一个简单的python视频网站爬虫
一个爬取低端影视的视频的python爬虫
网站有反爬,同一个IP解析(看)十来个视频,就会封IP一段时间(大约20~30分钟),但是这样也会误伤正常用户,估计就是这样的原因导致网站不稳定
o(一︿一+)o
首次打开网站会有重定向(可能是反爬机制),跳转后拿到cookie就可以避免这样的情况
还有就是网站没有搜索功能(现有的搜索就是个摆设)o( * ≧ ▽ ≦ )ツ┏━┓
于是乎我就个弄了个爬虫爬取并解析该站的视频及字幕(字幕是ttv格式的)
并写入EXCEL表格,这样就可以使用搜索功能了♪(^∇ ^*)
(* ̄(エ) ̄) 额!
字幕
我好像忽略了什么,没错这个网站的视频是用的单独字幕文件,我只能说666,
但是这也导致解析出来的视频是不带字幕的,得单独下字幕(ー`´ー),事到如今
只能硬着头皮写下去了┑( ̄Д  ̄)┍
经过我的不屑努力下,与bug大战3000回合后, (~ ̄▽ ̄)~ 终于写出了这个满是BUG的简陋爬虫
主要功能:
1. 解析网站的相关数据,并保存到excel中
2. 及时保存进度 和 自动加载进度(应对网站反爬 和 中断恢复)
3. 没有代理池,因为贫穷 ε(┬┬﹏┬┬)3,没钱买代理IP(免费的太不稳定)
4. 可以使用移动数据流量(动态IP),开关一次飞行模式就可以切换IP
5. 最后附送一个可以播放字幕的网页播放器
6. 爬取到的视频有时效性
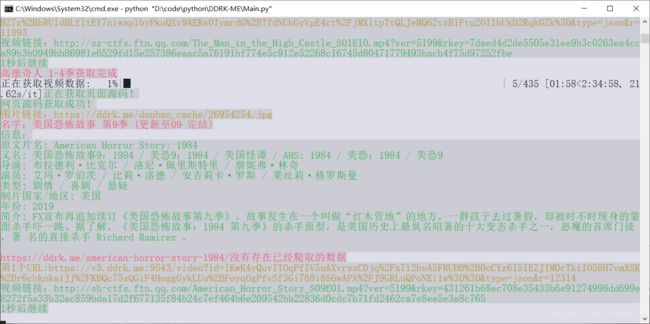
7. 懒得打字功能见下图
最后求大佬手下留情 o((⊙﹏⊙))o.
声明:本爬虫仅作学习交流使用,如有侵犯您的版权,请联系我,我将及时删除。
import requests
import re
from bs4 import BeautifulSoup
import json
from tqdm import tqdm
import xlsxwriter
from io import BytesIO
import os
from PIL import Image
import time
from concurrent.futures import ThreadPoolExecutor,as_completed
from random import random,choice
cookie = "cookie: UM_distinctid=16f60e842f9a5c-024a74b1d84167-6701b35-144000-16f60e842fabf6; __cfduid=d1050c133ed940960769540f771f0b14b1580137083; PHPSESSID=s923ec1n6sjh4r8uhbi3b2q2ue; Hm_lvt_c0036bade482e260625fa4191d0925ad=1580110480,1580113887,1580115372,1580142689; cf_clearance=c910a4b1db39641f3b09cb716e92a33c0aa649df-1580176212-0-150; CNZZDATA1278527985=1654260571-1577876271-%7C1580173180; Hm_lpvt_c0036bade482e260625fa4191d0925ad=1580176501"
def get_video_info(page_source):
"""
获取当前页面相关信息
:param page_source: 页面源代码
:return: 相关信息字典
"""
data = {}
BS = BeautifulSoup(page_source,'lxml')
try:
id = BS.find('script',class_ = "wp-playlist-script")
data['id'] = re.findall('src"\:"(.*?)","src2"', id.text)
except:
data['id'] = []
Red("没有获取到视频ID!")
zimuOss = "https://ddrk.oss-cn-shanghai.aliyuncs.com" #字幕服务器
try:
data['vtt'] = [zimuOss+i.replace("mp4","vtt").replace('\\','') for i in re.findall('src3"\:"(.*?)","src4"', id.text)]
except:
data['vtt'] = []
Red("没有相关字幕!")
try:
data['name'] = BS.find("h1",class_ = "post-title").text
except:
data['name'] = "名称获取出错!"
Red(data['name'])
try:
data['img_url'] =BS.find('div',class_ = 'post').img.attrs['src']
except:
data['img_url'] = "https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1580210659900&di=b6924c163ddb0467e447c12cb98f0acd&imgtype=0&src=http%3A%2F%2F5b0988e595225.cdn.sohucs.com%2Fimages%2F20180828%2F43bbc000b5ff4222b7e83aff69410805.jpeg"
Red("没有获取到封面信息")
try:
text = str(BS.find('div', class_="abstract"))
text = text.replace('', "").replace("", "").replace("", "")
text = text.split("
")
messge = ""
for i in text:
messge += i + '\n'
data['mssage'] = messge
except:
Red("没有获取到相关描述!")
data['mssage'] = []
return data
def Get_User_Agent():
"""
随机User—Agent
:return:
"""
user_agent=[
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB7.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E) QQBrowser/6.9.11079.201',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)',
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
]
return choice(user_agent)
def GET(url,error_message="",timeout=None,referer = None,get_img=False):
"""
使用GET请求,获取url网页数据
:param url: 视频页面地址
:return: 返回二进制数据
"""
header = {}
header[ "User-Agent"] = Get_User_Agent()
if(referer!=None):
header['referer'] = referer
else:
header["cookie"] = cookie
do_while = True
data = None
while(do_while):
try:
data = requests.get(url,headers = header,timeout=timeout)
except:
Red(error_message+"请求异常:" + url)
Red("正在重试!")
if (data==None or data.status_code != 200):
continue
else:
do_while = False
if(get_img):
return {url:data.content}
else:
return data.content
def get_video_info_url(index):
"""
解析每个视频的播放页面
:param index: 首页地址
:return: 视频地址列表
"""
Pool = ThreadPoolExecutor(max_workers = 3)
page_source = GET(index).decode('utf-8')
page_sum = int(BeautifulSoup(page_source,'lxml').find_all('a',class_="page-numbers")[-2].text)
task = [Pool.submit(GET,((index+"/page/"+str(i)))) for i in range(1,page_sum+1)]
T = tqdm(total=len(task),desc="正在获取视频页面")
video_url_list = []
for i in tqdm(as_completed(task)):
page_source = i.result().decode('utf-8')
video_url = [i.attrs['href'] for i in BeautifulSoup(page_source, 'lxml').find_all('a', rel='bookmark')]
video_url_list+=video_url
T.update(1)
T.close()
return video_url_list
def get_video_data(url,Data,successs_wait=30,fail_wait=60,get_video = True):
"""
获取视频相关信息(单线程操作,保证数据的正确性完整,以及对抗反爬虫)
包含及时的数据保存功能
:param url: 视频地址
:return: 视频的相关信息
:param data: 数据
:param successs_wait:当成功获取视频url时等待的时间
:param fail_wait: 当未成功获取视频url时等待的时间
:param get_video:是否解析视频
"""
videoServer = "https://v3.ddrk.me" #视频服务器链接解析
Green("正在获取页面源码!")
page_source = GET(url, error_message="下载网页源码",timeout=None).decode('utf-8')
Green("网页源码获取成功!")
data = get_video_info(page_source)
img_url = data['img_url']
Yellow("图片链接:"+img_url)
Red("名字:"+data['name'])
Green("信息:\n"+data["mssage"])
data['video_list'] = []
ep = 0
pass_id_len = 0
try:
pass_id_len = len(Data[url]['id'])
except:
Red("{0}没有存在已经爬取的数据".format(url))
for vtracksrc in data['id']:
ep+=1
if(ep<=pass_id_len):
continue
if(get_video):
pass
else:
Red("跳过视频解析!")
data['video_list']=[]
try:
del Data[url]
except:pass
Data[url] = data
break
do_while = True
while(do_while):
r = str(int(random() * 100000))
URL = videoServer + ':' + '9543' + '/video?id=' + vtracksrc + '&type=json' + '&r=' + r
Yellow("第{0}个URL:".format(ep) + URL)
video_resopens = json.loads(GET(URL, error_message="获取视频地址", referer=(url+"?ep="+str(ep))).decode('utf-8'))
try:
Green("视频链接:" + video_resopens['url'])
data['video_list'].append(video_resopens['url'])
try:
del Data[url]
except:
pass
Data[url] = data
data_save(Data)
do_while = False
Green("{0}秒后继续".format(successs_wait))
time.sleep(successs_wait)
except:
try:
if(video_resopens['err']=="error1"):
Red("触发网站反爬虫机制!请切换IP\n {0}秒后重试!".format(fail_wait))
time.sleep(fail_wait)
else:
Red("服务器故障!")
data['video_list'].append("服务器故障!")
do_while = False
except:
Red("未知错误:{0}".format(video_resopens))
Red(data['name']+"获取完成")
def save_process(video_url_list):
"""
存储进度
:param video_url_list: 进度数据
:return:
"""
try:
with open("进度",'w',encoding="utf-8") as f:
f.write(json.dumps(video_url_list))
except:
Red("进度存储异常")
def load_process():
"""
加载进度
:return:
"""
video_url_list = None
try:
with open("进度",'r',encoding="utf-8") as f:
video_url_list = json.loads(f.read())
except:
pass
return video_url_list
def data_save(data):
"""
储存数据
:param data: 数据字典
:return:
"""
try:
with open("低端影视.json",'w',encoding='utf-8') as f:
f.write(json.dumps(data))
except:
Red("数据储存失败")
def data_load():
"""
加载数据
:return:
"""
data = None
try:
with open("低端影视.json",'r',encoding='utf-8') as f:
data = json.loads(f.read())
except:
pass
return data
def easy_print(message,data):
if (data != None):
Green(message+"成功!")
else:
Red(message+"失败!")
def get_data_process(video_url_list,data,get_video = True):
T = tqdm(desc="正在获取视频数据",total=len(video_url_list))
while(video_url_list!=[]):
save_process(video_url_list)
url = video_url_list[0]
get_video_data(url,data,successs_wait=1,fail_wait=10,get_video = get_video)
del video_url_list[0]
T.update(1)
T.close()
def Show_tqdm(Q):
"""
进度显示(给定任务队列,根据队列剩余长度显示进度)(阻塞态)
:param Q: 指定的队列
:return: None
"""
num1 = Q.qsize()
with tqdm.tqdm(total=num1) as T:
size = Q.qsize()
while Q.empty()==False:
q = Q.qsize()
if(size!=q):
T.update(-q+size)
size = q
T.update(size)
def Get_Image(data,max_workers = 5):
"""
多线程下载图片(返回队列,包含以url为key的字典)
:return:返回以url的数据字典
:param data: 数据文件
:param max_workers: 线程数量
"""
Pool = ThreadPoolExecutor(max_workers=max_workers)
task = []
for i in data.keys():
task.append(Pool.submit(GI,(data[i]['img_url'])))
T = tqdm(total=len(data),desc="正在下载图片")
img_data = {}
for i in as_completed(task):
img_data.update(i.result())
T.update(1)
T.close()
return img_data
def GI(url):
"""
Get_Image的线程函数
:param url: 图片url
:return: 以url为key的字典
"""
do_while = True
header = {}
respones = None
header['User-Agent'] = Get_User_Agent()
while(do_while):
try:
respones = requests.get(url,headers = header,timeout=(5,5))
if(respones.status_code==200):
do_while = False
respones = respones.content
except:
Red("链接超时,正在重试:{0}".format(url))
return {url:BytesIO(respones)}
def CLear():
"""
简单的清屏函数
:return:
"""
if (os.name == 'nt'):
os.system('cls')
else:
os.system('clear')
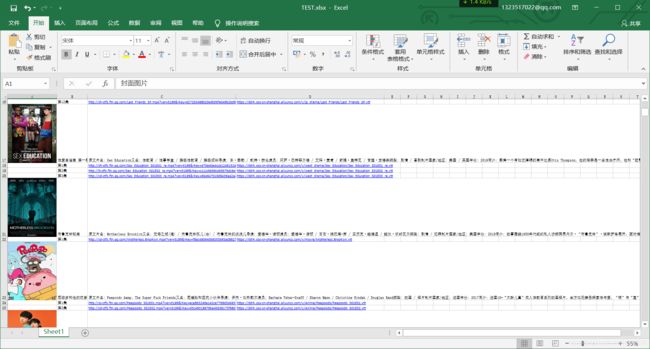
def Save_to_excel(data,path,image_width=20,image_higth=139):
"""
将获取到的数据写入xlse表格
:param data:
:param path: excel表格储存位置(需包含完整的文件路径如:C:/A.xlsx)
:param image_width: 经验参数
:param image_higth: 经验参数
:return:
"""
resize_x = 265
resize_y = 214
image_data = Get_Image(data)
workbook = xlsxwriter.Workbook(path)
sheet = workbook.add_worksheet()
row = 0
# 定义粗体字体
bold = workbook.add_format({'bold': True})
sheet.write(row, 0, '封面图片', bold)
sheet.write(row, 1, '名称/集数', bold)
sheet.write(row, 2, '描述/视频地址', bold)
sheet.write(row, 3, '字幕链接', bold)
sheet.set_column('A:A', image_width + 6)
sheet.set_column('B:B', 16)
sheet.set_column('C:C', 80)
sheet.set_column('D:D', 80)
for i in tqdm(data.keys(),desc="正在写入EXCEL"):
row += 1
message = data[i]['mssage']
image_url = data[i]['img_url']
name = data[i]['name']
sheet.write(row, 1, name)
im = None
try:
im = Image.open(image_data[image_url])
except:
with open('1.jpg', 'wb') as f:
f.write(image_data[image_url])
im = Image.open(BytesIO(requests.get('https://ss3.bdstatic.com/70cFv8Sh_Q1YnxGkpoWK1HF6hhy/it/u=137921156,3197104189&fm=26&gp=0.jpg').content))
input(image_url,"错误")
"""图像尺寸"""
x_size = im.size[0]
y_size = im.size[1]
"""获取缩放"""
if( x_size<=resize_x and y_size<=resize_y):
pass
else:
try:
im = im.resize((resize_x, resize_y), Image.ANTIALIAS)
file_name = '1.jpg'
try:
im.save(file_name)
except:
file_name='1.png'
im.save(file_name)
f = open(file_name, 'rb')
image_data[image_url] = BytesIO(f.read())
f.close()
x_size = im.size[0]
y_size = im.size[1]
except:pass
x = (image_width * 9 + 7) / x_size
y = image_higth / 3 * 5 / y_size
sheet.set_row(row, image_higth + 33)
sheet.insert_image(row, 0, image_url, {'url':i,'image_data': image_data[image_url], 'x_scale': x, 'y_scale': y})
sheet.write(row, 1, name)
sheet.write(row, 2, message)
sheet.write(row, 3, "")
for I in range(len(data[i]['video_list'])):
row+=1
video_url = ""
vtt_url = ""
video_url = data[i]['video_list'][I]
if(I<len(data[i]['vtt'])):
vtt_url = data[i]['vtt'][I]
sheet.write(row, 1, "第{0}集".format(I+1))
sheet.write(row, 2, video_url)
sheet.write(row, 3, vtt_url)
try:
os.remove("1.jpg")
except:pass
try:
os.remove("1.png")
except:pass
workbook.close()
if (os.name == 'nt'):
os.system('cls')
else:
os.system('clear')
print("\033[1;36m表格写入完成!\033[0m")
def GET_DATA(get_video = True):
"""
获取网站数据
:return:
"""
data = data_load()
easy_print("数据加载",data)
video_url_list = load_process()
easy_print("加载进度",video_url_list)
if(data==None):
data = {}
if(video_url_list==None):
video_url_list = get_video_info_url('https://ddrk.me/')
get_data_process(video_url_list,data,get_video=get_video)
def Red(text, T=True):
"""红字
:param text:
:param T: 是否换行
:return:
"""
if (T):
print("\033[1;31m{0}\033[0m".format(text))
else:
print("\033[1;31m{0}\033[0m".format(text), end="")
def Yellow(text, T=True):
"""黄字
:param text:
:param T: 是否换行
:return:
"""
if (T):
print("\033[1;33m{0}\033[0m".format(text))
else:
print("\033[1;33m{0}\033[0m".format(text), end="")
def Green(text, T=True):
"""绿字
:param text:
:param T: 是否换行
:return:
"""
if (T):
print("\033[1;32m{0}\033[0m".format(text))
else:
print("\033[1;32m{0}\033[0m".format(text), end="")
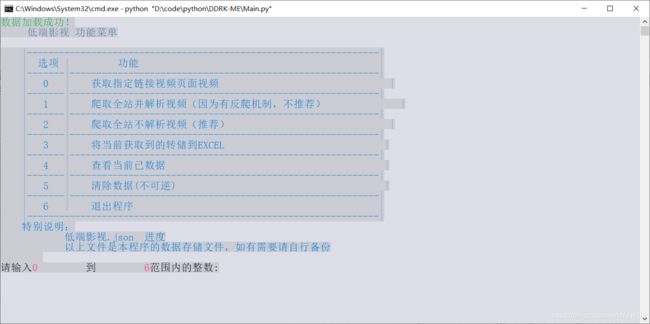
def Menu():
F = """
|------------------------------------------------------------------|
| 选项 | 功能 |
|-------|----------------------------------------------------------|
| 0 | 获取指定链接视频页面视频 |
|-------|----------------------------------------------------------|
| 1 | 爬取全站并解析视频(因为有反爬机制,不推荐) |
|-------|----------------------------------------------------------|
| 2 | 爬取全站不解析视频(推荐) |
|-------|----------------------------------------------------------|
| 3 | 将当前获取到的转储到EXCEL |
|-------|----------------------------------------------------------|
| 4 | 查看当前已数据 |
|-------|----------------------------------------------------------|
| 5 | 清除数据(不可逆) |
|-------|----------------------------------------------------------|
| 6 | 退出程序 |
|------------------------------------------------------------------|
特别说明:
低端影视.json 进度
以上文件是本程序的数据存储文件,如有需要请自行备份
"""
print("\033[1;36m 低端影视 功能菜单\033[0m")
print('\033[1;34m{0}\033[0m'.format(F))
def Get_number(Min,Max,F = False):
"""
:param Min:最小值
:param Max: 最大值
:param F: 是否显示菜单
:return:
"""
while True:
try:
if(F):
Menu()
print("\033[1m请输入\033[1;31m{0:<10}\033[0m\033[1m到\033[1;31m{1:>10}\033[0m\033[1m范围内的整数:\033[0m".format(Min,Max),end='')
number = eval(input())
if(F):
if (os.name == 'nt'):
os.system('cls')
else:
os.system('clear')
if(type(number)!=int):
print("\033[1;31m警告,请输入整数\033[0m")
continue
if(number>Max and True):
print("\033[1;31m输入的数值超限\033[0m")
elif(number<Min):
print("\033[1;31m输入的数值过小\033[0m")
else:
if (F):
if (os.name == 'nt'):
os.system('cls')
else:
os.system('clear')
return int(number)
except:
if (F):
if (os.name == 'nt'):
os.system('cls')
else:
os.system('clear')
print("\033[1;31m输入的数值包含非法字符\033[0m")
def View_data(data):
try:
for url in data.keys():
Red("名称:{0}\t共{1}集\t已爬取到集数:共{2}集".format(data[url]['name'],len(data[url]['id']),len(data[url]['video_list'])))
Green(url+"\n")
except:
Red("数据异常!")
input("回车退出!")
def Main():
"""
主函数
:return:
"""
data = data_load()
easy_print("数据加载", data)
runing = True
while(runing):
Choice = Get_number(0,6,True)
if(Choice == 0):
video_url_list = []
add = True
while(add):
Green("输入url(回车结束输入):")
url = input()
video_url_list.append(url)
Green("正在获取数据!")
get_data_process(video_url_list,data)
if (Choice == 1):
GET_DATA()
if (Choice == 2):
GET_DATA(get_video=False)
if (Choice == 3):
Save_to_excel(data, "低端影视.xlsx")
if (Choice == 4):
View_data(data)
if (Choice == 5):
data = {}
data_save(data)
Green('清除完成!')
if (Choice == 6):
runing = False
Main()
VTT字幕播放器 (只适了配手机)
<html>
<head>
<meta charset="utf-8">
<title>网页播放器title>
<style>
*{
margin: 0px;
padding: 0px;
}
#player {
background-color: lightsteelblue;
height: 50%;
width: 100%;
margin-bottom: 20px;
}
.input_box {
font-size: 30px;
margin-bottom: 10px;
}
.message{
line-height: 30px;
height: 60px;
width: 100%;
background-color: beige;
font-size: 40px;
color: skyblue;
}
#play{
height: 50px;
width: 100px;
font-size: 30px;
position: relative;
left: 50%;
margin-left: -50px;
}
style>
head>
<body>
<div class="video_box">
<video id="player" src="" preload="none" controls="controls">
<track id="ttv" src="" srclang="zh" kind="subtitles" default>
video>
div>
<div class="input_div">
<div class="input_box">播放地址:div>
<div class="input_box">字幕链接:div>
<div> <input id="play" type="button" value="播放" />div>
div>
body>
<script>
var play = document.getElementById("play");
var vtt_url = document.getElementById("vtt_url");
var video_url = document.getElementById("video_url");
var player = document.getElementById("player");
var ttv = document.getElementById('ttv');
play.onclick = function()
{
player.src = video_url.value;
ttv.src = vtt_url.value;
console.log(player.src);
console.log(ttv.src);
alert("请点击上方的视频窗口的播放按钮\n请使用chrome浏览器,否则无法加载字幕。")
}
script>
html>