不用反向传播的HSIC Bottleneck到底讲了啥,及其keras实现
机器之心上周介绍了一篇论文,说是不用BP也能训练神经网络,论文叫做《The HSIC Bottleneck: Deep Learning without Back-Propagation》,HSIC Bottleneck: Deep Learning without Back-Propagation](https://arxiv.org/pdf/1908.01580v1.pdf)》,引用了一个HSIC度量,并用其实现了直接从利用输入输出来优化隐藏层的参数。
下面主要讲的我自己对文章的理解,但是不一定对。
HSIC度量
我们一般使用互信息度量两个分布的依赖强弱,但是一般只有在知道两个分布的情况下才能得到。论文直接引用了HSIC度量使用抽样来测量两个分布依赖的强弱。

核函数根据经验使用高斯核函数
![]()
用keras实现:
def kernel_matrix(x, sigma):
ndim = K.ndim(x)
x1 = K.expand_dims(x, 0)
x2 = K.expand_dims(x, 1)
axis = tuple(range(2, ndim+1))
return K.exp(-0.5*K.sum(K.pow(x1-x2, 2), axis=axis) / sigma ** 2)
def hsic(Kx, Ky, m):
Kxy = K.dot(Kx, Ky)
h = tf.linalg.trace(Kxy) / m ** 2 + K.mean(Kx) * K.mean(Ky) - \
2 * K.mean(Kxy) / m
return h * (m / (m-1))**2
如何跨层直接优化隐藏层
一个好的隐藏层,它的输出应该尽量跟输出的依赖强和输入的依赖弱。换句话说,就是隐藏层输出应该尽量保存和输出相关的信息,移除和跟输出无关的信息(所有信息都来自输入)。
用文中的公式表示就是:

这里 λ \lambda λ经验值取100.。
我们直接优化(4)就可以做到跨层优化网络了。
HSIC-Bottleneck Trained
我们把所有隐藏层的放在一起优化,就得到了HSIC-Bottleneck Trained,
公式为:
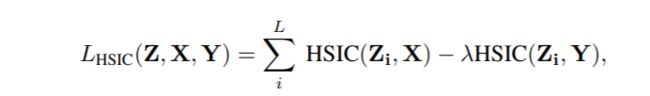
keras代码实现:
class HSICBottleneckTrained(object):
def __init__(self, model, batch_size, lambda_0, sigma):
self.batch_size = batch_size
input_x = model._feed_inputs[0]
input_y = model._feed_targets[0]
Kx = kernel_matrix(input_x, sigma)
Ky = kernel_matrix(input_y, sigma)
param2grad = {
}
trainable_params = []
total_loss = 0.
for layer in model.layers:
if layer.name.startswith("hsic"):
params = layer.trainable_weights
if not params:
continue
hidden_z = layer.output
Kz = kernel_matrix(hidden_z, sigma)
loss = hsic(Kz, Kx, batch_size) - lambda_0 * hsic(Kz, Ky, batch_size)
total_loss += loss
trainable_params.extend(params)
grads = K.gradients(loss, params)
for p, g in zip(params, grads):
param2grad[p.name] = g
else:
layer.trainable = False
model._collected_trainable_weights = trainable_params
model.total_loss = total_loss
optim = model.optimizer
def get_gradients(loss, params):
grads = [param2grad[p.name] for p in params]
if hasattr(self, 'clipnorm') and self.clipnorm > 0:
norm = K.sqrt(sum([K.sum(K.square(g)) for g in grads]))
grads = [clip_norm(g, self.clipnorm, norm) for g in grads]
if hasattr(self, 'clipvalue') and self.clipvalue > 0:
grads = [K.clip(g, -self.clipvalue, self.clipvalue) for g in grads]
return grads
optim.get_gradients = get_gradients
self.model = model
def reshape(self, x):
shape = list(K.int_shape(x))
shape[0] = self.batch_size
return K.reshape(x, tuple(shape))
def __call__(self):
return self.model
为了尽量保持keras代码的完整性,这里我们使用注入的方式实现的HSIC-Bottleneck Trained,动态的调整模型的属性值。
Post-Trained
最后,模型为了完成任务,在最后的隐藏层和模型输出之间添加一个输出层,完成特定的任务。
代码实现:
class PostTrained(object):
def __init__(self, model):
for layer in model.layers:
if layer.name != "output_layer":
layer.trainable = True
else:
# 冻结所有非输出层为不可训练
layer.trainable = False
self.model = model
def __call__(self):
return model
σ \sigma σ-Network
只使用一个 σ \sigma σ可能无法捕捉到足够多的信息,所以可以使用多个 σ \sigma σ来进行联合训练,读者可以根据上面的代码自己调整实现之。
代码开源在https://github.com/forin-xyz/Keras-HSIC-Bottleneck,可以自己改改。
优点
- 不用BP可以避免梯度爆炸/消失;
- 可以在某一层没有梯度的情况下跨层优化;
- 可以并行同时优化多个层。
缺点
- 目前来看效果并不能达到BP算法的效果,机器学习库也没有根据对应算法优化其速度。
一些想法
我们可以HSIC度量作为损失函数的一部分来优化网络,以避免梯度消失的情况下无法优化参数。