Kafka_Kafka 消费者 偏移量 与 积压 查询脚本 kafka-consumer-groups.sh
本文章对应的 kafka 版本是 kafka_2.11-0.10.0.1
版本号的含义
scala 2.11
kafka 0.10.0.1
背景:
kafka 0.9 及以上 有了一个大版本变化,
主要有以下几个方面:
1.kafka-client 不再区分高低api
2.kafka 消费者偏移量信息 不再单纯的存储在 zookeeper 中, kafka 会自己维护自己的 消费情况。
对于某些特殊的情况:如 kafka-console-consumer , 目前在 0.10.0.1 还是会存储在 zookeeper 中。
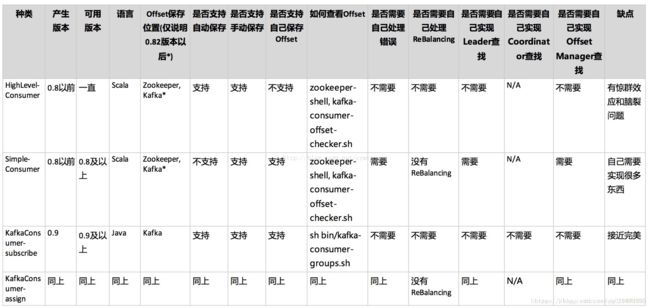
版本变迁 对 comsumer 影响 图解:
正文:
根据上面的背景介绍,我们不难看出针对于 0.9 以及 0.9 以下的版本查看 kafka 消费偏移量 的方式 有所不同。
由于目前主流环境都升级到 0.8 + , 这里我们针对于 >= 0.9 的版本进行讲解。
查询方法:
这里我们讲解的方法主要是通过原生 kafka 提供的工具脚本进行查询。
工具脚本的位置与名称 为 bin/kafka-consumer-groups.sh
[root@master my_bin]# cd $KAFKA_HOME
[root@master kafka]# cd bin/
[root@master bin]# ll
总用量 116
-rwxr-xr-x. 1 root root 1052 8月 4 2016 connect-distributed.sh
-rwxr-xr-x. 1 root root 1051 8月 4 2016 connect-standalone.sh
-rwxr-xr-x. 1 root root 861 8月 4 2016 kafka-acls.sh
-rwxr-xr-x. 1 root root 864 8月 4 2016 kafka-configs.sh
-rwxr-xr-x. 1 root root 945 8月 4 2016 kafka-console-consumer.sh
-rwxr-xr-x. 1 root root 944 8月 4 2016 kafka-console-producer.sh
-rwxr-xr-x. 1 root root 871 8月 4 2016 kafka-consumer-groups.sh
-rwxr-xr-x. 1 root root 872 8月 4 2016 kafka-consumer-offset-checker.sh
-rwxr-xr-x. 1 root root 948 8月 4 2016 kafka-consumer-perf-test.sh
-rwxr-xr-x. 1 root root 862 8月 4 2016 kafka-mirror-maker.sh
-rwxr-xr-x. 1 root root 886 8月 4 2016 kafka-preferred-replica-election.sh
-rwxr-xr-x. 1 root root 959 8月 4 2016 kafka-producer-perf-test.sh
-rwxr-xr-x. 1 root root 874 8月 4 2016 kafka-reassign-partitions.sh
-rwxr-xr-x. 1 root root 868 8月 4 2016 kafka-replay-log-producer.sh
-rwxr-xr-x. 1 root root 874 8月 4 2016 kafka-replica-verification.sh
-rwxr-xr-x. 1 root root 6358 8月 4 2016 kafka-run-class.sh
-rwxr-xr-x. 1 root root 1364 8月 4 2016 kafka-server-start.sh
-rwxr-xr-x. 1 root root 975 8月 4 2016 kafka-server-stop.sh
-rwxr-xr-x. 1 root root 870 8月 4 2016 kafka-simple-consumer-shell.sh
-rwxr-xr-x. 1 root root 945 8月 4 2016 kafka-streams-application-reset.sh
-rwxr-xr-x. 1 root root 863 8月 4 2016 kafka-topics.sh
-rwxr-xr-x. 1 root root 958 8月 4 2016 kafka-verifiable-consumer.sh
-rwxr-xr-x. 1 root root 958 8月 4 2016 kafka-verifiable-producer.sh
drwxr-xr-x. 2 root root 4096 8月 4 2016 windows
-rwxr-xr-x. 1 root root 867 8月 4 2016 zookeeper-security-migration.sh
-rwxr-xr-x. 1 root root 1381 8月 4 2016 zookeeper-server-start.sh
-rwxr-xr-x. 1 root root 978 8月 4 2016 zookeeper-server-stop.sh
-rwxr-xr-x. 1 root root 968 8月 4 2016 zookeeper-shell.sh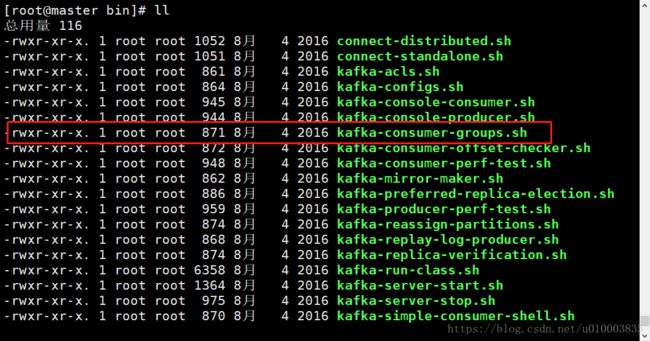
我们首先运行下这个脚本,看下帮助:
Option Description
------ -----------
--bootstrap-server consumer): The server to connect to.
--command-config passed to Admin Client and Consumer.
--delete Pass in groups to delete topic
partition offsets and ownership
information over the entire consumer
group. For instance --group g1 --
group g2
Pass in groups with a single topic to
just delete the given topic's
partition offsets and ownership
information for the given consumer
groups. For instance --group g1 --
group g2 --topic t1
Pass in just a topic to delete the
given topic's partition offsets and
ownership information for every
consumer group. For instance --topic
t1
WARNING: Group deletion only works for
old ZK-based consumer groups, and
one has to use it carefully to only
delete groups that are not active.
--describe Describe consumer group and list
offset lag related to given group.
--group The consumer group we wish to act on.
--list List all consumer groups.
--new-consumer Use new consumer.
--topic The topic whose consumer group
information should be deleted.
--zookeeper REQUIRED (unless new-consumer is
used): The connection string for the
zookeeper connection in the form
host:port. Multiple URLS can be
given to allow fail-over.
这里我们先编写一个生产者,消费者的例子,完整源代码在最后面(java 实现)
我们先启动消费者,再启动生产者, 再通过 bin/kafka-consumer-groups.sh 进行消费偏移量查询,
注意:
在执行脚本查询的时候,对于新的 kafka 自维护的 偏移量的 消费者来说 , 消费者 同时运行 是必须的。
否则会出现 group.id 指定 的 group 查找不到的错误 !!!!
由于kafka 消费者记录 group 的消费 偏移量 有两种方式 :
1)kafka 自维护 (新)
2)zookpeer 维护 (旧) ,已经逐渐被废弃
所以 ,脚本查看 消费偏移量的方式有两种 kafka自维护 / zookeeper维护
kafka 维护 消费偏移量的 情况:
1. 查看有那些 group ID 正在进行消费:
[root@master bin]# kafka-consumer-groups.sh --new-consumer --bootstrap-server 192.168.75.128:9092 --list
group
kafka-consumer-groups.sh --new-consumer --bootstrap-server 192.168.75.128:9092 --list
注意:
这里面是没有指定 topic 的,所以查看的所有的 topic 的 消费者 的 group.id 的列表。
注意: 重名的 group.id 只会显示一次
2.查看指定group.id 的消费者消费情况
[root@master bin]# kafka-consumer-groups.sh --new-consumer --bootstrap-server 192.168.75.128:9092 --group group --describe
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNER
group producer_consumer_java_test_20181009 0 2436 2437 1 consumer-1_/192.168.75.1
group test_find1 0 303094 303094 0 consumer-1_/192.168.75.1
group test_find1 1 303068 303068 0 consumer-1_/192.168.75.1
group test_find1 2 303713 303713 0 consumer-1_/192.168.75.1
kafka-consumer-groups.sh --new-consumer --bootstrap-server 192.168.75.128:9092 --group group --describe
zookeeper 维护 消费偏移量的 情况:
1. 查看有那些 group ID 正在进行消费:
[root@master bin]# kafka-consumer-groups.sh --zookeeper localhost:2181 --list
console-consumer-28542

[root@master bin]# kafka-consumer-groups.sh --zookeeper localhost:2181 --list
2.查看指定group.id 的消费者消费情况
[root@master bin]# kafka-consumer-groups.sh --zookeeper localhost:2181 --group console-consumer-28542 --describe
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNER
console-consumer-28542 test_find1 0 303094 303094 0 console-consumer-28542_master-1539167387803-268319a0-0
console-consumer-28542 test_find1 1 303068 303068 0 console-consumer-28542_master-1539167387803-268319a0-0
console-consumer-28542 test_find1 2 303713 303713 0 console-consumer-28542_master-1539167387803-268319a0-0

kafka-consumer-groups.sh --zookeeper localhost:2181 --group console-consumer-28542 --describe
常见问题:
[root@master bin]# kafka-consumer-groups.sh --new-consumer --bootstrap-server localhost:9092 --group group --describe
java.lang.RuntimeException: Request GROUP_COORDINATOR failed on brokers List(localhost:9092 (id: -1 rack: null))
at kafka.admin.AdminClient.sendAnyNode(AdminClient.scala:67)
at kafka.admin.AdminClient.findCoordinator(AdminClient.scala:72)
at kafka.admin.AdminClient.describeGroup(AdminClient.scala:125)
at kafka.admin.AdminClient.describeConsumerGroup(AdminClient.scala:147)
at kafka.admin.ConsumerGroupCommand$KafkaConsumerGroupService.describeGroup(ConsumerGroupCommand.scala:315)
at kafka.admin.ConsumerGroupCommand$ConsumerGroupService$class.describe(ConsumerGroupCommand.scala:86)
at kafka.admin.ConsumerGroupCommand$KafkaConsumerGroupService.describe(ConsumerGroupCommand.scala:303)
at kafka.admin.ConsumerGroupCommand$.main(ConsumerGroupCommand.scala:65)
at kafka.admin.ConsumerGroupCommand.main(ConsumerGroupCommand.scala)
产生原因:
kafka 的 conf/server.properties 中设置了 host.name
# The number of threads handling network requests
num.network.threads=3
# The number of threads doing disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to exceessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# segments don't drop below log.retention.bytes.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=127.0.0.1:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
host.name=192.168.75.128
#彻底删除 topic
delete.topic.enable=true

解决方法:
注释掉 host.name
重启服务
解释:
不强制要求必须输入host.name 为 192.168.75.128 的方式
==============================================
题外篇:
半多线程的生产者与消费者
生产者:
KafkaProducerSingleton.javapackage test.kafka.vm.half_multi_thread;
import org.apache.kafka.clients.producer.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
import java.util.Random;
public final class KafkaProducerSingleton {
private static final Logger LOGGER = LoggerFactory
.getLogger(KafkaProducerSingleton.class);
private static KafkaProducer kafkaProducer;
private Random random = new Random();
private String topic;
private int retry;
private KafkaProducerSingleton() {
}
/**
* 静态内部类
*
* @author tanjie
*/
private static class LazyHandler {
private static final KafkaProducerSingleton instance = new KafkaProducerSingleton();
}
/**
* 单例模式,kafkaProducer是线程安全的,可以多线程共享一个实例
*
* @return
*/
public static final KafkaProducerSingleton getInstance() {
return LazyHandler.instance;
}
/**
* kafka生产者进行初始化
*
* @return KafkaProducer
*/
public void init(String topic, int retry) {
this.topic = topic;
this.retry = retry;
if (null == kafkaProducer) {
Properties props = new Properties();
InputStream inStream = null;
try {
inStream = this.getClass().getClassLoader()
.getResourceAsStream("test/config/kafka/kafka.properties");
props.load(inStream);
//ISR 确认机制
props.put(ProducerConfig.ACKS_CONFIG,"1");
kafkaProducer = new KafkaProducer(props);
} catch (IOException e) {
LOGGER.error("kafkaProducer初始化失败:" + e.getMessage(), e);
} finally {
if (null != inStream) {
try {
inStream.close();
} catch (IOException e) {
LOGGER.error("kafkaProducer初始化失败:" + e.getMessage(), e);
}
}
}
}
}
/**
* 通过kafkaProducer发送消息
*
* @param topic 消息接收主题
* @param partitionNum 哪一个分区
* @param retry 重试次数
* @param message 具体消息值
*/
public void sendKafkaMessage(final String message) {
/**
* 1、如果指定了某个分区,会只讲消息发到这个分区上 2、如果同时指定了某个分区和key,则也会将消息发送到指定分区上,key不起作用
* 3、如果没有指定分区和key,那么将会随机发送到topic的分区中 4、如果指定了key,那么将会以hash的方式发送到分区中
*/
ProducerRecord record = new ProducerRecord(
topic, random.nextInt(3), "", message);
// send方法是异步的,添加消息到缓存区等待发送,并立即返回,这使生产者通过批量发送消息来提高效率
// kafka生产者是线程安全的,可以单实例发送消息
kafkaProducer.send(record, new Callback() {
public void onCompletion(RecordMetadata recordMetadata,
Exception exception) {
if (null != exception) {
LOGGER.error("kafka发送消息失败:" + exception.getMessage(),
exception);
retryKakfaMessage(message);
}
}
});
}
/**
* 当kafka消息发送失败后,重试
*
* @param retryMessage
*/
private void retryKakfaMessage(final String retryMessage) {
ProducerRecord record = new ProducerRecord(
topic, random.nextInt(3), "", retryMessage);
for (int i = 1; i <= retry; i++) {
try {
kafkaProducer.send(record);
return;
} catch (Exception e) {
LOGGER.error("kafka发送消息失败:" + e.getMessage(), e);
retryKakfaMessage(retryMessage);
}
}
}
/**
* kafka实例销毁
*/
public void close() {
if (null != kafkaProducer) {
kafkaProducer.close();
}
}
public String getTopic() {
return topic;
}
public void setTopic(String topic) {
this.topic = topic;
}
public int getRetry() {
return retry;
}
public void setRetry(int retry) {
this.retry = retry;
}
}
ProducerHandler.javapackage test.kafka.vm.half_multi_thread;
public class ProducerHandler implements Runnable {
private String message;
public ProducerHandler(String message) {
this.message = message;
}
@Override
public void run() {
KafkaProducerSingleton kafkaProducerSingleton = KafkaProducerSingleton
.getInstance();
kafkaProducerSingleton.init("test_find1", 3);
int i = 0;
while (true) {
try{
System.out.println("当前线程:" + Thread.currentThread().getName()
+ ",获取的kafka实例:" + kafkaProducerSingleton);
kafkaProducerSingleton.sendKafkaMessage("发送消息: " + message + " " + (++i));
Thread.sleep(100);
}catch (Exception e){
}
}
}
}
启动主函数:
ProducerMain.javapackage test.kafka.vm.half_multi_thread;
/**
* Created by szh on 2018/10/10.
*/
public class ProducerMain {
public static void main(String[] args){
Thread thread = new Thread(new ProducerHandler("qqq"));
thread.start();
}
}
消费者:
Kafka_ConsumerAuto.java
package test.kafka.vm.half_multi_thread;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public final class Kafka_ConsumerAuto {
/**
* kafka消费者不是线程安全的
*/
private final KafkaConsumer consumer;
private ExecutorService executorService;
public Kafka_ConsumerAuto() {
Properties props = new Properties();
props.put("bootstrap.servers",
"192.168.75.128:9092");
props.put("group.id", "group");
// 关闭自动提交
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "100");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer(props);
consumer.subscribe(Arrays.asList("test_find1"));
}
public void execute() {
executorService = Executors.newFixedThreadPool(3);
while (true) {
ConsumerRecords records = consumer.poll(10);
if (null != records) {
executorService.submit(new ConsumerThreadAuto(records, consumer));
}
}
}
public void shutdown() {
try {
if (consumer != null) {
consumer.close();
}
if (executorService != null) {
executorService.shutdown();
}
if (!executorService.awaitTermination(10, TimeUnit.SECONDS)) {
System.out.println("Timeout");
}
} catch (InterruptedException ignored) {
Thread.currentThread().interrupt();
}
}
}
ConsumerThreadAuto.javapackage test.kafka.vm.half_multi_thread;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import java.util.Collections;
import java.util.List;
/**
* 多消费者,多个work线程,难保证分区消息消费的顺序性
*
* @author tanjie
*/
public final class ConsumerThreadAuto implements Runnable {
private ConsumerRecords records;
private KafkaConsumer consumer;
public ConsumerThreadAuto(ConsumerRecords records,
KafkaConsumer consumer) {
this.records = records;
this.consumer = consumer;
}
@Override
public void run() {
for(ConsumerRecord record : records){
System.out.println("当前线程:" + Thread.currentThread() + ","
+ "偏移量:" + record.offset() + "," + "主题:"
+ record.topic() + "," + "分区:" + record.partition()
+ "," + "获取的消息:" + record.value());
}
}
}
ConsumerAutoMain.javapackage test.kafka.vm.half_multi_thread;
/**
* Created by szh on 2018/10/10.
*/
public class ConsumerAutoMain {
public static void main(String[] args) {
Kafka_ConsumerAuto kafka_consumerAuto = new Kafka_ConsumerAuto();
try {
kafka_consumerAuto.execute();
Thread.sleep(20000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
kafka_consumerAuto.shutdown();
}
}
}