SAS Learning
Contents
- 基础知识
- Option语句
- 常用选项
- SAS数据集选项
- DATA语句
- infile
- input
- List input
- Column input
- informates
- 特殊读取方式
- 混合读取
- 读取某一字符后面的数据
- 跨行观测
- 一行有多个观测值
- 读取数据时即进行筛选/用@停留
- label
- retain
- sum
- 数组array
- put
- set处理、堆叠数据
- merge合并数据集
- update更新数据
- in=option追踪并选择观测值
- output输出
- 使用output将一个观测值变成多个观测值
- file/put导出数据
- PROC语句
- 基本语句
- where构造子集
- proc print打印输出
- proc import导入
- proc contents查看内容
- proc sort排序
- proc format创建格式
- proc means描述数据
- output输出
- proc freq计算频数
- proc tablulate表格报告
- proc report报告
- proc template风格模板
- proc transpose将观测值转变为变量
- proc univariate检验数据分布
- proc corr检测相关性
- proc reg回归分析
- proc anova单因素方差分析
- proc export创建文件
- 创建pc文件
- SAS自动变量
- 函数
- 常用函数
- 日期函数
- IF-THEN/DO-END/ELSE
- ODS(output delivery system)
- ods trace
- ods select
- ods output
- ods html
- ods rtf
- ods printer
- 宏
- %let创建一个宏变量
- %Macro创建模块化代码
- 宏的条件逻辑
- call symput数据驱动
- 排除宏错误的bug
- ?反正我还没看懂等会儿再看吧
- 不太重要但是也许会用到的知识谁说的好呢
- 可能要整理一下的专题没有自动标签功能真的很头疼
基础知识
- 分号结尾;
- 字母或者下划线开头;
- 不区分大小写;
- 数据步按照一行一行、一个观测值一个观测值的顺序执行;
- 注释方法:一种是*号,一种是用/**/表示,注意第二种注释方法不能放在第一列;
- SAS的所有函数都需要括号,即使没有参数;
- 列出变量名时可以有快捷方式,如:cat8-cat12;y–b之类。如果不能确定数据集中的变量顺序,可以用proc contents的postion选项来查看。
Option语句
OPTIONS 语句 OPTIONS 语句是 SAS 程序的一部分,并可影响之后的所有语句。
注意,后面的 OPTIONS 语句会覆盖前面的,即以后面的 OPTIONS 为主。
(也可以通过系统选项来改变)
常用选项
| Option | 作用 |
|---|---|
| CENTER/NOCENTER | 输出是否居中,还是左对齐。默认居中 |
| DATA/NODATE | 今天的日期是否出现在输出的顶部。默认输出 |
| LINESEZE | 控制输出行的最大长度,n 可能的值为 64 到 256 |
| NUMBER/NONUMBER | 输出的页面页码是否需要。默认需要。 |
| ORIENTATION=PORTRAIT; ORIENTATION=LANDSCAPE; |
指定打印输出的方向。默认竖向(portrait) |
| PAGENO=n | 输出页开始的页面。默认为 1 |
| PAGESIZE=n | 每个页面输出的最大行数。可能的值为 15 到 32767 |
| RIGHTMARGIN=n; LEFTMARGIN=n; TOPMARGIN=n; BOTTOMMARGIN=n |
指定打印输出的边缘大小。默认 0.00 英寸(Specifies size of margin(such as 0.75in or 2cm)to be used for printing output.Default:0.00in.) |
| YEARCUTOFF=yyyy | 设定起始年份 |
SAS数据集选项
- KEEP=variable-list 告诉 SAS 保留哪个变量
- DROP=variable-list 告诉 SAS 丢弃哪个变量
- RENAME=(oldvar=newvar) 重命名某个变量
- FIRSTOBS=n 从观测值 n 开始读取变量
- OBS=n 到观测值 n 停止读取
- IN=new-var-name
KEEP=,DROP=,和 RENAME=的作用与 keep、drop、rename 很相似。区别在于,后者适用于数据步中的所有变量,而前者仅使用与语句前面的那个数据集。而且,后者仅可以在数据步
中使用,而前者除了数据步和过程步,还可以在输入和输出数据集中使用。
DATA语句
infile
常用选项
| 选项 | 作用 |
|---|---|
| lrecl | 指定数据长度,不写则默认256 |
| firstobs | 从原始数据的第N行开始读取 |
| obs | 读到某一行 |
| missover | 不进入下一行,未赋值的变量即缺失值 |
| truncover | 如果某一行长度不够,也不转到下一行 |
| DLM | 指定分隔符 |
| DSD | 忽略引号中数值的分隔符; 自动将字符数据中的引号去掉; 将两个相邻的分隔符当做缺失值来处理。 |
-
如果长度过长,SAS 不能读取全部,此时需要在 INFILE 语句中使用 LRECL=来指定长度,这个长度必须是数据中最长行的长度。

-
使用 column input 或 formatted input 输入时可能会需要Truncover,因为这时有的数据行比其他的短。如果某一行没有占满,则必须用truncover,否则会转到下一行继续读取。
-
DLM=‘09’X指定时,是制表符。
-
DSD默认分隔符是都好,如果不是都好,要用delimiter来指定。
input
常用选项
| 选项 | 作用 |
|---|---|
| $ | 加在是字符串的变量后 |
| @ | 到达某一列,或者读取某一特定字符串后的数据 |
| @ | 在input语句结尾加,告诉SAS先停在此行 |
| @@ | 停止符号,适用于一行有多个观测值 |
| / | 换行 |
| #n | 跳转到第n行开始读取 |
| . | 缺少句号会使得SAS把形式当作变量名 |
| +1 | 跳过一列 |
| : | 遇到空格则不再继续读取,加在$length 前面 |
List input
input name $ age height;
限制条件
- 你必须读取所有的数据记录,不能跳过某些值、缺失值必须用句号“.”代替。
- 字符串数据不能包含空格、长度不能超过 8 个字符。
- 如果数据文件包含日期变量或者其他需要特别处理的变量,list input 将不再适用。
虽然很多限制,但仍有大量的文件可以用这种方式读取。
Column input
input name $ 1-10 age 11-13 height 14-18;
当每个变量的值都出现在数据行的相同位置时,可以使用Column input。
限制条件
- 变量值是字符串或者标准数值(只包含数据、小数点、正负号、和科学标注的 E。逗号和日期都不能算)。
优势
2. 不要求变量值之间的空格。
3. 缺失值可以直接用空格代替。
4. 字符串中可以使用空格。
5. 可以跳过不需要的变量。
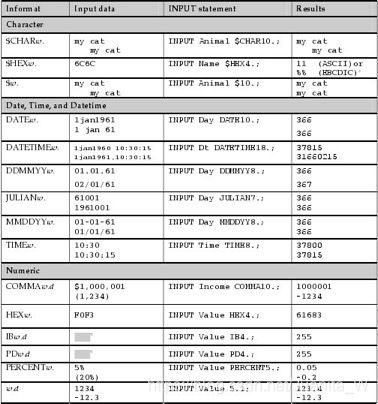
informates
用于读取非标准格式的原始数据。
input name $10. age 3. height 5.1 +1 birthdate MMDDYY10.;
可选变量形式
特殊读取方式
混合读取
input parkname $ 1-22 state $ year @40 acreage COMMA9.;
混合读取方式有时会遇到问题:SAS 通过一个指示器标注位置,来读取原始数据的一行,但每种读取方式对指示器的使用稍有不同。List 方式下,SAS 自动找到非空格区域并开始读取; column 方式下,SAS 读取你所指定的特定位置;informatted 方式下,SAS 不理会指示器的标准,只是依次的读取。这时,就会需要列指示器@n,来人为的让 SAS 的读取直接跳至某列。
读取某一字符后面的数据
input @'Breed:' DogBreed :$20.;
第二种方法只要知道要读取的数据的前面那个字符或单词即可。
如果要使 SAS 读取过程中遇到空格则不再继续读取,则要在$length 前面加冒号“:”
跨行观测
input city $ state $
/ normalhigh normallow
# 3 recordhigh recordlow
行指示器:
- 斜线/:告诉 SAS 跳至原始数据的第二行
- #n:跳至第 n 行,n 代表原始数据中某观测值的行数
一行有多个观测值

![]()
input city $ state $ normal mean @@;
当一行出现多个观测值时,可以在 input 语句结尾加一个停止符号@@ 。
读取数据时即进行筛选/用@停留
input tpye $ @;
if type = 'surface' then delete;
input name $ 9-38 amtraffic pmtraffic;
在input语句结尾加@,告诉SAS先停在此行,同时用if语句检测该观测值是否满足需要,如果是,那么再用一个input语句来读取现有的变量。
@的作用类似于@@,都是行停留指示符(line-hold specifiers),不同地方在于停留多久,@能使 SAS 停留到下一个 input 语句(也不换行),@@能使停留的时间到下一个 data 步(也不换行)。
label
label 语句为变量打上标签,并储存在数据集中,在打印时会显示。过程步中也可以使用 label,但只在 proc contents 中有效,不会储存在数据集中。
retain
retain 语句可以让 SAS 保存前一次变量的值。它可以出现在数据步的任何位置。
RETAIN variable-list (initial-value);
sum
sum(v,expression)
这个语句将表达式的值赋给变量,同时将变量的值保留到下一次迭代。这个变量必须是数值型,且初始值为 0。
数组array
array name(n) $ variable-list;
- Name 是数组名,n 是变量数,()也可以用[]和{}代替。如果变量是字符串,则需要 , 且 变 量 是 新 创 建 的 字 符 串 时 , ,且变量是新创建的字符串时, ,且变量是新创建的字符串时,是必须的。变量名依照顺序排列。
- 数组本身不储存在数据集中,只有在数据步中才被定义。

*注意这里数组没有被保存到数据集中,而 i 被保存了。 *
put


- Data null 是告诉 SAS 不要写数据集名,以便使得程序更快。
- File 语句创建了一个输出文件,空标题 title 语句告诉 SAS 去除所有的自动标题。
- 第一个 put 语句以一个指示器开头,@5,告诉 SAS 移动到第 5 列,接着打印出“candy sales report for”,后面是姓名 name。变量 name、class 和 quantity 都是以 list 方式打印,而 profit 是使用 formatted 方式打印,并给定格式 dollar6.2。
- 一个斜杠是指跳到下一行,两个斜杠是跳到下两行。
- 最后,语句 put_age_是在每个学生报告下面插上页码。

set处理、堆叠数据
SET 语句可以增加新变量、创建子集、修改数据集。SET 语句是一次一个变量地,将一个数据集放入数据步中予以分析。
- 把两个数据集上下合并
data data1;
set northdata southdata;
by passnumber;
- 合并total和原始数据。
data new-data;
if _N_ =1 then set summary-data;
set original-data-set;
只在数据步的第一次迭代中,SAS 读取了 summary 数据集,之后为新数据的所有变量记住这个变量值。它的工作原理在于 SET 语句是自动记住的。往常之中,记住的变量会被下一个观测值改写,但这里变量只在第一次迭代的时候读取,并为所有观测值记住,这一技术适用于没有匹配变量的情况下,将一个单个观测值合并到多个观测值中。
- 选择观测值。
data animals;
set animals(firstobs=101 obs=120);
proc print data=animals (firstobs=101 obs=120);
**数据集选项是用于数据步和过程步中存在的数据集,而系统选项适用于所有的文件和数据集。如果同时使用同样的系统选项和数据集选项,那么后者将覆盖前者。 **
merge合并数据集
合并前必须要进行排序
data data1;
merge data2 data3;
by v-list;
- 匹配合并
- 一对多合并。注意:一对多的一要放在前面。
- 合并统计量与原始数据。
合并数据集,首先,如果数据没有排序,使用 sort 过程按照匹配变量排序。之后,在 data 语句中对新 SAS 数据集命名,再使用 merge 语句列出要合并的数据集名。使用 BY 语句说明共同变量。
update更新数据
update 语句用来更新大量新数据信息。与 merge 语句一样,都是按照匹配变量来合并数据,不同点在于:
- 匹配变量的变量值有唯一性。
- 交易数据的缺失值不会改写主数据中存在的值。
data master-data;
update master-data transaction-data;
by v-list;
只能指定两个数据集,一个是主数据集一个是交易数据,都需要按照匹配变量排序。且 BY 变量必须具有唯一性。
in=option追踪并选择观测值
in=option可以用在data步中的任何地方,但是大部分用在merge语句上,接在要追踪的数据集后面。


output输出
每一个数据步的结尾都有一个暗含的 output 语句,它告诉 SAS 在处理下一个观测值之前,将当前的观测值写入输出数据集中。可以用自己的 output 语句来推翻这个暗含的 output 语句。

使用output将一个观测值变成多个观测值


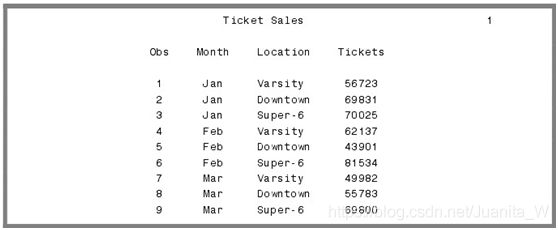
SAS 通常在数据步结尾将一个观测值写入数据中,但可以写入多个观测值,在 DO loop 中或单独使用 output 语句。Output 语句控制何时将观测值写入 SAS 数据集中。
如果数据集中没有 OUTPUT 语句,则暗含在结尾,放置了 output 之后,则结尾的就不在暗含存在。当 SAS 出现 OUTPUT 语句时,则写入一个观测值。
file/put导出数据

data _NULL_;
set activity.golf;
file 'c:\mydata\nowfile.dat' dsd dlm='delimiter';
put coursename 'golf course' @32 greenfees dollar7.2 @40 'par' par;
run;
_NULL_是告诉 SAS 不要新建数据集,以节省电脑资源。
SET 语句告诉 SAS 读取永久数据集 GOLF.
FILE 语句告诉 SAS 要创建的输出变量的名字.
PUT 语句告诉 SAS 写入的内容和路径。Put 语句包含了两个引用的字符串,“Golf Course”和 “Par”,这两个将插入原始文件中。Put 语句使用@列指示符告诉 SAS 变量的变量值放置在哪里。为 GreenFees 变量赋 DOLLAR7.2 格式。用 put 语句可以完全控制原始文件。
PROC语句
基本语句

- 除了proc sort,其他过程都假设数据已经进行了排序,如果数据还没有排序,那么在分析前需要用proc sort进行排序。
- by语句在sort中是必须的,在其他过程中是对变量进行分别分析,且是可选的。
- title和footnote是为输出加上标题和脚注。可以在后面加上数字来添加多个标题和脚注。*eg.FOOTNOTE3’This is the third footnote’; *
也可以通过title+空值来去除标题。 - label为输入的变量加上标签。**在数据步中使用 label 语句,则标签会保存在数据集中;在过程步中使用,标签只在这个过程中有效。 **
where构造子集
可以用 where 构造子集,它方便快捷,因为他不创建新的数据集。且能够用在过程步中,只有满足条件的观测值才进行proc过程。

proc print打印输出
常用选项
| 选项 | 作用 |
|---|---|
| title | 如果不指定标题,SAS 将以“the SAS system”作为标题在每一页的顶部。 |
| noobs | 默认打印观测值数,可以用这个取消 |
| label | 默认打印时用变量标签代替变量,用这个取消 |
| by v-list | 分类打印,要求必须进行过排序 |
| ID v-list | |
| sum | 打印变量总数 |
| var v-list | 制定打印哪部分变量以及打印顺序,默认打印全部 |
| format | 将格式和变量联系起来 |
FORMAT Profit Loss DOLLAR8.2 SaleDate MMDDYY8.;可以将格式 DOLLAR8.2 和变量 profit、loss 联系起来,把格式 MMDDYY8.和格变量 saledate 联系起来。- **Format 可以用在数据步和过程步中,前者将把格式永久储存,后者只是临时储存。 **
proc import导入
*读入普通文件
proc import datefile=’filename’ out=data-set DBMS=identifier REPLACE;
*读入access files
proc import database='database-path' datatable='table-name' out=data-set DBMS=identifier REPLACE;
常用选项
| 选项 | 作用 |
|---|---|
| DBMS | 文件扩展名不是csv或者txt,或者是DLM格式的 |
| replace | 代替名字已经存在的数据集 |
| getnames | 从第一行获取变量名,默认为yes |
| delimiter | 改变默认的分隔符,默认为空格 |
| sheet | 指定需要读取的是哪一个工作簿 |
- Proc import 会浏览你的数据文件,自动决定变量类型(字符串或数值),为字符串变量分配正确的长度,辨认出日期变量。
- 默认从第一行获取变量名。
- 如果想要创建的数据集名字已经存在,那么要用 replace 选项代替。
- **proc import会自动识别扩展名。**如果文件没有正确的扩展名,或者是DLM格式的,必须在proc import语句中用DBMS=option。


proc contents查看内容
proc contents data=data-set;
常用参数
| 参数 | 作用 |
|---|---|
| POSITION | 查看数据集中变量的顺序 |
proc sort排序
proc sort data=lala out=lalala;
by v1 v2...vn;
常用参数
| 参数 | 作用 |
|---|---|
| out | 如果缺失out=,则SAS会将排序后的数据集代替原来的数据集。 |
| nodupkey | 排序时删除重复值 |
| descending | 默认是升序,加在需要降序的变量前面 |
proc format创建格式
proc format;
value name 'A'='Asia'
1,3,5,7,9='odd'
0<-high ='positive non zero';
- name 是格式的名字,如果格式是位字符串设计,则必须以$ 开头,长度不能超过 32 个字节(包括$),不能以数字结尾,除了下划线,不能包含其他任何特殊符号。且名字不能与已有的格式名冲突。
- 变量值是字符串要加上引号
- range 不止一个值要用逗号隔开
- 连续的 range 要用
- 关键字 low 和 high 可以用来指代变量中最小和最大的的非缺失值
- 可以用<来排除或指代某些范围
- other 可以给任何没有列在 value 语句中的变量分配格式。
proc means描述数据
如果不加选项,则默认打印出非缺失值个数、均值、标准差、以及最大最小值,下面是用选项可以查看的统计量。
常用选项
| 选项 | 作用 |
|---|---|
| var | |
| max,min | 最大最小值 |
| mean | 均值 |
| median | 中位数 |
| n nmiss |
非缺失值的数量 缺失值变量个数 |
| range | 范围 |
| stddev stderr |
标准差 平均标准差 |
| sum sumwgt |
求和 权数变量之和 |
| noprint | 不需要产生打印结果 |
| clm | 双侧置信区间 |
| lclm uclm |
单侧(低侧)置信区间 单侧(高侧)置信区间 |
| css | 调整的平方和 |
| cv | 变异系数 |
| kurtosis | 峰度 |
| skewness | 偏度 |
| probt | probability for Student’s t |
| T | Student’s t |
| Q1(P25) | 25%quantile |
| P1 | 1%quantile |
| alpha=0.10 | 修改置信度,默认为0.05 |
如果没有其他语句,proc means 语句会给你数据集中所有观测值和所有数值变量的统计量。
- BY variable-list; 分变量单独分析,但数据必须先按照 variable-list 的变量顺序排序(proc sort)。
- CLASS variable-list; 也是分变量单独分析,看起来会更集中一些,且不需要排序。
- VAR variable-list; 指定分析中使用哪种数值变量,默认则使用所有的数值变量。
output输出
OUTPUT OUT=data-set statistic(variable-list)=name-list ;
- statistic 可能是 proc means 语句中的任何一种统计量(sum,n,mean…)
- variable-list 则界定 VAR 语句中哪些变量需要输出
- name-list 则定义统计量的新名字。
proc freq计算频数
proc freq data=datas;
tables v1 v2*v3;
常用参数
| 参数 | 作用 |
|---|---|
| agree | 检测分类性,包括 McNemar’s test,Bowker’s test,Cochran’s Q test,and kappa |
| statistics | |
| chisq | 用卡方统计量检测一致性和同类性 |
| cl | 一致性检测的置信区间 |
| cmh | Cochran-Mantel-Haenszel statistics |
| exact | Fisher’s exact test for tables larger than 2X2 |
| measures | 一致性测量,包括 Pearson and Spearman correlation coefficients,gamma,Kendall’s tau-b,Stuart’s tau-c,Somer’s D |
| plcorr | polychoric correlation coefficient |
| relrisk | relative risk measures for 2X2 tables |
| trend | the Cochran-Armitage test for trend |
| list | 用list形式打印交叉表(而不是网格) |
| missing | 频率统计量中包含缺失值 |
| nocol | 强制在交叉表中不打印列百分比 |
| norow | 强制在交叉表中不打印行百分比 |
| out | 输出数据集 |
proc tablulate表格报告
proc tabulate data=data;
var analysis-variable-list;
class classification-variable-list;
table page-dimension,row-dimension,column-dimension;
table PCTN*(Locomotion Type);
常用参数
| 参数 | 作用 |
|---|---|
| class | 哪些变量将数据分成不同部分 |
| table | 定义一个表,可以指定三个维度:页、行、列 |
| missing | 考虑缺失数据,一般默认不考虑缺失数据 |
| var | 分析列表的计算值 |
| format | 改变数据的格式 |
| box | 在报告左上角的空格中写一句话,前面要加/ |
| misstext | 为空数据格指定一个值,默认是句号,前面要加/ |
| row=float | 强制去除空白空格 |
- **如果只指定一个维度,则默认是列维度;如果指定两个,则是行和列。 **
- Concatenating 变量或关键词,只需用空格分开列出即可;cross 变量或关键字只需要用*分开列出即可;group 变量只需要用括号括住变量或关键词。
- 下面是 tabulate 可以计算的值:
ALL:增加行、列或页,显示总数
Max:最高值
Min:最低值
Mean:算术均值
Median:中位数
N:非缺失值个数
Nmiss:缺失值数
P90:90th 分位数
Pctn:某类的观测值百分数
Pctsum:某类值总和的百分数
STDDEV:标准差
SUM:求和


proc report报告
Report 包含 print、means 和 tabulate、sort 的所有功能
proc report nowindows;
column v-list;
常用参数
| 参数 | 作用 |
|---|---|
| column | 哪些变量该包括,并以何种顺序,默认全部包括 |
| nowindows | 关闭交互report窗口 |
| headline | 在顶部下方加一条线 |
| headskip | 在顶部下方留一段空白 |
| define | 为单个变量指定一些选项 |
| missing | 考虑缺失值,一般默认不考虑 |
- 只要报告中起码有一个字符串变量,默认的报告就是每个观测值一行。但如果报告全是数值变量,默认 proc report 将会加总这些变量,即使是日期变量也会被加总。
DEFINE variable/options’column-header’;
- Define选项:
- Across:为变量的每一个变量值都创建一个列

- Group:为每个变量的变量值都创建一行。

- Analysis:为变量创建统计量,数值变量默认有这个 usage 选项,且统计量默认为 sum。
- Display:为数据集中的每一个观测值都创建一行,对于字符串变量,这个选项是默认的。
- Order:为每个观测值都创建一行,且行值的排列是是按照指定的变量来顺序。
- break语句可以为报告增加停顿,为每个指定的变量的变量值增加停顿。
break location variable/options;
rbreak location/options;
Location 有两种可能值——before 和 after,决定是之前停顿还是之后停顿。斜杠之后的选项告诉 SAS 插入哪种停顿,主要类型有:
- OL 停顿的地方加入横线
- Page 开始一个新的页面
- Skip 插入一个空行
- Summarize 插入数值变量之和
需要注意的是,break 要求指定一个变量,而 rbreak 不需要。因为 rbreak 只产生一个停顿(开始或结尾),而 break 语句为指定的变量的每一个变量值都产生停顿。这个变量必须是 group 变量或 order 变量,并且要在 define 语句中定义过。可以在任何报告中使用 rbreak 语句,但只能在有最起码一个 group 或者 order 变量的报告中使用 break 语句。
- 输出统计量
给变量应用统计量,在变量和统计量之间插入逗号即可,统计量 N 不需要逗号。应用多个统计量,需要括号,如下面代码要求一个变量 age 应用两个统计量 min 和 max;两个变量 height 和 weight 应用一个统计量 mean.
COLUMN Age,MEDIAN N;
COLUMN Age,(MIN MAX)(Height Weight),MEAN;
proc template风格模板
proc template;
list styles;
run;
一些内置模板如下:

- 注意 RTF 和 PRINTER 既是目的地名又是风格名。DEFAULT 是 HTML 的默认风格,RTF 是 RTF 输出的默认风格,PRINTER 是 PRINTER 的默认风格。
- Print、report、TABULATE 三个过程中,可以使用 style=option 来直接控制输出特征,而不需要创建一个新的模板。
proc transpose将观测值转变为变量
transpose 过程可以转置数据集,将观测值转变为变量或将变量转变为观测值。
PROC TRANSPOSE DATA=old-data-set OUT=new-data-set;
BY variable-list;
ID variable;
VAR variable-list;
- ID 语句
ID 语句命名变量,这些变量值将变成新的变量名,ID 变量在一个数据集中只能发生一次,如果有 BY 语句,那么在一个 by-group 中,变量值必须是唯一的。如果 ID 变量是数值型变量,新的变量名必须有一个下划线作为前缀(_1 or_2,for example)。如果不适用 ID 语句,新变量将命名为 COL1,COL2 等。 - VAR 语句
VAR 语句命名变量,这个变量的变量值是要转置的。


proc univariate检验数据分布
产生统计量以描述单个变量的分布。这些统计量包括均值、中位数、mode、标准差、偏度和峰度。
默认打印所有的统计量:mean,variance,skewness,quantiles,extremes,t tests,standard error
| 选项 | 作用 |
|---|---|
| var | 指定变量,默认计算所有数值变量的统计量 |
| normal | 进行正态测试 |
| plot | 画出数据的三个图(茎叶图、箱线图、正态图) |
| by | 对单个组进行分析,前提是进行了sort排序 |
| title | 标题 |
proc corr检测相关性
计算最近创建的数据集中的所有数值变量两两相关系数。
proc corr;
var v-list;
with v-list;
VAR 语句中的变量出现在交叉表顶部,而 with 的变量出现在左侧。
默认计算Pearson 积差相关系数。还可以计算spearman(Spearman’s rank correlations);hoeffding(for Hoeffding’s D statistic) ;kendall(for Kendall’stau-b coefficients) 。
proc reg回归分析
proc reg;
model dependent=independent;
plot dependent*independent='symbol'P.*independent='symbol'/ overlay;
注意:
- Model 语句中,自变量在左边,因变量在右边。
- Symbol 的值指定 SAS 使用哪种标记来标注数据点,如果不指定,SAS 会直接使用数字。
- P.是代表预测值的关键词。
proc anova单因素方差分析
proc anova;
class v-list;
model dependent=effects;
means effects/options;
注意:
- Class 描述分类变量,并要在 model 语句之前,对于单因素方差分析,只需要列出一个变量。
- Model 语句描述了自变量和效应(effects)。对于单因素方差分析,效应就是分类变量。每组的观测值数要求一样,这样的数据为平衡的。
- Means语句计算出 model 语句中任何一种主效应的自变量的均值。另外,means 还可以做几种多重比较检验,包括 Bonferroni t tests(BON),Duncan’smultiple-rangetest(DUNCAN) , Scheffe’smultiple-comparison procedure(SCHEFFE) , pairwise t tests(T),和 Tukey’s studentized range test(TUKEY)。
proc export创建文件
将代码融合到现有的 SAS 程序中,每一次创建文件时,不需要通过 export Wizard。
proc export data=data1 outfile='filename' dbms=option replace;
delimiter='&';

注意:
- 空格分割的文件,是没有扩展名的。因此注意空格分割的文件,是没有扩展名的。
- 如果想创建一个有分隔符的文件,不是逗号、tab 或者空格分隔的,就需要 DELIMITER 语句。 DELIMITER 语句不在乎使用什么扩展名,也不在乎指定的哪种 DBMS identifier,文件将会使用你在 identifier 中指定的分隔符。
创建pc文件
如果用的是 Windows 系统,EXPORT procedure 可以创建 Microsoft Access,Microsoft Excel,dBase,和 Lotus files。

默认情况下,Microsoft Excel sheet 的名字与 SAS 数据集一样,通过 SHEET=语句可以指定不同的名字(该语句对 Microsoft Excel 4 or Microsoft Excel 5 无效)。Sheet 名中特殊的字符将转化为下划线,且$不允许放在 sheet 名字的后面。
SAS自动变量
| 自动变量 | 作用 |
|---|---|
| _ N _ | 记录了 SAS 在数据步中循环的次数 |
| _ ERROR _ | 如果一个观测值的数据出现错误,ERROR 会被赋值为 1,否则赋值为 0。 |
| FIRST.variable LAST.variable |
当使用 BY 语句时,这两个变量才有效。SAS 处理一个观测值时,如果某个变量的新变量值是第一次出现,first.variable 被赋值为 1,其他观测值中被赋为 0。 |



函数
函数基本形式:function-name(argument,argument,…),所有的函数都需要括号,即使没有参数。
常用函数
| 函数 | 作用 |
|---|---|
| MDY(MonthBorn,DayBorn,YearBorn) | 生成yr年m月d日的SAS日期值 |
| DAY(day) | 返回日期在一个月里的天数 |
| TODAY() | 返回今天的日期 |
| QTR(n) | 计算四分之一 |
| MEAN(x1,x2,…) | 均值函数 |
| Type(str) | 将原来的字母转换成大写字母 |
日期函数
IF-THEN/DO-END/ELSE
*一个执行;
if condition then DO;
else if condition THEN action;
else if condition THEN action;
else action;
*多个执行;
if condition THEN DO;
action;
action;
end;
*循环;
do i=1 to 10;
if condition then action;
end;
- 把IF-THEN用于data步可以进行数据筛选和子集创建。
ODS(output delivery system)
LISTING 标准 SAS 输出
Output SAS 输出数据集
Html 超文本标记语言
RTF 富文本格式
PRINTER high resolution printer output
PS 附言
PCT Printer Control Language
PDF、MARKUP、DOCUMENT
DOCUMENT 目的地,允许创建一个可重复使用的输出。
ods trace
打印出 SAS 日志中输出对象的信息。

ods select
选择需要的输出对象。
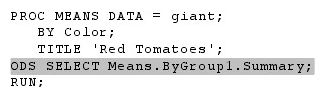

ods output
储存从过程输出的任何一部分。
首先要使用 ODS TRACE 语句决定选择输出对象名。然后使用 ODS OUTPUT 语句将输出对象发送到 OUTPUT 目的地中。
这个语句不属于数据步和过程步。ODS OUTPUT 打开 SAS 数据集并等待正确的过程输出,数据集保持开放,直到过程步的结尾。因为 ODS OUTPUT 是立即执行的,它将应用于 proc 正在处理的数据,或者应用于下一个 proc(如果目前没有 proc)。为确保得到正确的输出,建议将 ODS OUTPUT 语句放在 PROC 语句之后,下一个 PROC 、DATA 或 RUN 语句之前。
ods html
将输出发送到 HTML 目的地,将得到 HTML 格式的文件。
ODS HTML BODY='body-filename.html' options;
Option 是用来改变 HTML 的类型(contents,page,or frame)
- Contents= contents 文件是一个链接到主体文件的一个目录表,它将会列出输出的每个部分,点击表中某个条目,相关输出会出现。
- Page= page 文件类似于 contents 文件,不同的是,contents 通过标签列出输出的每个部分,而 page 文件通过页码列出。
- Frame= frame 允许同时访问在不同区域、框架或浏览器窗口中,访问主体文件、 contents 文件和 page 文件。
- Style= 这个选项允许指定一个风格模板,默认的模板名为 default。


ods rtf
储存一个RTF文件。
ODS RTF FILE='filename.rtf' options;
ods rtf close;
一些选项如下:
- COLUMNS=n 要求一个柱状输出,n 是第几列。
- Bodytitle
- Sasdate 这个选项告诉 SAS 当前的 SAS 会话开始运行时,使用日期和时间。
- Style= 指定一个风格模板
ods printer
宏
SAS 宏代码包括两个基本部分:宏命令和宏变量。
注意:
- 宏变量通常加一个“&”作为前缀,而宏命令通常加一个“%”作为前缀。
- **宏变量有局部宏变量和全局宏变量。**如果在宏的内部定义则为局部宏变量,只能在内部使用。如果在开放代码中定义则为全局宏变量。避免两种错误:在宏之外(开放代码)使用局部变量;创建同名的局部变量和全局变量。
- 使用宏指令之前必须将宏系统选项打开,尽管有时默认是打开的。可以用下面代码查看是否打开: PROC OPTIONS OPTION=MACRO; RUN; 查看日志,如果看到 MACRO,则打开了;如果看到 NOMACRO,则没有打开。
- 宏会让人很头痛,可以通过分段形式避免。首先,用 SAS 标准语言写下程序;接着,将其转变为宏代码。
- 除非开头和结尾的空格,否则从等号到分号的全部内容都是变量值。
- 使用宏变量宏变量前面要加前缀&,注意宏处理器找不到单引号内的宏变量,只能用双引号。
%let创建一个宏变量
%LET macro-variable-name=value;
%Macro创建模块化代码
%MACRO macro-name(parameter-1=,parameter-2=,...parameter-n=);
macro-text
%MEND (macro-name);
%MACRO 语句告诉 SAS 这是宏开始,而%MEND 则意味着结束。
定义了宏之后,可以通过在宏名称前面增加%来启动宏:%macro-name,注意这里可以不用分号。
将宏作为文件储存在某路径中,或作为分区数据集中的一员。使用 MAUTOSOURCE 和 SASAUTOS=系统选项告诉 SAS 在哪里查找宏。
宏的条件逻辑
%IF condition %THEN action;
%ELSE %IF condition %THEN action;
%ELSE action;
%IF condition %THEN %DO; SAS statements
%END;
call symput数据驱动
IF Age>=18 THEN CALL SYMPUT(”status”,”Adult”);
ELSE CALL SYMPUT(”status”,”Minor”);
这个语句创建了宏变量&STATUS,并依据年龄情况分配给值adult 或 minor。
用 call symput 创建的宏变量与赋值变量不能够用在同一个数据步中。因为直到数据步执行之后,SAS 才会将一个值赋给宏变量。
排除宏错误的bug
尽可能先用标准 SAS 代码写你的程序,当没有错误了,再转成宏代码,先一次增加一个宏逻辑特征。再增加%macro 和%mend。再增加宏变量。
| bug | 报错情况 | 出现信息 | 解决方案 |
|---|---|---|---|
| merror\nomerror | 如果 SAS 不能找到一个宏,并且 Merror 选项也是开着的 | WARNING:Apparent invocation of macro SAMPL not resolved. | 确认宏名字的拼写是否正确。 |
| serror\noserror | 不能在开放代码中处理一个宏变量,并且 serror 选项是开着的 | WARNING:Apparent symbolic reference FLOWER not resolved. | 首先确认是否拼写错误,再次查看视角,即是否在外部使用了一个局部变量。 |
| mlogic\nomolgic | SAS 会在日志里打印关于执行宏的详细信息。 | ||
| mprint\nomprint | SAS 在日志里打印由宏产生的标准 SAS 代码。 | ||
| symbolgen\nosymbolgen | SAS 在日志里打印宏变量的值。 |
?反正我还没看懂等会儿再看吧
- Run 告诉 SAS 去执行所有之前的程序行,全局变量不是 DATA 或 PROC 过程的部分。
- @的作用类似于@@,都是行停留指示符(line-hold specifiers),不同地方在于停留多久,@能使 SAS 停留到下一个 input 语句(也不换行),@@能使停留的时间到下一个 data 步(也不换行)。
- 比如,读取一个制表符为分隔符、并且用两个制表符代表缺失值的数据文件,则要用下面的语句: INFILE ’file-specification’ DLM=’09’X DSD; (是不是错了?)
- 2.18 用 DDE 读取 PC 文件
- SAS里informat和format的区别????
- SAS读取时间(第62页)
- 可以通过在 tile、footnote 后面加上数字来添加多个标题和脚注,
FOOTNOTE3’This is the third footnote’; 但是小数字的标题会代替大数字的标题,如 title2 会代替 title3。 ??? - data步里put干啥用的?
- proc tabluate的顶部格式改变没看完
- proc report的define语句
- 合并total和原始数据。
不太重要但是也许会用到的知识谁说的好呢
-
如果不幸你的程序出现了问题,你需要再次运行,对于程序编辑窗口,由于之前的程序不在保留,因此需要调回命令(recall)。
-
最基本的 title 语句为:title ‘标题’,双引号、单引号皆可,比如: TITLE’This is a title’;
如果标题中带有撇号,则需用双引号,或者将撇号换为双撇号:
TITLE”Here’s another title”; TITLE’Here’’s another title’;
可能要整理一下的专题没有自动标签功能真的很头疼
- 导入文件
- 处理时间
- 基本统计过程