Fink

Flink主页在其顶部展示了该项目的理念:“Apache Flink是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
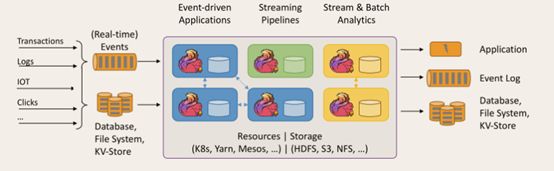
1. Flink的重要特点
① 事件驱动型(Event-driven)
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以kafka为代表的消息队列几乎都是事件驱动型应用。 事件驱动型如下图:
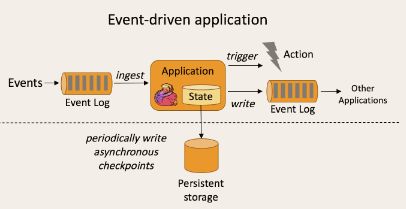
与之不同的就是SparkStreaming微批次如图:

② 分层API

最底层级的抽象仅仅提供了有状态流,它将通过过程函数(Process Function)被嵌入到DataStream API中。底层过程函数(Process Function) 与 DataStream API 相集成,使其可以对某些特定的操作进行底层的抽象,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
大多数应用并不需要上述的底层抽象,而是针对核心API(Core APIs) 进行编程,比如DataStream API(有界或无界流数据)以及DataSet API(有界数据集)。这些API为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)等等。
DataSet API 为有界数据集提供了额外的支持,例如循环与迭代。这些API处理的数据类型以类(classes)的形式由各自的编程语言所表示。
Table API 是以表为中心的声明式编程,其中表可能会动态变化(在表达流数据时)。Table API遵循(扩展的)关系模型:表有二维数据结构(schema)(类似于关系数据库中的表),同时API提供可比较的操作,例如select、project、join、group-by、aggregate等。Table API程序声明式地定义了什么逻辑操作应该执行,而不是准确地确定这些操作代码的看上去如何 。 尽管Table API可以通过多种类型的用户自定义函数(UDF)进行扩展,其仍不如核心API更具表达能力,但是使用起来却更加简洁(代码量更少)。除此之外,Table API程序在执行之前会经过内置优化器进行优化。
你可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
Flink提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与Table API交互密切,同时SQL查询可以直接在Table API定义的表上执行。
③ 流与批的世界观
批处理的特点是有界、持久、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在spark的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。
而在flink的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
无界数据流:无界数据流有一个开始但是没有结束,它们不会在生成时终止并提供数据,必须连续处理无界流,也就是说必须在获取后立即处理event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取event,以便能够推断结果完整性。
有界数据流:有界数据流有明确定义的开始和结束,可以在执行任何计算之前通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
这种以流为世界观的架构,获得的最大好处就是具有极低的延迟。
2. Flink 批处理Api
2.1 Source
Flink+kafka是如何实现exactly-once语义的
Flink通过checkpoint来保存数据是否处理完成的状态;
有JobManager协调各个TaskManager进行checkpoint存储,checkpoint保存在 StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存。
执行过程实际上是一个两段式提交,每个算子执行完成,会进行“预提交”,直到执行完sink操作,会发起“确认提交”,如果执行失败,预提交会放弃掉。
如果宕机需要通过StateBackend进行恢复,只能恢复所有确认提交的操作。
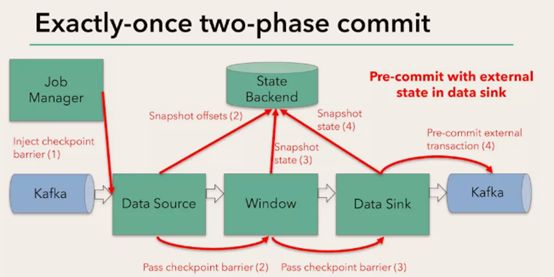
Spark中要想实现有状态的,需要使用updateBykey或者借助redis;
而Fink是把它记录在State Bachend,只要是经过keyBy等处理之后结果会记录在State Bachend(已处理未提交; 如果是处理完了就是已提交状态;),
它还会记录另外一种状态值:keyState,比如keyBy累积的结果;
StateBachend如果不想存储在内存中,也可以存储在fs文件中或者HDFS中; IDEA的工具只支持memory内存式存储,一旦重启就没了;部署到linux中就支持存储在文件中了;
Kakfa的自动提交:“enable.auto.commit”,比如从kafka出来后到sparkStreaming之后,一进来consumer会帮你自动提交,如果在处理过程中,到最后有一个没有写出去(比如写到redis、ES),虽然处理失败了但kafka的偏移量已经发生改变;所以移偏移量的时机很重要;
Transform 转换算子
map
object StartupApp { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val myKafkaConsumer: FlinkKafkaConsumer011[String] = MyKafkaUtil.getConsumer("GMALL_STARTUP") val dstream: DataStream[String] = env.addSource(myKafkaConsumer) //dstream.print().setParallelism(1) 测试从kafka中获得数据是否打通到了flink中 //将json转换成json对象 val startupLogDStream: DataStream[StartupLog] = dstream.map { jsonString => JSON.parseObject(jsonString, classOf[StartupLog]) } //需求一 相同渠道的值进行累加 val sumDStream: DataStream[(String, Int)] = startupLogDStream.map { startuplog => (startuplog.ch, 1) }.keyBy(0)
.reduce { (startuplogCount1, startuplogCount2) => val newCount: Int = startuplogCount1._2 + startuplogCount2._2 (startuplogCount1._1, newCount) } //val sumDStream: DataStream[(String, Int)] = startupLogDStream.map{startuplog => (startuplog.ch,1)}.keyBy(0).sum(1) //sumDStream.print() env.execute() } }
flatMap
Filter
KeyBy
DataStream → KeyedStream:输入必须是Tuple类型,逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同key的元素,在内部以hash的形式实现的。
Reduce
KeyedStream → DataStream:一个分组数据流的聚合操作,合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。
Split 和 Select
Split
DataStream → SplitStream:根据某些特征把一个DataStream拆分成两个或者多个DataStream。
select
SplitStream→DataStream:从一个SplitStream中获取一个或者多个DataStream。
//需求二 把 appstore 和其他的渠道的数据 分成两个流 val splitableStream: SplitStream[StartupLog] = startupLogDStream.split { startuplog => var flagList: List[String] = List() if (startuplog.ch.equals("appstore")) { flagList = List("apple") } else { flagList = List("other") } flagList } val appleStream: DataStream[StartupLog] = splitableStream.select("apple") //appleStream.print("this is apple").setParallelism(1) val otherdStream: DataStream[StartupLog] = splitableStream.select("other") //otherdStream.print("this is other").setParallelism(1)
Connect和 CoMap
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被Connect之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
ConnectedStreams → DataStream:作用于ConnectedStreams上,功能与map和flatMap一样,对ConnectedStreams中的每一个Stream分别进行map和flatMap处理。
//需求三 把上面两个流合并为一个 val connStream: ConnectedStreams[StartupLog, StartupLog] = appleStream.connect(otherdStream) val allDataStream: DataStream[String] = connStream.map((startuplog1: StartupLog) => startuplog1.ch, (startuplog2: StartupLog) => startuplog2.ch) allDataStream.print("all").setParallelism(1)
Union

DataStream → DataStream:对两个或者两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream。注意:如果你将一个DataStream跟它自己做union操作,在新的DataStream中,你将看到每一个元素都出现两次。
//合并流union val unionDStream: DataStream[StartupLog] = appleStream.union(otherdStream) unionDStream.print("union").setParallelism(1)
Connect与 Union 区别:
1 、 Union之前两个流的类型必须是一样,Connect可以不一样,在之后的coMap中再去调整成为一样的。
2 Connect只能操作两个流,Union可以操作多个
2.2 Sink
Flink没有类似于spark中foreach方法,让用户进行迭代的操作。虽有对外的输出操作都要利用Sink完成。最后通过类似如下方式完成整个任务最终输出操作。
myDstream.addSink(new MySink(xxxx))
官方提供了一部分的框架的sink。除此以外,需要用户自定义实现sink。

Kafka
object MyKafkaUtil { val prop = new Properties() prop.setProperty("bootstrap.servers","hadoop101:9092") prop.setProperty("group.id","gmall") def getConsumer(topic:String ):FlinkKafkaConsumer011[String]= { val myKafkaConsumer:FlinkKafkaConsumer011[String] = new FlinkKafkaConsumer011[String](topic, new SimpleStringSchema(), prop) myKafkaConsumer } def getProducer(topic:String):FlinkKafkaProducer011[String]={ new FlinkKafkaProducer011[String]("hadoop101:9092",topic,new SimpleStringSchema()) } } //sink到kafka unionDStream.map(_.toString).addSink(MyKafkaUtil.getProducer("gmall_union")) ///opt/module/kafka/bin/kafka-console-consumer.sh --zookeeper hadoop101:2181 --topic gmall_union
Redis
import org.apache.flink.streaming.connectors.redis.RedisSink import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper} object MyRedisUtil { private val config: FlinkJedisPoolConfig = new FlinkJedisPoolConfig.Builder().setHost("hadoop101").setPort(6379).build() def getRedisSink(): RedisSink[(String, String)] = { new RedisSink[(String, String)](config, new MyRedisMapper) } } class MyRedisMapper extends RedisMapper[(String, String)]{ //用何种命令进行保存 override def getCommandDescription: RedisCommandDescription = { new RedisCommandDescription(RedisCommand.HSET, "channel_sum") //hset类型, apple, 111 } //流中的元素哪部分是value override def getKeyFromData(channel_sum: (String, String)): String = channel_sum._2 //流中的元素哪部分是key override def getValueFromData(channel_sum: (String, String)): String = channel_sum._1 } object StartupApp { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val myKafkaConsumer: FlinkKafkaConsumer011[String] = MyKafkaUtil.getConsumer("GMALL_STARTUP") val dstream: DataStream[String] = env.addSource(myKafkaConsumer) //dstream.print().setParallelism(1) 测试从kafka中获得数据是否打通到了flink中 //将json转换成json对象 val startupLogDStream: DataStream[StartupLog] = dstream.map { jsonString => JSON.parseObject(jsonString, classOf[StartupLog]) } //sink到redis //把按渠道的统计值保存到redis中 hash key: channel_sum field ch value: count //按照不同渠道进行累加 val chCountDStream: DataStream[(String, Int)] = startupLogDStream.map(startuplog => (startuplog.ch, 1)).keyBy(0).sum(1) //把上述结果String, Int转换成String, String类型 val channelDStream: DataStream[(String, String)] = chCountDStream.map(chCount => (chCount._1, chCount._2.toString)) channelDStream.addSink(MyRedisUtil.getRedisSink())
ES
object MyEsUtil { val hostList: util.List[HttpHost] = new util.ArrayList[HttpHost]() hostList.add(new HttpHost("hadoop101", 9200, "http")) hostList.add(new HttpHost("hadoop102", 9200, "http")) hostList.add(new HttpHost("hadoop103", 9200, "http")) def getEsSink(indexName: String): ElasticsearchSink[String] = { //new接口---> 要实现一个方法 val esSinkFunc: ElasticsearchSinkFunction[String] = new ElasticsearchSinkFunction[String] { override def process(element: String, ctx: RuntimeContext, indexer: RequestIndexer): Unit = { val jSONObject: JSONObject = JSON.parseObject(element) val indexRequest: IndexRequest = Requests.indexRequest().index(indexName).`type`("_doc").source(jSONObject) indexer.add(indexRequest) } } val esSinkBuilder = new ElasticsearchSink.Builder[String](hostList, esSinkFunc) esSinkBuilder.setBulkFlushMaxActions(10) val esSink: ElasticsearchSink[String] = esSinkBuilder.build() esSink } } object StartupApp { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val myKafkaConsumer: FlinkKafkaConsumer011[String] = MyKafkaUtil.getConsumer("GMALL_STARTUP") val dstream: DataStream[String] = env.addSource(myKafkaConsumer) //sink之三 保存到ES val esSink: ElasticsearchSink[String] = MyEsUtil.getEsSink("gmall_startup") dstream.addSink(esSink) //dstream来自kafka的数据源 GET gmall_startup/_search
Mysql
class MyjdbcSink(sql: String) extends RichSinkFunction[Array[Any]] { val driver = "com.mysql.jdbc.Driver" val url = "jdbc:mysql://hadoop101:3306/gmall?useSSL=false" val username = "root" val password = "123456" val maxActive = "20" var connection: Connection = null // 创建连接 override def open(parameters: Configuration) { val properties = new Properties() properties.put("driverClassName",driver) properties.put("url",url) properties.put("username",username) properties.put("password",password) properties.put("maxActive",maxActive) val dataSource: DataSource = DruidDataSourceFactory.createDataSource(properties) connection = dataSource.getConnection() } // 把每个Array[Any] 作为数据库表的一行记录进行保存 override def invoke(values: Array[Any]): Unit = { val ps: PreparedStatement = connection.prepareStatement(sql) for (i <- 0 to values.length-1) { ps.setObject(i+1, values(i)) } ps.executeUpdate() } override def close(): Unit = { if (connection != null){ connection.close() } } } object StartupApp { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val myKafkaConsumer: FlinkKafkaConsumer011[String] = MyKafkaUtil.getConsumer("GMALL_STARTUP") val dstream: DataStream[String] = env.addSource(myKafkaConsumer) //dstream.print().setParallelism(1) 测试从kafka中获得数据是否打通到了flink中 //将json转换成json对象 val startupLogDStream: DataStream[StartupLog] = dstream.map { jsonString => JSON.parseObject(jsonString, classOf[StartupLog]) } //sink之四 保存到Mysql中 startupLogDStream.map(startuplog => Array(startuplog.mid, startuplog.uid, startuplog.ch, startuplog.area,startuplog.ts)) .addSink(new MyjdbcSink("insert into fink_startup values(?,?,?,?,?)")) env.execute() } }
Time与Window
在Flink的流式处理中,会涉及到时间的不同概念,如下图所示

Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
Ingestion Time:是数据进入Flink的时间。
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
例如,一条日志进入Flink的时间为2017-11-12 10:00:00.123,到达Window的系统时间为2017-11-12 10:00:01.234,日志的内容如下:
2017-11-02 18:37:15.624 INFO Fail over to rm2
对于业务来说,要统计1min内的故障日志个数,哪个时间是最有意义的?—— eventTime,因为我们要根据日志的生成时间进行统计。
Watermark
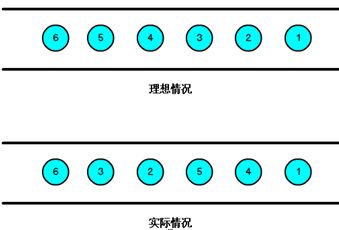
我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。
那么此时出现一个问题,一旦出现乱序,如果只根据eventTime决定window的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了,这个特别的机制,就是Watermark。
Watermark是一种衡量Event Time进展的机制,它是数据本身的一个隐藏属性,数据本身携带着对应的Watermark。
Watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark机制结合window来实现。
数据流中的Watermark用于表示timestamp小于Watermark的数据,都已经到达了,因此,window的执行也是由Watermark触发的。
Watermark可以理解成一个延迟触发机制,我们可以设置Watermark的延时时长t,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定eventTime小于maxEventTime - t的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime – t,那么这个窗口被触发执行。
Window概述
streaming流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而window是一种切割无限数据为有限块进行处理的手段。
Window是无限数据流处理的核心,Window将一个无限的stream拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。
Window可以分成两类:
CountWindow:按照指定的数据条数生成一个Window,与时间无关。
TimeWindow:按照时间生成Window。
TimeWindow
,可以根据窗口实现原理的不同分成三类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)和会话窗口(Session Window)。
- 滚动窗口(Tumbling Windows)
将数据依据固定的窗口长度对数据进行切片。
特点:时间对齐,窗口长度固定,没有重叠。
滚动窗口分配器将每个元素分配到一个指定窗口大小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。例如:如果你指定了一个5分钟大小的滚动窗口,窗口的创建如下图所示:

适用场景:适合做BI统计等(做每个时间段的聚合计算)。
import org.apache.flink.api.java.tuple.Tuple import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment, WindowedStream} import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.api.scala._ object StreamEventTimeApp { def main(args: Array[String]): Unit = { //环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //声明使用eventTime;引入EventTime 从调用时刻开始给env创建的每一个stream追加时间特征 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val dstream: DataStream[String] = env.socketTextStream("hadoop101", 7777) val textWithTsDStream: DataStream[(String, Long, Int)] = dstream.map { text => val arr: Array[String] = text.split(" ") (arr(0), arr(1).toLong, 1) } // 1 告知 flink如何获取数据中的event时间戳 2 告知延迟的watermark val textWithEventTimeDStream: DataStream[(String, Long, Int)] = textWithTsDStream.assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(3000)) { //time别导错包了 override def extractTimestamp(element: (String, Long, Int)): Long = { return element._2 } }).setParallelism(1) //每5秒开一个窗口 统计key的个数 5秒是一个数据的时间戳为准 val textKeyStream: KeyedStream[(String, Long, Int), Tuple] = textWithEventTimeDStream.keyBy(0) textKeyStream.print("textKey: ") //滚动窗口 val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(TumblingEventTimeWindows.of(Time.milliseconds(5000))) windowStream.sum(2).print("windows: ").setParallelism(1) env.execute() } [kris@hadoop101 gmall]$ nc -lk 7777 abc 1000 abc 3000 abc 4000 abc 5000 abc 6000 abc 7999 abc 8000 abc 9999 abc 10000 abc 12000 abc 13000 textKey: :8> (abc,1000,1) textKey: :8> (abc,3000,1) textKey: :8> (abc,4000,1) textKey: :8> (abc,5000,1) textKey: :8> (abc,6000,1) textKey: :8> (abc,7999,1) windows: > (abc,1000,3) textKey: :8> (abc,8000,1) textKey: :8> (abc,9999,1) textKey: :8> (abc,10000,1) textKey: :8> (abc,12000,1) textKey: :8> (abc,13000,1) windows: > (abc,5000,5)
滚动窗口:
X秒开一个窗口
watermark 3s
发车时间看:X+3,车上携带的[X, nX)秒内的
如5s发一次车:[0, 5),发车时间8s、[5, 10)发车时间13s、[10, 15)发车时间18s
- 滑动窗口(Sliding Windows)
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。
特点:时间对齐,窗口长度固定,有重叠。
滑动窗口分配器将元素分配到固定长度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制滑动窗口开始的频率。因此,滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下元素会被分配到多个窗口中。
例如,你有10分钟的窗口和5分钟的滑动,那么每个窗口中5分钟的窗口里包含着上个10分钟产生的数据,如下图所示:

适用场景:对最近一个时间段内的统计(求某接口最近5min的失败率来决定是否要报警)
object StreamEventTimeApp { def main(args: Array[String]): Unit = { //环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //声明使用eventTime env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val dstream: DataStream[String] = env.socketTextStream("hadoop101", 7777) val textWithTsDStream: DataStream[(String, Long, Int)] = dstream.map { text => val arr: Array[String] = text.split(" ") (arr(0), arr(1).toLong, 1) } // 1 告知 flink如何获取数据中的event时间戳 2 告知延迟的watermark val textWithEventTimeDStream: DataStream[(String, Long, Int)] = textWithTsDStream.assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(3000)) { //time别导错包了 override def extractTimestamp(element: (String, Long, Int)): Long = { return element._2 } }).setParallelism(1) //每5秒开一个窗口 统计key的个数 5秒是一个数据的时间戳为准 val textKeyStream: KeyedStream[(String, Long, Int), Tuple] = textWithEventTimeDStream.keyBy(0) textKeyStream.print("textKey: ") //滚动窗口 //val windowDStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(TumblingEventTimeWindows.of(Time.milliseconds(5000))) //滑动窗口 val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(SlidingEventTimeWindows.of(Time.milliseconds(5000L), Time.milliseconds(1000L))) windowStream.sum(2).print("windows: ").setParallelism(1) env.execute() } } [kris@hadoop101 gmall]$ nc -lk 7777 aaa 100 aaa 500 aaa 1000 aaa 3000 aaa 3999 abc 100 abc 1000 abc 3998 abc 3999 abc 5000 abc 8000 abc 10000 textKey: :8> (abc,100,1) textKey: :8> (abc,1000,1) textKey: :8> (abc,3998,1) textKey: :8> (abc,3999,1) //窗口大小0-4999;前面这些都是在4999窗口以下的范围内,但是开车的时机是在步长+watermark=4000,但开车的时候只有100这一个在里边;步长为1 windows: > (abc,100,1) textKey: :8> (abc,5000,1) //开车取决于时间间隔步长1s, 每隔1s发一次;第二次发车是在2s的时候,延迟3s,即5s的时候发车,但这个时候车里就只有100和1000两个; windows: > (abc,100,2) textKey: :8> (abc,8000,1) //一车接5s的人;8000--5000--4000--3000--(这个时候它俩已经开车走了,不要了)-2000-1000 windows: > (abc,100,2) //3000那辆车 windows: > (abc,100,4) //走的是4000那辆车--100、1000、3998、3999 windows: > (abc,100,4)//5000,走的还是100、1000、3998、3999这四个,5000应该是在下一个窗口大小的范围; textKey: :8> (abc,10000,1) //10000-3000 ==> 7000s,到5000是走完第一个窗口大小, 6000走一辆(5999--1000);7000(发车的6999-2000) windows: > (abc,1000,4) //6000: 1000/3998/3999/5000/ windows: > (abc,3998,3) //7000: 3998/3999/5000
- 会话窗口(Session Windows)
由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
特点:时间无对齐。
session窗口分配器通过session活动来对元素进行分组,session窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。一个session窗口通过一个session间隔来配置,这个session间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的session将关闭并且后续的元素将被分配到新的session窗口中去。

object StreamEventTimeApp { def main(args: Array[String]): Unit = { //环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //声明使用eventTime env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val dstream: DataStream[String] = env.socketTextStream("hadoop101", 7777) val textWithTsDStream: DataStream[(String, Long, Int)] = dstream.map { text => val arr: Array[String] = text.split(" ") (arr(0), arr(1).toLong, 1) } // 1 告知 flink如何获取数据中的event时间戳 2 告知延迟的watermark val textWithEventTimeDStream: DataStream[(String, Long, Int)] = textWithTsDStream.assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(3000)) { //time别导错包了 override def extractTimestamp(element: (String, Long, Int)): Long = { return element._2 } }).setParallelism(1) //每5秒开一个窗口 统计key的个数 5秒是一个数据的时间戳为准 val textKeyStream: KeyedStream[(String, Long, Int), Tuple] = textWithEventTimeDStream.keyBy(0) textKeyStream.print("textKey: ") //滚动窗口 //val windowDStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(TumblingEventTimeWindows.of(Time.milliseconds(5000))) //滑动窗口 //val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(SlidingEventTimeWindows.of(Time.milliseconds(5000L), Time.milliseconds(1000L))) //会话窗口 val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(EventTimeSessionWindows.withGap(Time.milliseconds(5000L))) windowStream.sum(2).print("windows: ").setParallelism(1) env.execute() } } 只能两次时间的间隔是否满足条件 在触发水位5s的基础上再加延迟3s, [kris@hadoop101 gmall]$ nc -lk 7777 abc 1000 abc 7000 abc 10000 =======>>> textKey: :8> (abc,1000,1) textKey: :8> (abc,7000,1) textKey: :8> (abc,10000,1) //在上一个基础上+延迟时间3s才会开车 windows: > (abc,1000,1) [kris@hadoop101 gmall]$ nc -lk 7777 aaa 1000 aaa 2000 aaa 7001 aaa 9000 aaa 10000 =====>> textKey: :5> (aaa,1000,1) textKey: :5> (aaa,2000,1) textKey: :5> (aaa,7001,1) //两个时间点之间相差达到鸿沟5s了,在这个基础之上再加3s才能开车; textKey: :5> (aaa,9000,1) textKey: :5> (aaa,10000,1) windows: > (aaa,1000,2)
CountWindow
CountWindow根据窗口中相同key元素的数量来触发执行,执行时只计算元素数量达到窗口大小的key对应的结果。
注意:CountWindow的window_size指的是相同Key的元素的个数,不是输入的所有元素的总数。
滚动窗口
默认的CountWindow是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行。
滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是window_size,一个是sliding_size。
下面代码中的sliding_size设置为了2,也就是说,每收到两个相同key的数据就计算一次,每一次计算的window范围是5个元素。