JavaScript 作用域详解
本文首发于贝壳社区FE专栏,欢迎关注!
一、什么是作用域
编译原理
- 分词/词法分析(Tokenizing/Lexing)
这个过程会将由字符组成的字符串分解成(对编程语言来说)有意义的代码块,这些代 码块被称为词法单元(token)。例如,考虑程序var a = 2;。这段程序通常会被分解成 为下面这些词法单元:var、a、=、2 、;。空格是否会被当作词法单元,取决于空格在 这门语言中是否具有意义。- 解析/语法分析(Parsing)
这个过程是将词法单元流(数组)转换成一个由元素逐级嵌套所组成的代表了程序语法 结构的树。这个树被称为“抽象语法树”(Abstract Syntax Tree,AST)。
var a = 2; 的抽象语法树中可能会有一个叫作 VariableDeclaration 的顶级节点,接下 来是一个叫作 Identifier(它的值是 a)的子节点,以及一个叫作 AssignmentExpression 的子节点。AssignmentExpression 节点有一个叫作 NumericLiteral(它的值是 2)的子 节点。- 代码生成
将 AST 转换为可执行代码的过程称被称为代码生成。这个过程与语言、目标平台等息 息相关。
抛开具体细节,简单来说就是有某种方法可以将 var a = 2; 的 AST 转化为一组机器指 令,用来创建一个叫作 a 的变量(包括分配内存等),并将一个值储存在 a 中。
简而言之:
- 将代码以词为单位拆分成一个个词法单元。
- 解析词法单元转换成 AST 语法树。
- 生成机器指令。
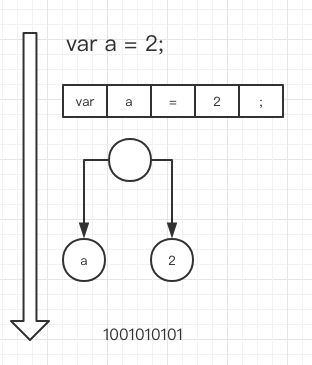
编译过程
整个编译过程有三个角色需要登场:
- 引擎 负责整个 JavaScript 程序的编译及执行过程。
- 编译器 负责语法分析及既期代码生成。
- 作用域 负责收集并维护所有声明的变量组成的一系列查询。
那么整个 var a = 2; 的编译过程如下:
- 编译器拿到
var a = 2;这段代码,进行语法分析。 - 编译器分析到
var a,向作用域进行变量定义操作。- 如果作用域中已有 a 变量,直接通知编译器。
- 如果作用域中没有 a 变量,创建 a 变量并通知编译器。
- 编译器收到通知,继续执行并将
a = 2这段代码编译为及其语言传给引擎。 - 引擎拿到
a = 2向作用域中去查找 a 变量,准备赋值操作。- 如果 a 所在作用域下有 a 变量,作用域直接通知引擎。
- 如果 a 所在作用域下没有 a 变量,则不断向外部作用域查找 a 变量。
- 在外部作用域找到 a 变量,作用域通知引擎。
- 在外部作用域找 a 变量直到全局作用域下也没有找到,作用域通知引擎未找到 a 变量。
- 引擎收到通知
- 如果找到 a 变量,引擎在作用域内对变量 a 赋值。
- 如果没有找到 a 变量,引擎发出
Refence Error错误。
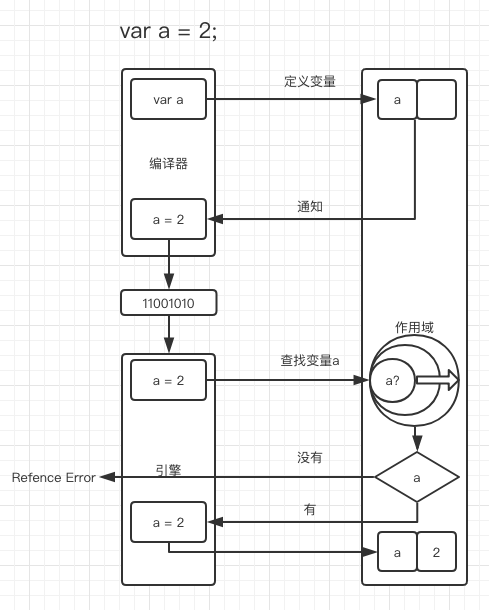
作用域的好处
- 安全性 —— 变量和函数可以定义在最小作用域下。
- 减少命名冲突 —— 作用域帮我们较少命名冲突发生的概率。
- 代码复用性 —— 好的局部作用域可以提升代码的复用性。
二、LHS 与 RHS
定义
我对于 LHS 和 RHS 的理解是:所有赋值操作都是 LHS,如 a = 2;;而所有的取值操作都是 RHS,如 console.log(a);。
当变量出现在赋值操作的左侧时进行 LHS 查询,出现在右侧时进行 RHS 查询。 —— 《你不知道的 JavaScript》
差异
在非严格模式下,当变量 a 未被定义,像 console.log(a) 这样的RHS 查找会报 ReferenceError 的错误,而像 b = 2 这样的 LHS 查找会在全局作用域下创建变量并进行赋值。
console.log(a); // type: RHS, output: ReferenceError
b = 2; // type: LHS, output: 2
而在严格模式下,LHS 和 RHS 的效果是相同的,都会报 ReferenceError。
示例
function foo(a){
console.log(a);
}
foo(2);
在以上例子中有 3 次 RHS 和 1 次 LHS
- RHS
foo(2)查找 foo 函数。 - LHS
foo(2)隐藏着a = 2赋值行为。 - RHS
console.log(a)查找 console 对象 - RHS
console.log(a)查找 a 变量
function foo(a) {
var b = a;
return a + b;
}
var c = foo(2);
找出 3 次 LHS 4 次 RHS。
- RHS:
foo(2)查找 foo 函数。 - LHS:
foo(2)隐藏有a = 2赋值行为。 - LHS:
var c = foo(2)是赋值行为。 - RHS:
var b = a查找 a 变量。 - LHS:
var b = a是赋值行为。 - RHS:
return a + b查找 a 变量。 - RHS:
return a + b查找 b 变量。
三、词法作用域及欺骗词法
词法作用域
词法作用域就是指我们代码词法所表示的作用域。看下如下代码:
function foo(a) {
var b = a * 2;
function bar(c) {
console.log( a, b, c );
}
bar( b * 3 );
}
foo( 2 ); // 2, 4, 12
这段代码的词法作用域如图:

其实就是我们在代码编写时所定义的作用域即词法作用域。
欺骗词法
当然也有不按词法规则来的写法,称为欺骗词法。
eval
类似于 eval() 方法会将字符串解析成 JS 语言的执行。它将破坏词法作用域的规则。如
function foo() {
eval('var a = 3')
console.log(a) // 3
}
var a = 2;
foo();
with
with 这个冷门的关键词通常被当作重复引用同一个对象中的多个属性的快捷方式,可以不需要重复引用对象本身。
var obj = {
a: 1,
b: 2,
c: 3
};
// 单调乏味的重复 "obj"
obj.a = 2;
obj.b = 3;
obj.c = 4;
// 简单的快捷方式
with (obj) {
a = 3;
b = 4;
c = 5;
}
两种赋值方式看似等价。但如果赋值目标是 obj 对象中没有的变量,两种赋值效果是不同的。
var obj = {
a: 1,
b: 2,
c: 3
};
obj.d = 11;
console.log(obj) // { a: 1, b:2, c:3, d: 11 }
console.log(d) // ReferenceError
var obj = {
a: 1,
b: 2,
c: 3
};
with (obj) {
d = 11;
}
console.log(obj) // { a: 1, b:2, c:3 }
console.log(d) // 11
可以看到在 with 函数中的对于变量 d 的赋值行为(LHS)是定义在了 window 对象上的。
四、函数作用域和块作用域
函数作用域
通常情况下,函数内的变量无法在函数外调用。即变量存在于函数作用域下,所以函数作用域起到了局部变量或者变量隐藏的作用。如下例子
var a = 2;
function foo() {
var a = 3;
console.log(a); // 3
}
foo();
console.log(a); // 2
以上写法将 foo 方法中的 a 变量隐藏了起来。不过也产生了一个问题 —— 全局作用域下多了一个 foo 函数变量。解决这种污染的方式是立即执行函数(IIFE),我们将上面的代码进行改造:
var a = 2;
(function foo() {
var a = 3;
console.log(a); // 3
})();
console.log(a); // 2
console.log(foo) // ReferenceError
这种写法就可以将 foo 函数变量也隐藏起来,避免对全局作用域的濡染。
块作用域
定义
块级作用域存在于 if, for, while, {} 等语法中,这些作用域中使用 var 定义的变量是不在这个作用域内的。
块作用域和函数定义域的区别在于:函数定义域隐藏函数内的变量,而块作用域隐藏块中的变量。举个栗子:
// 函数作用域,隐藏变量a
function test() {
var a = 2
}
console.log(a) // ReferenceError
// 块作用域,隐藏变量 i
// 不隐藏变量 a (不是函数作用域)
for (let i = 0; i < 10; i++) {
var a = 2;
}
console.log(i) // ReferenceError
with 与 try/catch
with 和 catch 关键字都会创建块级作用域,因为他们创建的作用域在外部作用域中无效。
var obj = {
a: 1
}
with(obj) {
a = 2
}
console.log(obj) // { a: 2 }
console.log(a) // ReferenceError
try {
undefined(); // 执行一个非法操作来强制制造一个异常
} catch (err) {
console.log(err); // 能够正常执行!
}
console.log(err); // ReferenceError
let 与 const
let 和 const 关键字可以将变量绑定到所在的任意作用域中。换句话说,let 和 const 为其声明的变量隐式地了所在的块作用域。
{
let a = 2;
}
console.log(a) // ReferenceError
可见 const 和 let 能够保证变量隐藏在所在作用域中。
var 与 let 的差异
由于 ES5 只有全局作用域和函数作用域,没有块级作用域,这带来很多不合理的场景。
而 ES6 所提出的 let 和 const 为 JavaScript 带来了块作用域解决了这个问题。
下面列出4点 var 与 let 的差异之处:
- let 不存在变量提升。(var 的变量提升下文有提及)
console.log(foo); // undefined
var foo = 2;
console.log(bar); // ReferenceError
let bar = 2;
- let 在块作用域内定义了变量后不受外部作用域变量影响。
var a = 3
{
console.log(a) // ReferenceError
let a
}
console.log(a) // 3
- 不允许重复申明。
- 最大的不同是在于 let 作用域块作用域,而 var 只作用域函数作用域和全局作用域。
五、变量提升
在使用 var 定义变量和使用 function 定义函数时,会出现变量提升的情况。
编译顺序
看几个例子来理解下变量提升:
var a = 2;
console.log( a );
// JavaScript 的处理逻辑
var a;
a = 2;
console.log(a); // 2
console.log( a );
var a = 2;
// JavaScript 的处理逻辑
var a;
console.log(a); // undefined
a = 2;
foo();
function foo() {
console.log(a); // undefined
var a = 2;
}
// JavaScript 的处理逻辑
function foo() {
var a;
console.log(a); // undefined
a = 2;
}
foo();
**为什么呢?**回忆一下上文说到的编译过程就能理解了。看图!
可以看到编译器会将变量都定义到作用域中,然后再编译代码给引擎去执行代码命令。即 var a = 2; 是被拆开执行的且 var a 变量会提前被定义。
再来看一个不靠谱的函数定义方法:
foo(); // "b"
var a = true;
if (a) {
function foo() {
console.log("a");
}
} else {
function foo() {
console.log("b");
}
}
输出结果与《你不知道的 JavaScript》中的有所不同,在 node v10.5.0 中输出的是 TypeError 而非 b。这个差异有待考证。
函数优先
虽然函数和变量都会提升,但是编译器会先提升函数,再是变量。看如下例子:
foo(); // 1
var foo;
function foo() {
console.log(1);
}
foo = function () {
console.log(2);
};
同时是函数定义,但是第二种是定义变量的形式,所以遵从函数优先原则,以上代码会变为:
function foo() {
console.log(1);
}
var foo; // 无意义
foo(); // 1
foo = function () {
console.log(2);
};
六、闭包
下面是人见人怕的闭包。
定义
当函数可以记住并访问所在的词法作用域时,就产生了闭包。
当函数可以记住并访问所在的词法作用域时,就产生了闭包。
当函数可以记住并访问所在的词法作用域时,就产生了闭包。
重要的定义说三遍!
function foo() {
var a = 2;
function bar() {
return a;
}
return bar;
}
var baz = foo();
console.log(baz()); // 2 <-- 这就是闭包
按照我们对于函数作用域的理解,函数作用域外是无法获取函数作用域内的变量的。
但是通过闭包,函数作用域被持久保存,并且闭包函数可以访问到作用域下的变量。
下面再展示几个闭包便于理解:
var fn;
function foo() {
var a = 2;
function baz() {
console.log(a);
}
fn = baz; // 将 baz 分配给全局变量
}
function bar() {
fn(); // <-- 闭包!
}
foo();
bar(); // 2
function foo() {
var a = 2;
function baz() {
console.log(a); // 2
}
bar(baz);
}
function bar(fn) {
fn(); // <-- 闭包!
}
function wait(message) {
setTimeout(function timer() {
console.log(message);
}, 1000);
}
wait("Hello, closure!");
// timer 持有 wait 函数作用域,所以是闭包。
上面几个例子可以归纳下闭包的特性:
- 闭包必定是函数。
- 函数可以在当前词法作用域外持有并访问词法作用域。
就这么简单!按照这个定义其实所有的回调函数都属于是闭包。
经典的循环面试题解析
for (var i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i);
}, i * 1000);
}
看看以上写法最终输出的是什么呢?由于 var i = 0 是在全局作用域下,且没有任何地方存 i 的变化值,所以最终输出是 5 个 6。
解决方案有两种:
- 使用闭包的持有作用域特性,为每一个 timer 函数封闭一个作用域保存当前的 i。
- 使用 let 块作用域封闭 for 循环中的作用域,保存当前的 i 值。
// 闭包写法
for (var i = 1; i <= 5; i++) {
(function (j) {
setTimeout(function timer() {
console.log(j);
}, j * 1000);
})(i);
}
// 块作用域写法
for (let i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i);
}, i * 1000);
}
参考文档
- 《你不知道的 JavaScript(上)》
- ECMAScript 6 入门
- JavaScript: Learn & Understand Scope
- Everything you wanted to know about JavaScript scope
最后
本文旨在更方便和全面的理解作用域的相关知识,希望能对你有所帮助
JavaScript 的作用域知识不管是在面试中还是在实际工作中都是非常重要的。