windows下pyspark在pycharm的配置
一. 配置jdk
去Oracle官网找到Java SE
https://www.oracle.com/technetwork/java/javase/overview/index.html

找到合适的版本下载
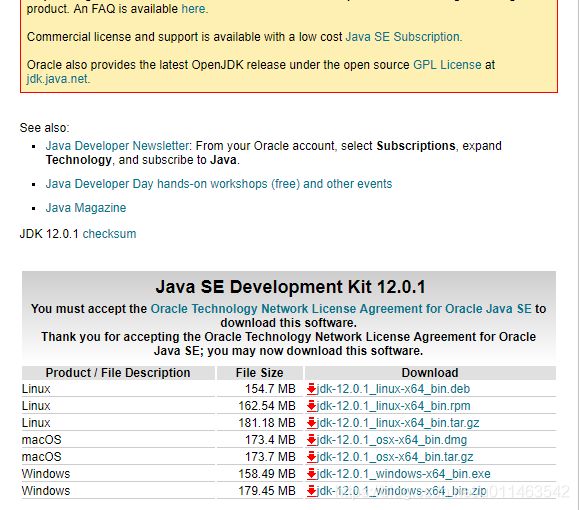
这里选择的是windows .zip压缩文件
注意:全部完成后pycharm编译pyspak脚本时可能出现以下报错:
Re: java.lang.IllegalArgumentException: Unsupported class file major version 55
原因: jdk版本与spark版本不一致
解决方案:安装其他版本的jdk
下载后解压缩,安装,配置环境变量:
win10中选择“查看高级环境设置“->“环境变量”->“系统变量”:
JAVA_HOME 配置的jdk文件位置
在系统变量的path中添加:
%JAVA_HOME%\bin
%JAVA_HOME%\jre\bin
完成后,win+r弹出运行窗口,输入cmd:
弹出命令行窗口:
依次输入java,javac

配置成功
二.安装python
前往官网,下载python
https://www.python.org/
选择Download下载,解压,安装
进入命令行窗口,输入python

安装成功
三.安装scala
安装原因:spark运行需要scala来执行
进入官网 https://www.scala-lang.org/
选择windows下的.zip文件,下载解压安装
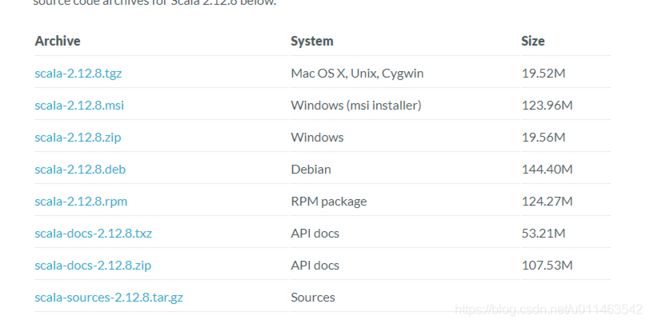
配置环境变量:path中添加 scala安装路径下的bin文件夹的完整路径
进入命令行,输入scala

安装成功
四.安装spark
进入官网 https://spark.apache.org/
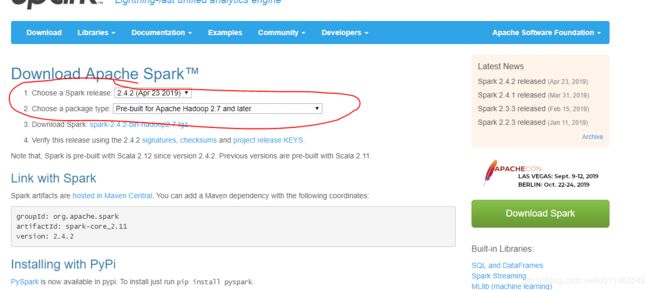
确定版本,依次确定接下来下载的hadoop的版本
下载安装解压
配置环境变量,在path中添加:
安装的spark的bin文件夹路径
安装的spark的sbin文件夹路径
在命令行中输入spark-shell
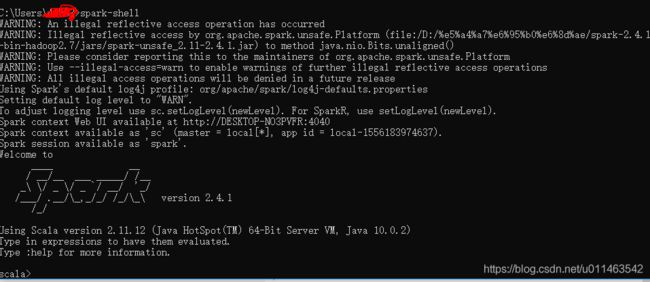
安装成功
注意
错误:可能在输入spark-shell时报错
不是内部或外部命令,也不是可运行的程序 或批处理文件。
解决方案:可能是path中缺环境变量
%SystemRoot%\system32
%SystemRoot%\System32\Wbem
%SystemRoot%
五.安装Hadoop
http://mirror.bit.edu.cn/apache/hadoop/common/
下载与spark对应的版本
解压安装
为了在windows运行,下载winutils
https://github.com/steveloughran/winutils
选择与hadoop对应的版本下载
解压后,将其bin文件夹中的文件放到hadoop安装路径下bin文件夹(没有bin文件夹直接创建)
配置环境变量
HADOOP_HOME Hadoop安装路径
path中添加 %HADOOP_HOME%\bin
六.安装pyspark
命令行下pip install pyspark
安装后 python,输入import pyspark,无输出则成功

七. 配置pycharm
安装pycharm
进入项目界面:菜单run->edit configuration
配置JAVA_HOME,PYTHONPATH,SPARK_HOME
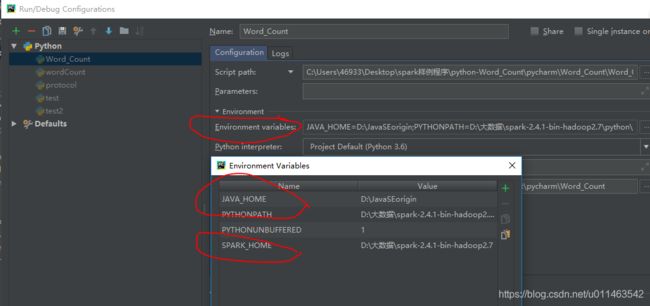
JAVA_HOME= JDK安装路径
PYTHONPATH= spark安装路径下的\python\lib\py4j-0.10.7-src.zip
SPARK_HOME= spark安装路径
运行实例脚本
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
from pyspark import SparkContext
sc = SparkContext('local', 'test')
lines = sc.textFile("test1.txt")
# print(lines.first())
# pythonLines = lines.filter(lambda line: "JDK" in line)
# print(pythonLines.first())
# for line in pythonLines.take(pythonLines.count()):
# print(line)
# lines2 = sc.parallelize(["padas","is ture"])
# print(lines2)
# rdd10 = lines2.flatMap(lambda line: line.split("a"))
# rdd11 = lines2.map(lambda line: line.split("a"))
# print(rdd10.first())
# print(rdd11.first())
# rdd1 = lines.filter(lambda line: "是" in line)
# rdd2 = lines.filter(lambda line: "开发" in line)
# rdd3 = rdd1.union(rdd2)
# print(str(rdd1.count()) + " " + str(rdd2.count()) + " " + str(rdd3.count()))
line3 = sc.parallelize([1,2,3,4])
# rdd4 = line3.map(lambda x: x*x).collect()
# for result in rdd4:
# print("%i" %(result))
# sum = line3.reduce(lambda x, y: x + y)
# print(sum)
sumCount = line3.aggregate((0,0),
(lambda acc, value: (acc[0] + value, acc[1] + 1)),
(lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1])))
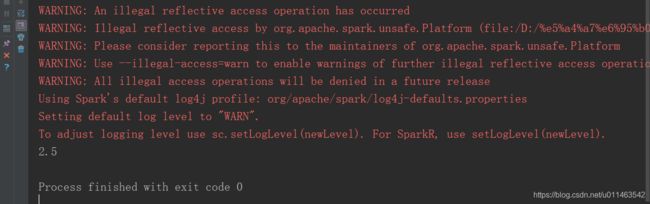
print(sumCount[0]/float(sumCount[1]))
运行结果