爬取360图解电影
原创
目的:使用Scrapy爬取360图解电影,保存至MONGODB数据库,并将图集按电影名称分类保存至本地
目标网址:http://image.so.com/z?ch=video
分析/知识点:
- 爬取难度:
a. 入门级,电影索引页/详情页都是返回json数据结果;
b. 图片分类保存:需要对内置ImagesPipeline进行继承后改写几个方法;
实际步骤:
- 创建Scrapy项目/tujiemovie360(spider)
Terminal: > scrapy startproject tujiemovie360
Terminal: > scrapy genspider tujiemovie image.so.com/z?ch=video
- 配置settings.py文件
# MONGODB配置
MONGO_URI = 'localhost'
MONGO_DB = 'maoyan_movie'
# 图集保存默认路径
IMAGES_STORE = './movies/'
# 不遵守爬取机器人协议
ROBOTSTXT_OBEY = False
# 设置headers
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# 启用ImagePipeline/MongoPipeline
ITEM_PIPELINES = {
'tujiemovie360.pipelines.ImagePipeline': 300,
'tujiemovie360.pipelines.MongoPipeline': 301,
}
- 编写items.py文件
注:此处创建了电影图集索引Item/详情页Item
# 图集IndexItem
class IndexItem(Item):
id = Field() # 电影图集id,重要
actor = Field() # 演员
director = Field() # 导演
group_title = Field() # 电影名称
total_count = Field() # 电影图集图片总数
# 图集DetailItem
class DetailItem(Item):
id = Field() # 电影图集id,重要
imageid = Field() # 图片ID
group_id = Field() # 图集ID
pic_title = Field() # 电影图集名称
pic_url = Field() # 图片url(命名升序, gm_1/gm_2...)
qhimg_url = Field() # 图片url(高清) pic_url对应的是960x540分辨率的图片
- 编写pipelines.py文件
a) MongoPipeline:根据官方例子改写。根据Item中所含字段不同,分别予以处理
# !! 更新MONGODB,使用UPDATE方法,查重功能
def process_item(self, item, spider):
# 保存movie_index信息
if 'group_title' in item.fields:
self.db['movie_index'].update({'id': item['id']}, {'$set': item}, upsert=True)
# 保存movie_detail信息(图集)
elif 'imageid' in item.fields:
self.db['movie_detail'].update({'imageid': item['imageid']}, {'$set': item}, upsert=True)
return item
b) ImagePipeline:
i. 根据获取的图集中每张图片的url(qhimg_url),重新生成Request进行请求下载
# 重写ImagesPipeline类的此方法
# 发送图片下载请求
def get_media_requests(self, item, info):
yield Request(item['qhimg_url'])
ii. 获取文件名(下载时)
# 每张图片文件名(下载时的文件名,后续还要改名)
def file_path(self, request, response=None, info=None):
url = request.url
file_name = url.split('/')[-1]
return file_name
iii. 图片默认下载路径为:IMAGES_STORE/full/;
下载完成后,根据图集名称创建对应文件夹,并将对应图片全部转移至相对应文件夹中,使用内置库shutil.move(src, des)完成此项功能
# 重写item_completed方法
# 将下载的文件保存到不同的目录中
def item_completed(self, results, item, info):
image_path = [x['path'] for ok, x in results if ok]
if not image_path:
raise DropItem('Image Downloaded Failed')
# 定义图集目录保存路径
movie_dir = '%s%s' % (self.img_store, item['pic_title'])
# 目录不存在则创建目录
if not os.path.exists(movie_dir):
os.mkdir(movie_dir)
# 将文件从默认下路路径移动到指定路径下,同时变更文件名(gm_1~X)
shutil.move(self.img_store + image_path[0], movie_dir + '/' + item['pic_url'].split('/')[-1])
return item
- 编写spiders > tujiemovie.py文件
注意:
a) 在解析完索引页(parse_index)后,需要分别生成对具体图集的Request请求。此时需要注意sn的上限值计算(total_count // 60 + 1)
def parse_index(self, response):
'''
解析索引页
'''
...(略)
# 请求每部电影图集详情页
id = movie.get('id')
total_count = movie.get('total_count')
for sn in range(0, total_count // 60 + 1):
yield Request(url=self.detail_url.format(id=id, sn=sn * 60), callback=self.parse_detail,
dont_filter=True)
b) 完整代码如下:
import json
from scrapy import Spider, Request
from tujiemovie360.items import IndexItem, DetailItem
class TujiemovieSpider(Spider):
name = 'tujiemovie'
allowed_domains = ['image.so.com/z?ch=video']
start_urls = ['http://image.so.com/z?ch=video/']
# 索引页
index_url = 'http://image.so.com/zj?ch=video&sn={sn}&listtype=new&temp=1'
# 详情页
detail_url = 'http://image.so.com/zvj?ch=video&id={id}&pn=60&sn={sn}'
# 重写
def start_requests(self):
# 索引页请求
for sn in range(0, 1): # 修改上限值,可以把整个图解电影全爬下来
yield Request(url=self.index_url.format(sn=sn * 30), callback=self.parse_index, dont_filter=True)
def parse_index(self, response):
'''
解析索引页
'''
results = json.loads(response.text)
if 'list' in results.keys():
for movie in results.get('list'):
item = IndexItem()
item['id'] = movie.get('id')
item['group_title'] = movie.get('group_title')
item['total_count'] = movie.get('total_count')
item['actor'] = movie.get('actor')
item['director'] = movie.get('director')
yield item
# 请求每部电影图集详情页
id = movie.get('id')
total_count = movie.get('total_count')
for sn in range(0, total_count // 60 + 1):
yield Request(url=self.detail_url.format(id=id, sn=sn * 60), callback=self.parse_detail,
dont_filter=True)
def parse_detail(self, response):
'''
解析电影图集详情页(每张图片)
'''
results = json.loads(response.text)
if 'list' in results.keys():
for pic in results.get('list'):
item = DetailItem()
item['id'] = pic.get('group_id') # 电影图集id
item['imageid'] = pic.get('imageid')
item['pic_url'] = pic.get('pic_url')
item['pic_title'] = pic.get('pic_title')
item['qhimg_url'] = pic.get('qhimg_url')
yield item
6. 运行结果
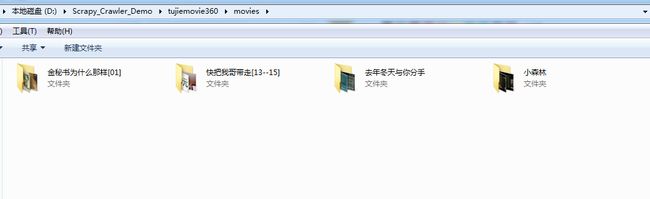
temp-1.png
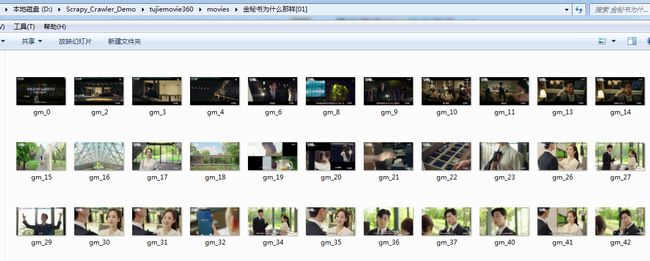
temp-2.png
小结
- 入门级项目,难度略微有所提升;
- 改写Scrapy内置ImagesPipeline,实现对图片的分类保存;
*目前使用的是python内置库shutil/os,图片下载完成后再进行分类整理。但这样做的效率相对较低,需要进一步改进成在下载时就创建对应文件夹并保存。