 0,
}
url = base_url + urlencode(parms)#此行代码连接根路径及参数字符串
print(url)
re = requests.get(url)
soup = BeautifulSoup(re.text,'lxml')#直接解析
for i in soup.find_all('dd'):
for j in i.find_all('a'):
car_Result2[n + j.text] = 'https://car.autohome.com.cn'+j.get('href')
这个页面的分析方法同第一部分,用find_all方法查找’dd’,并在找到的节点下查找‘a’
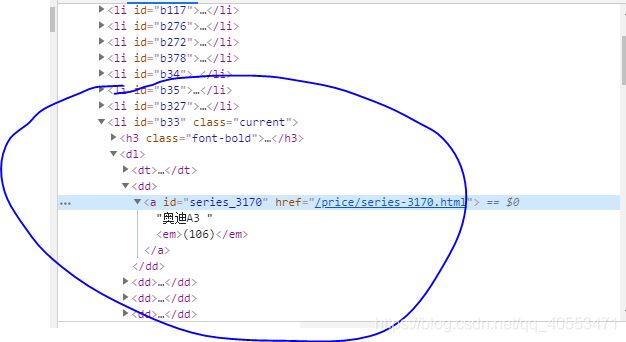
调用以上方法对所有汽车品牌进行操作,代码如下:
car_Result2 = {}
for n in carResult:
print(carResult[n])
get_car(carResult[n],car_Result2 ,n)
car_Result2
得到的car_Result2如下图所示:

3,使用2得到的链接爬取每个汽车系列的参数(譬如奥迪A3的发动机,价格,变速箱,颜色,用户评分等等)
这个部分我们要拿的主要是每个汽车的各种参数信息,如下图:
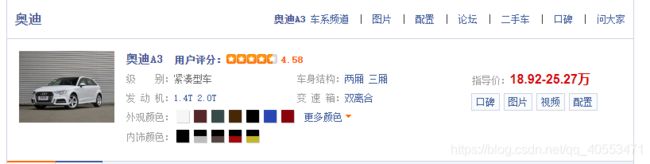
我们直接进入第二部分得到的各个车型的链接进行操作即可,主要是解析部分,此处将评分和参数分开拿,代码如下:
def get_car_information(url):
dic = {}
headers = {
'authority': 'car.autohome.com.cn',
'method': 'GET',
'scheme': 'https',
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'fvlid=156974583432110wygoXZiH; sessionid=D7FE9717-245E-4F8D-8D42-AAF453D1F470%7C%7C2019-09-29+16%3A30%3A35.298%7C%7C0; autoid=851072202da5829e1b4e6cbb05975388; cookieCityId=110100; __ah_uuid_ng=c_D7FE9717-245E-4F8D-8D42-AAF453D1F470; area=460106; ahpau=1; sessionuid=D7FE9717-245E-4F8D-8D42-AAF453D1F470%7C%7C2019-09-29+16%3A30%3A35.298%7C%7C0; ahsids=3170; sessionip=153.0.3.115; Hm_lvt_9924a05a5a75caf05dbbfb51af638b07=1585205934,1585207311,1585266321; clubUserShow=87236155|692|2|%E6%B8%B8%E5%AE%A2|0|0|0||2020-03-27+08%3A35%3A50|0; clubUserShowVersion=0.1; sessionvid=0F2198AC-5A75-47E2-B476-EAEC2AF05F04; Hm_lpvt_9924a05a5a75caf05dbbfb51af638b07=1585269508; ahpvno=45; v_no=8; visit_info_ad=D7FE9717-245E-4F8D-8D42-AAF453D1F470||0F2198AC-5A75-47E2-B476-EAEC2AF05F04||-1||-1||8; ref=www.baidu.com%7C0%7C0%7C0%7C2020-03-27+08%3A38%3A40.425%7C2019-10-07+22%3A52%3A34.733',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
re = requests.get(url,headers=headers)
soup = BeautifulSoup(re.text,'html.parser')
for k in soup.find_all('span',{'class':'score-number'}):
dic['用户评分'] = k.text
for i in soup.find_all('ul',{'class':"lever-ul"}):
for li in i.find_all('li'):
s = li.text
if ':' in s:
dic[s[:s.index(':')]] = s[s.index(':')+1:]
for j in soup.find_all('span' ,{'class': 'font-arial'}):
dic['指导价'] = j.text
return dic
然后我们调用以上方法,并将结果放入一个data里面,得到的data如下图所示:
data = {}
for i in car_Result2:
data[i] = get_car_information(car_Result2[i])

到这里,我们的爬取基本结束了,我们用得到的data构建dataFrame,代码和结果如下
import pandas as pd
frame = pd.DataFrame(data)
frame.T

我们也可以将结果存为excel
frame.T.to_excel(r'C:\Users\car.xls')