简介
大数据是一个概念也是一门技术
其技术指在以hadoop为代表的平台框架上进行数据分析的技术。包括实时数据处理、离线数据处理、数据分析、数据挖掘和用机器学习方法进行预测分析等技术
hadoop是一个开源大数据框架,是一个分布式计算的解决方案。
hadoop早期两大核心,HDFS和MapReduce
HDFS(分布式文件系统):存储是大数据技术的基础。
MapReduce(编程模型):分布式计算是大数据应用的解决方案。
HDFS
三个主要概念:
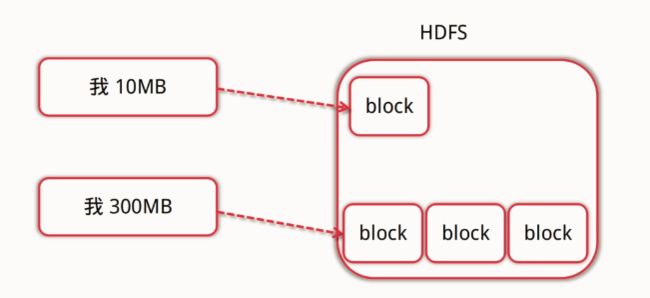
- 数据块:
数据块是HDFS上的抽象数据概念,在HDFS上我们将文件切分成为一个个数据块进行存储。在hadoop中默认的块大小:1.x中为64M,2.x中为128M。
NameNode:
管理文件系统的命名空间,存放数据元数据(描述数据的数据)。维护着文件系统的所有文件和目录,文件与数据块的映射等。记录每个文件各个数据块的所在数据结点的信息。DataNode:
存储并检索数据块,想NameNode更新所存储块的列表。
优点
适合大文件的存储和访问,有副本策略来保证高可靠性。
构建在大规模廉价的机器上,有高扩展性。
支持流式存储,以此写入多次读取。
缺点
不适合多个小文件的存储。
不适合并发写入,不支持随机修改。
不支持随机读等低延时的访问方式。
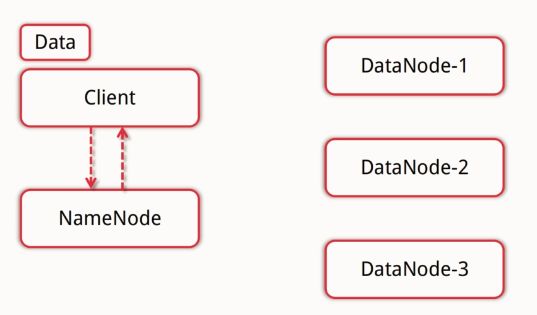
HDFS写流程:
客户端向NameNode发出写数据请求,NameNode反馈可用的DataNode节点。
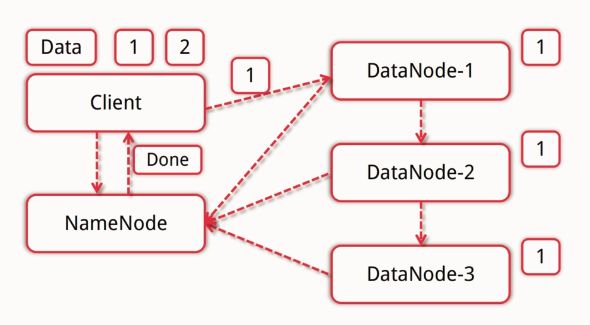
客户端将数据分块,然后根据反馈内容找到可用的数据结点,将分块后的数据依次存入DataNode中,DataNode会自动完成备份工作。
DataNode向NameNode汇报备份完成。NameNode告知客户端写完成。
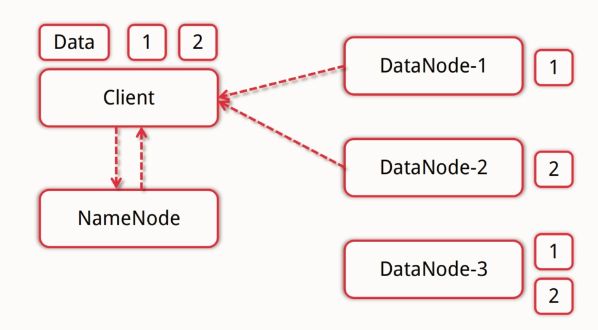
HDFS读流程:
客户端向NameNode发出请求,NameNode通过查看自己维护的信息告知客户端数据块所在DataNode地址。
客户端根据DataNode的远近程度选择DataNode来分块取回所需要的数据。
HDFS常见Shell指令
类Linux系统的:
ls、cat、mkdir、rm、chmod、chown
HDFS文件交互:
copyFromLocal
copyToLocal
get
put
在实际演示以上指令前,确定已有一个hadoop平台并启动了相关的服务:
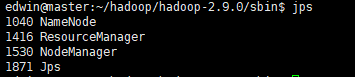
hadoop/bin中有几个主要的可执行文件:

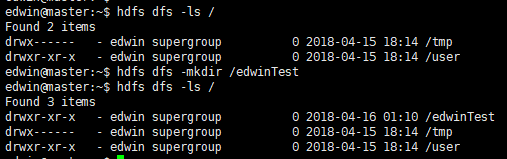
我们使用指令:hdfs dfs -ls / 查看hdfs目录下有哪些文件。
随后使用指令:hdfs dfs -mkdir /edwinTest 创建一个目录。
使用指令:hdfs dfs -copyFromLocal /文件路径 /edwinTest/
将一个本地的文件上传到了hdfs文件系统中

可以使用
指令:hdfs dfs -cat /edwinTest/fanren.txt 将文件输出
指令:hdfs dfs -copyToLocal /edwinTest/fanren.txt /home/edwin/ 将文件拷贝到本地
指令:hdfs dfs -chmod 777 /edwinTest/fanren.txt 修改文件权限

可以使用指令:hdfs dfs -help 随时查看帮助
python操作HDFS
from hdfs3 import HDFileSystem
test_host = '192.168.1.200'
test_port = 9000#default port
def hdfs_exists(client):
path = '/tmp/test'
if client.exists(path):
client.rm(path)
client.makedirs(path)#级联创建
def hdfs_write_read(client):
data = b"hello hadoop" * 10
file_a = '/tmp/test/file_a'
# wb:二进制写入
# relication = 1 :备份数量
with client.open(file_a,'wb',replication = 1) as f:
f.write(data)
with client.open(file_a,'rb') as f:
out = f.read(len(data))
assert out == data
def hdfs_readLine(client):
data = b"hello\nhadoop"
file_b = '/tmp/test/file_b'
with client.open(file_b,'wb',replication = 1) as f:
f.write(data)
with client.open(file_b,'rb') as f:
lines = f.readlines()
assert len(lines) == 2
if __name__ == '__main__':
hdfs_client = HDFileSystem(host=test_host,port=test_port)
hdfs_exists(hdfs_client)
hdfs_write_read(hdfs_client)
hdfs_readLine(hdfs_client)
print("--------------running succeed----------------")
运行结果:
值得一提的是:
from hdfs3 import HDFileSystem
要安装hdfs3这个包需要去官网查看installment文档,推荐使用anaconda的conda指令进行安装,因为其依赖的包比较难装。
同时端口号在配置文件core-site.xml文件中有,
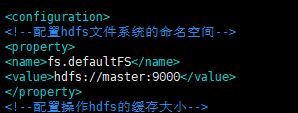
这里给出一些端口的信息
hadoop集群常用端口默认端口号
MapReduce
简介
MapReduce是一种编程模型也是一种编程方法和抽象理论
在2.X中,MapReduce由YARN进行支持。
YARN
负责整个集群的资源管理,有三个主要的概念:
ResourceManager
分配资源
启动和监控ApplicationMaster
监控NodeManagerApplicationMaster
为MapReduce类型的程序分配资源并分配集群内部的资源
负责数据切分
监控任务保证容错NodeManager
管理单个结点的资源
处理ResourceManager和ApplicationMaster的命令
编程模型
输入一个大文件,通过Split分为多个片。
每个文件交由单个机器去处理,这就是Map。
将每个机器的处理结果进行汇总,并得到最终的结果,这就是Reduce。
形如:
from functools import reduce
li = ['aa', 'bbb', 'cccc']
li_count = map(len,li)
countList = list(li_count)
li_sum = reduce(lambda x,y:x+y,countList)
编程实现
- map文件:
import sys
def read_input(file):
for line in file:
yield line.split()
def main():
# file = open("1.txt")
data = read_input(sys.stdin)
for words in data:
for word in words:
print("%s%s%d" % (word,'\t',1))
if __name__ == '__main__':
main()
Reduce文件
import sys
from operator import itemgetter
from itertools import groupby
def read_mapper_output(file,seperator = '\t'):
for line in file:
yield line.rstrip().split(seperator,1)
def main():
data = read_mapper_output(sys.stdin)
for current_word, group in groupby(data,itemgetter(0)):
total_count = sum(int(count) for current_word, count in group)
print("%s%s%d" % (current_word,'\t',total_count))
if __name__ == '__main__':
main()
在运行之前,回忆一下hdfs的操作:
本次mapReduce的文件上传到edwinTest目录下

运行指令:
~/hadoop/hadoop-2.9.0/bin/hadoop jar ~/hadoop/hadoop-2.9.0/share/hadoop/tools/lib/hadoop-streaming-2.9.0.jar -D stream.non.zero.exit.is.failure=false -files "map.py,reduce.py" -input /edwinTest/1.txt -output /edwinTest/wordcountResult -mapper "map.py" -reducer "reduce.py"
指令的一些说明:
-D stream.non.zero.exit.is.failure=false
streaming默认的情况下,mapper和reducer的返回值不是0,被认为异常任务,将被再次执行,默认尝试4次都不是0,整个job都将失败,所以用这条指令来修正。
-input /edwinTest/1.txt -output /edwinTest/wordcountResult
输入输出的位置都必须是hdfs目录下的路径。
运行结果:
出现下图内容说明任务成功

在控制台中可以看到任务结果
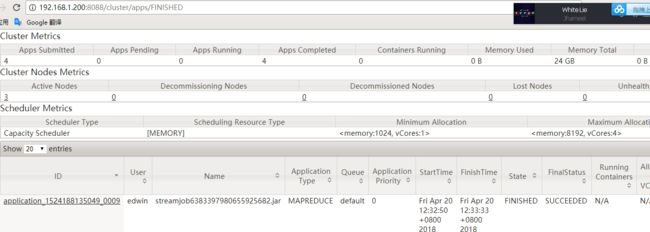
进入hdfs中查看结果:
hdfs dfs -cat /edwinTest/wordcountResult/part-00000
hadoop2.7的目录结构
生态圈内的一些组件
HBase
高可靠、高性能、面向列、可伸缩、实时读写的分布式数据库。
利用HDFS作为其文件系统,支持MR程序读取数据。
支持非结构化、半结构化数据。
主要名词:
RowKey:数据唯一标识,按字典排序
Column Family:列族,多个列的组合,最多不超过3个。
TimeStamp:时间戳,支持多版本的数据同时存在。
下图中cf为列族

spark
基于内存计算的大数据并行计算框架。
Spark是MapReduce的替代方案,兼容HDFS,HIVE等数据源。
抽象出了分布式内存存储数据结构:弹性分布式数据集RDD。
基于事件驱动,通过线程池的复用来提高性能。