解读《视觉SLAM十四讲》,带你一步一步入门视觉SLAM—— 第 9 讲 实践:设计前端
Hello,各位朋友,新年快乐!
我们要进入第9讲的解读了,第9讲是纯实践的一讲,我觉得作者的这个布置实在是对初学者太友好了,前面我们学习了前端的所有内容,然后来一个手写前端,一方面复习了前面的内容,另一方面可以让我们简单地窥探一下一个SLAM系统大概长啥样!我还是很希望你好好学习一下这部分代码,如果你是初学者,这可能是见过的最完整的SLAM系统了,如果你掌握了它,你再去看别的优秀开源SLAM框架,就会得心应手了!
解读
文件组织方式
- 1.bin:用于存放可执行的二进制文件;
- 2.include/myslam:用于存放SLAM模块的头文件;
- 3.src:用于存放源代码文件,也就是
.cc或者.cpp文件; - 4.test:用于存放测试用的文件;
- 5.lib:用于存放编译好的库文件;
- 6.config:存放配置文件;
- 7.cmake_modules:第三方库的cmake文件;
0.1版本
0.1版本主要是定义了基本的数据结构,主要是定义了5个类:
Camera:用于存放相机内参和外参,以及一些对于相机像素点的操作,包括像素点转换到空间点,空间点转换到当前相机坐标系下等函数;
Config:主要负责参数文件的读取,并且可以随时提供参数的值。它为写成了单例模式,它只有一个全局对象;
Frame:它主要用来保存一帧frame中的重要信息,包括时间戳、相对于参考坐标系的变换矩阵、对应的深度图、彩色图等。它其中还包含一些操作,比方说判断一个点是否在前frame视野中、获得相机中心、获得特征点对应的深度等;
Map:它用来管理所有的路标点,并负责添加新的路标点、删除不好的路标点。其实Map就是维护了一个持续的地图,我们一边做SLAM,一边将建立的3D点,添加到地图中,还会将关键的frame添加进map中,它的操作包括添加关键帧、插入地图点;
MapPoint:它用来表示路标点。地图点也是具有方向和描述子的,所以MapPoint中会有变量存储这些内容。
如果你还不习惯C++的编程风格或者不是很了解面向对象编程方法,你可能需要稍微看看C++的书籍补充一下,这些操作都是很基础的,也是很有效的。
0.1版本只是定义了一些基本数据结构,还没有赋予它功能!
0.2版本
先前我们学习的特征点匹配方法,都是基于前后两帧图像的,我们想想这样有啥缺点呢?我们对于前后两帧的依赖性太高了,如果上一帧位置出现了误差,下一帧误差继续累计,那么误差越来越离谱。
但是就算误差很大,我们通过前后两帧的匹配,还是可以将相机的位姿串起来的!
两两帧之间的特征匹配流程:
- 1.对新来的当前帧,提取关键点和描述子;
- 2.如果系统没有初始化,那么就以该帧为参考帧,根据深度图计算关键点的3D位置,然后返回第一步;
- 3.估计参考帧和当前帧的运动;
- 4.判断上述估计是否成功;
- 5.若成功,把当前帧作为新的参考帧,返回第1步;
- 6.若失败,记录连续丢失帧数。当连续丢失超过一定数量帧数的时候,VO状态设为丢失,算法结束。否则,返回第一步。
V0.2版本和V0.1版本相比,最大的区别,就是前者加入了VisualOdometry类的实现。
VisualOdometry类中的成员变量介绍:
enum VOState { //定义该枚举变量,目的是记录VO的当前状态
INITIALIZING=-1,
OK=0,
LOST
};
VOState state_; // current VO status
Map::Ptr map_; //Map类,主要用来存放和管理MapPoint与Frame
Frame::Ptr ref_; // reference frame,参考frame
Frame::Ptr curr_; // current frame ,当前frame
cv::Ptr<cv::ORB> orb_; // orb detector and computer,定义了ORB关键点提取器
vector<cv::Point3f> pts_3d_ref_; // 3d points in reference frame
vector<cv::KeyPoint> keypoints_curr_; // keypoints in current frame
Mat descriptors_curr_; // descriptor in current frame
Mat descriptors_ref_; // descriptor in reference frame
vector<cv::DMatch> feature_matches_;//特征匹配成功的结果
SE3 T_c_r_estimated_; // the estimated pose of current frame
int num_inliers_; // number of inlier features in icp,在ICP迭代中,有多少内点
int num_lost_; // number of lost times
// parameters
int num_of_features_; // number of features,特征点数量
double scale_factor_; // scale in image pyramid,图像金字塔缩放比例
int level_pyramid_; // number of pyramid levels,特征金字塔层数
float match_ratio_; // ratio for selecting good matches
int max_num_lost_; // max number of continuous lost times
int min_inliers_; // minimum inliers
double key_frame_min_rot; // minimal rotation of two key-frames
double key_frame_min_trans; // minimal translation of two key-frames
VisualOdometry类中的成员函数介绍:
public: // functions
//添加新的frame
bool addFrame( Frame::Ptr frame ); // add a new frame
protected:
// inner operation
void extractKeyPoints();
void computeDescriptors();
void featureMatching();
void poseEstimationPnP();
void setRef3DPoints();
void addKeyFrame();
bool checkEstimatedPose();
bool checkKeyFrame();
0.2版本的测试主函数,在test/run_vo.cpp中,它的核心代码:
for ( int i=0; i<rgb_files.size(); i++ )
{
Mat color = cv::imread ( rgb_files[i] );//读取RGB图片
Mat depth = cv::imread ( depth_files[i], -1 );//读取RGB对应的深度图
if ( color.data==nullptr || depth.data==nullptr )
break;
myslam::Frame::Ptr pFrame = myslam::Frame::createFrame();//新建一个指针指向Frame对象
pFrame->camera_ = camera;//将相机内参传入Frame对象中
pFrame->color_ = color;
pFrame->depth_ = depth;
pFrame->time_stamp_ = rgb_times[i];
boost::timer timer;
//向vo中增加frame,增加完之后,会自动提取关键点,计算两帧之间的运动,如果没有初始化也会自动初始化
vo->addFrame ( pFrame );
cout<<"VO costs time: "<<timer.elapsed()<<endl;
if ( vo->state_ == myslam::VisualOdometry::LOST )
break;
SE3 Tcw = pFrame->T_c_w_.inverse();//vo中计算出来变换矩阵,可以直接通过pFrame的指针调用
// show the map and the camera pose
cv::Affine3d M(
cv::Affine3d::Mat3(
Tcw.rotation_matrix()(0,0), Tcw.rotation_matrix()(0,1), Tcw.rotation_matrix()(0,2),
Tcw.rotation_matrix()(1,0), Tcw.rotation_matrix()(1,1), Tcw.rotation_matrix()(1,2),
Tcw.rotation_matrix()(2,0), Tcw.rotation_matrix()(2,1), Tcw.rotation_matrix()(2,2)
),
cv::Affine3d::Vec3(
Tcw.translation()(0,0), Tcw.translation()(1,0), Tcw.translation()(2,0)
)
);
cv::imshow("image", color );
cv::waitKey(1);
vis.setWidgetPose( "Camera", M);
vis.spinOnce(1, false);
}
0.3版本
0.3版本主要是加入了优化过程,因为PnP是采用的RANSAC方法计算的,所以很容易受到噪声影响,于是将RANSAC算出来的解,作为初值,然后使用非线性优化获得更加鲁棒的解。
0.3版本对于0.2版本的改动,主要在于加入了g2o_types.h/.cpp文件,定义了非线性优化的实现细节,然后将非线性优化加入到了void VisualOdometry::poseEstimationPnP()函数中,在通过RANSAC方法解出PnP之后,将解作为非线性优化的初始值,然后获得更加鲁棒的解。
g2o部分的代码还是前几讲的内容,没什么变化,0.3版本的主函数,和0.2版本也是一致的。
0.4版本
在0.3版本实现了一个非常脆弱的VO系统,失败的可能性非常大,通过前后两帧frame匹配计算运动的方法也非常简陋,现在我们想一想另一方法,我们将图像的特征点添加到一个很大的容器中(Map),然后每来一张图片,我就将图片和这个容器中的所有点就行匹配,匹配上之后,再将这张图片的特征点添加进容器中,这样是不是很合理啊!两两帧的VO和地图VO的区别如下图所示:
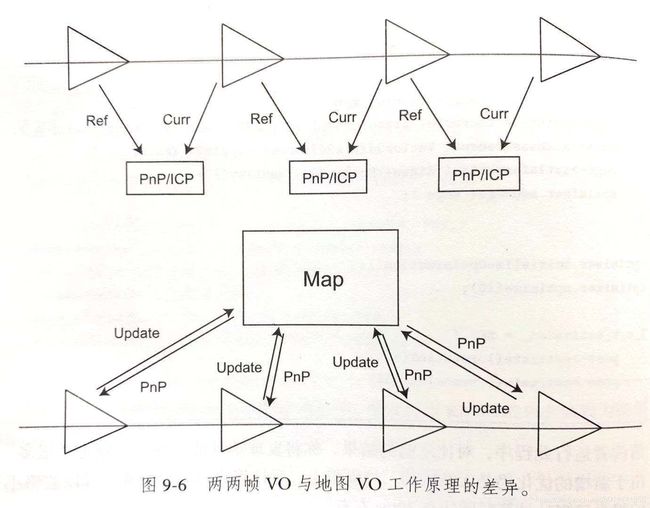
我不知道你是否明白这其中的道理,我给你稍微解释一下,我们先前的前后两帧求VO,每次求完之后就会丢弃前一帧的特征点,实际上我们可以不丢弃,而是将它们都保存下来,而后的图片都跟这个Map里面的特征点进行求VO,这样可以匹配的点就会更多,即使某一帧失败了,下一帧还可以跟Map进行匹配,这种容错率会更高。
这里的地图只是一个临时的概念,我建议你就将它理解为一个大容器,等学到建图这一讲你就明白了。
上面所说的这种容器,书中称为Map,我也沿用书中这种用法。如果我们从SLAM一开始一直维护这个Map那么这就是全局地图,如果我们只维护一个局部的Map(新进来的一帧图像可以看得见的特征点组成的Map)。
我们先看一下0.4和前面0.3有什么主要区别:
0.4版本中对MapPoint进行了完善,,然后修改了VIsualOdometry类中的几个主要函数,主要做的决策有,在第一帧中将所有的特征点都加入到地图中,后续如果地图点不在视野中了,就将其删除掉,在匹配数量减少的时候,添加新点。
简单的说一下0.4版本新送入的图片怎么和Map进行匹配:
- 1.当我们新进入一张图片的时候,首先提出关键点计算描述子;
- 2.然后对地图中的点进行遍历,如果属于当前帧视野内的就取出来;
- 3.将取出来的地图点(3D点)和当前帧图像点求解P3P,计算出位置作为初始值放入g2o进行优化。
关于代码更细节的东西,我将我注释过的代码,上传到GIthub上,方便你可以看我的注释。第9讲 实践:设计前端 0.4代码注释
这一讲0.4版本的代码,值得大家好好学习一下!
如果你的代码void VisualOdometry::poseEstimationPnP()中的g2o报错,请修改代码如下:
typedef g2o::BlockSolver<g2o::BlockSolverTraits<6,2>> Block;
std::unique_ptr<Block::LinearSolverType> linearSolver( new g2o::LinearSolverDense<Block::PoseMatrixType>());
std::unique_ptr<Block> solver_ptr( new Block ( std::move(linearSolver) ));
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg ( std::move(solver_ptr) );
g2o::SparseOptimizer optimizer;
optimizer.setAlgorithm ( solver );
让我们只争朝夕,不负韶华,共同迎接2020年的到来。