数仓项目-DATA_Yiee学习笔记(非开源项目,使用内容请联系我)(上)
2019.8.24
技术选型:
- 数据的采集
- Flume:分布式日志数据汇聚
- Sqoop:离线批量抽取数据库
- cannel:实时数据库逐条监听
- 数据的存储
- hdfs
- redis
- hbase/elastic search
- kafka
- mysql
- 数据的运算
- hive
- MR
- Spark core/sql/streaming
- flink
- 算法
- 基本统计算法
- 图计算Spark Graphix
- 机器学习
数仓VS数据库
数据库通常是一个软件,负责业务数据的实时增删改查(OLTP),业务系统的数据库要求实时响应
数据仓库:OLTP的数据在闲时将每天的业务数据导出到另一个数据库(不做OLTP,不连web服务),做一些里显得数据分析(和存储);
所以例如Oracle或者Mysql,既可以用来作业务系统数据库,也可以用来做数据仓库,但是用普通数据库做数仓的瓶颈:存储量小;
这里引入数仓需要满足的两个条件:
- 存储海量数据
- 支持数据分析
普通数据库在第一条上不是最优解,因此Hive更能够更好地充当数据仓库的角色
另一个区别: 业务系统数据库的某条数据是不断变化的,而数仓中的数据是不变化的(通过保存历史记录来体现时间的变化)
数仓的特点:
面向主题的,整合的,相对稳定的,反映历史的
数仓也分两种:
- 离线数仓 -> Hive 这种需要大量时间计算的数仓
- 联机数据分析(OLAP) -> mysql这种可以事实查询分析的数仓
数仓分层:
| 数仓层 | 说明 |
|---|---|
| ADS | 应用服务层(对DW层的数据进一步进行计算,以得到应用层需要的数据) |
| DWS | 数仓汇总层(对明细数据进行 聚合汇总操作,有时也跟DWD层合成一个DW层) |
| DWD | 数仓明细层(分主题,打标签->“是否周末”,补全字段->通过id将desc join进来) |
| ODS | 操作数据层(结构与源数据一致),最底层,也叫贴源层 |
数据采集
流程:
Git
基本概念:协作开发中的代码(版本)管理系统
- 中心存储(团队之间通过这个中心存储来同步代码)
- 有历史版本记录(便于随时回退)
Gitee
- IDEA 安装插件
- 配置gitee账号
- 初始化提交: Share Project on Gitee
- 修改代码后Commit
- Commit后push
2019.8.25
项目工程搭建
父子工程搭建:
- 父工程文件夹右键新建module
- 父工程pom文件里会自动生成子依赖模块
- 子工程pom文件默认生成父依赖模块(parent)
- 父工程pom文件中引入的依赖子工程可以默认使用
子工程间的相互依赖
- 子工程A需要使用同级子工程B中的类,则需要在A中引入B的依赖
- 工程B因为是自己新建的,在Maven仓库中没有,需要使用install命令,将B编译打包,安装到Maven仓库
- 子工程A的pom文件中,导入B的dependency(groupId,version取自父工程,artifactId取自子工程B)
项目技能提升
- 技能1:Self-Join
通过表自己多次join自己,达到顺藤摸瓜级联向上查找父id的目的
参考:自连接
- 技能2:GeoHash编码
引入GeoHash的maven依赖,之后传入经纬度和最后生成的GeoHash字符个数(也就是精度),然后再调用BASE32解码方式,就会得到GeoHashCode
原理:使用二分法将一个经纬度无限接近于精确,二分过程中会将生成的1 和0 (大于和小于某值)追加在原来的字节码后面,字节越多,就越精确,然后将这些1 和0 5个5个分成一组(这里用BASE32方式编码,所以是5个5个一组,如果用BASE64,则是6个6个一组),每组用一个字符表示,生成新的GeoHash码,调用方法时传入的精度,决定了截取多少个长度为5的字节,也就决定了精度。
- 技能3:UDF函数
//导入隐式转换
import org.apache.spark.sql.functions._
//创建一个输入经纬度,得到GeoCode的函数
val gps2geo = (lng:Double,lat:Double)=>
{GeoHash.withCharacterPrecision(lat, lng, 5).toBase32}
//将函数注册道spark sql的引擎中去,并命名
spark.udf.register("gps2geo",gps2geo)
//可以直接在spark sql中使用
spark.sql(
"""
|select
|gps2geo(BD09_LNG,BD09_LAT) as geo,
|from area
""".stripMargin)
- 技能4:Spark 技能夯实
| 数据集 | 说明 |
|---|---|
| RDD | 是一个分布式数据集,处理非结构化数据,一次拿到一行(一般是String类型),再由操作者决定如何处理这一行数据;创建RDD时,本质上是将其他类型的集合映射成rdd集合 |
| DataFrame | 装了(Row)类型的RDD,Row这个类里面,封装了数据的schema,即字段名称和类型和位置 |
// 将一个带有表头的csv文件映射成dataframe
val df1 = spark.read.option("header","true").csv("PATH")
//将一个没有表头的csv文件映射成dataframe并在映射好之后更改字段名
val df2 = spark.read.csv("PATH")
val df3 = df2.toDF("id","name","score")
// 将一个没有表头的csv文件映射成dataframe
// 并按照我们的预定要求映射表结构(字段名、字段类型)
val schema = new StructType()
.add("id",DataTypes.IntegerType)
.add("name",DataTypes.StringType)
.add("score",DataTypes.DoubleType)
val df4 = spark.read.schema(schema).csv("PATH")
项目经验总结
1. 环境问题
在创建自己的项目时,试图将老师的项目中的文件夹直接copy过来,发现依赖关系总会出现问题,于是删除项目,重新新建了项目并手动完成所有文件夹的创建,未发现问题;
2. 开发思路问题
将数据从mysql中读取出来后拿到了DF,但是不知道如何取出DF中的数据,这里是对Spark 的API 不熟练,其实可以用df.getAs用法得到相应名字或者角标字段的数据,还可以指定得到的数据类型,但这里数据类型使用的是泛型,并无代码层面的校验;
3. SQL运行缓慢
上述SQL自join的需求,在我的本机运行的时候,奇慢无比,以为是性能问题,但同学与我配置差不多的电脑上运行不缓慢,遂对比表设计,发现如下几点:
- 未指定主键:表中zip_code未设置为主键,那么该字段就不会自动创建索引,所以导致多次JOIN时每次都全表查询,速度特别慢,指定索引后,查询速度降到了1s以下;
- 将Double类型的字段改为String类型:之前经纬度信息使用double类型保存,精度和长度都使用的数据库默认值,改为String类型后,查询速度快了大约0.2s
- 将每个表join之前先进行level的过滤,及每次join的都是比较小的表,代码量增加,但查询时间快了大约0.2s
上述几点优化不知是否真是可行,还是只是巧合,有待研究;
一些零碎的知识点
- spu:商品(iphone X);sku:具体商品(iphone X 256G 白色)
- sql语句使用spark运行时,不会用到mysql的引擎,所以不会占用mysql的资源(只是从mysql获取数据,但计算(或者说查询)是由spark完成的)
2019.8.27
项目数据预处理
整体流程:
- 读取之前生成好的GEO字典数据
- 将字典数据广播给出去
- 然后读取日志数据文件
- 将文件中的数据解析成JSON对象,再封装成case class
- 对数据集进行条件过滤
- 将结果数据集与GEO字典进行整合
- 将整合后的数据输出
- 同时将查询不到的字段去重后输出
- 请求高德地图解析字典中没有的数据,并将数据添加到GEO字典中
-项目技能提升
1. Json解析 - FastJson
使用Json.parseObject()方法解析Json而不指定封装类的话,就会得到一个类型为JsonObject的对象,这个对象本质上是一个map,可以灵活地通过getString(),getDouble()或者(如果value还是一个map的话)getObject() 等方法来获取需要的字段进行处理。
解析Json的这个方法,因为不涉及到业务逻辑,只是将输入的json文本转换成一个case class,所以可以封装到comms模块下,在当前代码逻辑里,只需要传入json字符串,返回一个样例类即可。 因此,样例类和fastjson的jar包依赖,都不需要在data_ware模块中创建和引用,只需要在comms端创建和引用,dw模块只需import 这个 样例类的包即可(因为之前data_ware模块导入了comms的依赖)。
2. StringUtils工具类 - isNotBlank方法
判断所有字段不同时为空的一个小技巧:使用org.apache.commons.lang3下的StringUtils类里的isNotBlank()方法,该方法在被判断的内容为null,空串,或者一个空格时,都会返回false,可以利用该方法的特点,将需要判断的字符依次拼接起来,判断拼接后的字符串是否不为空,如果返回true,则证明其中至少有一个字符串是非空的;
补充:使用StringBuilder拼接字符串时,如果有某个变量的引用为null,那么会将字符串"null"拼接上,因此需要将最终拼接的结果toString()后调用replace()方法将"null"替换成空串""来完成判断。
3. Scala与Java的Map相互转化
import scala.collection.JavaConverters._
//JAVA MAP
val javaMap: util.HashMap[String, AnyRef] = new util.HashMap[String, AnyRef]()
//Scala Map
//这里可以通过map方法将数据转为想要的数据类型,之后直接调用toMap方法将mutableMap转为immutableMap
val scalaMap: Map[String, String] = javaMap.asScala.map(x => (x._1, x._2.toString)).toMap
4. 广播变量的使用
//将areaMap作为广播变量广播出去
bc = spark.sparkContext.broadcast(areaMap)
rdd.map(x=>{
//excutor端获取广播变量
areaMap = bc.value
})
5. 高德地图逆地理编码服务
//首先创建HTTP的链接,需要导入maven依赖
val client: CloseableHttpClient = HttpClientBuilder.create().build()
//然后生成一个GET请求(不同服务可能需要生成不同请求),根据需要传入参数
val get = new HttpGet("${uri}?key=${key}&location=${lng},${lat}")
//发送请求,得到响应
val response: CloseableHttpResponse = client.execute(get)
//解析这个响应,拿到响应体,就可以对响应体里的内容进行操作了
val content: InputStream = response.getEntity.getContent
-项目经验总结
1.关于Json解析
在思考如何解析json字符串的时候,试图将json按照原格式,一级一级封装到样例类里面,因此创建了许多样例类,作为上级样例类持有的属性的类型,在将数据压平时通过的获取成员变量的方式获取数据的值;对比涛哥的将数据解析成jsonObject之后通过调用JO的解析方法来获取数据,涛哥的方法无需创建大量的样例类。
2. RDD的Join操作
当RDD调用JOIN方法时,两个RDD执行时不会使用同一个taskSet中的task,而是各自有各自的taskSet,但是两者shuffle后的结果,都是同一个RDD在拉取。
3. 关于闭包
学习Spark RDD时接触到“闭包”这一概念,当时的案例会抛出Task not serializable的异常,所以以为“闭包”的概念是“对于函数内引用函数外变量的错误操作的总称”,其实不然,在拜读了官网对于闭包(Closure)的说明后,重新整理“闭包”的概念如下,首先祭出原文及案例:
int counter = 0; JavaRDD<Integer> rdd = sc.parallelize(data); // Wrong: Don't do this!! rdd.foreach(x -> counter += x); println("Counter value: " + counter);Prior to execution, Spark computes the task’s closure. The closure is those variables and methods which must be visible for the executor to perform its computations on the RDD (in this case foreach()). This closure is serialized and sent to each executor.
官网指出,在执行任务之前,Spark会先计算这个任务的“闭包”。“闭包”是指为了进行RDD的计算,必须对executor可见的那些变量和方法。这个“闭包”会被序列化并发送给每个executor;
“闭包”这个概念有些明了了,首先,这是一个名词,其次,报错的原因是因为闭包内的变量或方法所在类没有实现序列化,而不是因为所谓执行了“闭包操作”(即函数内引用函数外的变量或方法这个操作本身);所以,只要闭包内的变量和方法所在类实现了序列化接口,那么我们就可以放心大胆地在函数内引用函数外的方法和变量,只不过需要注意的点是,此时引用的,已经不是Driver端生成的那个对象A,而是序列化后传送到executor端的那个对象B,因此,对于对象B的改变,将不作用于对象A上,如官方给出的案例中, counter变量在executor端不断累加,但在Driver端打印的话,值依然为0;
4. 关于Dataset
Dataset中的类型可以是任意类型,而恰好是Row类型的Dataset也叫DataFrame;
当DS中的数据类型是一个样例类时,DS可以通过样例类反射出表结构,因此DS也可以用来做SQL查询;
若直接调用DS的map等算子,取出数据时,因为是直接调用成员属性, 因此数据类型很明了;
DS调用select算子后,由于有可能对表结构(列数,数据类型)进行改变,因此无法保证类型和以前一致,会返回一个通用类型Row,也就是返回一个DataFrame;
5. Spark广播变量对应MR中的具体实现
首先对于广播变量,官方文档中是这样描述的:
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost.
广播变量允许程序员在每台机器上缓存一个只读的变量, 而不用随任务发送这个变量的副本(详见闭包); Spark还尝试使用一个非常有效率的广播算法去分发广播变量以减少沟通消耗;
Broadcast variables are created from a variable v by calling SparkContext.broadcast(v). The broadcast variable is a wrapper around v, and its value can be accessed by calling the value method.
广播变量由调用SparkContext.broadcast(v)方法创建,广播变量是对于v变量的一个封装,可以通过调用.value方法来得到变量的值;
After the broadcast variable is created, it should be used instead of the value v in any functions run on the cluster so that v is not shipped to the nodes more than once. In addition, the object v should not be modified after it is broadcast in order to ensure that all nodes get the same value of the broadcast variable (e.g. if the variable is shipped to a new node later).
在广播变量被创建好后,任何在集群上执行的函数中都应该使用这个广播变量,而不直接使用变量v,以防止变量v被多次发送到节点上(使用v则v就会被添加到闭包中,随task被序列化并发送到executor);另外,对象v在被广播后不应该被修改,以确保所有节点拿到的广播变量值相同(即使变量以后被发送到新的节点(因为自己已经拿到的chunk不会再去拿,详见下面广播变量的类BT实现));
A BitTorrent-like implementation of
Broadcast.
The mechanism is as follows:
The driver divides the serialized object into small chunks and stores those chunks in theBlockManagerof thedriver.
On each executor, the executor first attempts to fetch the object from itsBlockManager. If it does not exist, it then uses remote fetches to fetch the small chunks from thedriverand/or otherexecutorsif available. Once it gets the chunks, it puts the chunks in its ownBlockManager, ready for other executors to fetch from.
根据官方文档,Spark是通过类似BT种子的方式进行广播的:Driver将广播的内容序列化后分成小块(chunk),存储在自己的BlockManager中,每个executor首先从他自己的BlockManager中抓取这个对象,如果不存在,就通过远程抓取,去driver或者其他executor中抓取这个对象的chunk,一旦拿到这个chunk,就将它放入自己的BlockManager中,便于其他executor来抓取;
相对于广播变量,MapReduce框架中有一个类DistributedCache(分布式缓存),官方给出的解释如下:
Applications specify the files to be cached via urls (hdfs://) in the JobConf. The DistributedCache assumes that the files specified via hdfs:// urls are already present on the FileSystem.
程序在JobConf中指定需要缓存的文件路径,分布式缓存默许这个路径是存在的
The framework will copy the necessary files to the slave node before any tasks for the job are executed on that node.
框架会在任务在slave节点上执行之前,将所需要的文件复制到节点上
分布式缓存和广播变量一样,都是只读的,分布式缓存将需要共享的文件放在hdfs里并通过DistributedCache.addCacheFile() 将路径通知给各个slave,各个slave自己运行job之前会去hdfs下载;而广播变量通过SparkContext.broadcast()将需要共享的内容放在自己的BlockManager中,等待executor来抓取;
-项目知识点补充
- executor对应一个进程,task对应一个线程(task本质是一个实现Runnable的类,被一个线程执行)
- coalesce(1)的作用:当测试时,数据量不大,写入文件并不需要太大的并行度(写入多个文件),而spark sql默认的shuffle操作并行度是200(spark.sql.shuffle.partitions=200)
- 会产生shuffle的算子:
- repartition类:如 repartition,coalesce
- 'ByKey类:如 groupByKey, reduceByKey
- join类:如 join,cogroup
2019.8.28
ODS层,DW层,ADS层数据加载
整体流程:
- Hive ODS层表创建
- ODS层加载数据
- DWD层明细表建模
- DWD层数据注入
- DWS层聚合表创建
- DWS层数据注入
- ADS层表创建
- ADS层表数据生成
-项目技能提升
1. DSL风格 数据集API 夯实
SQL中的关键字,几乎都可以用dataframe中的DSL风格的API来实现:
Select:
//参数可以是字符串,也可以是Column对象
df.select("id","name")
df.select(df("id"),df("name"))
//如果导入了隐式转换,就可以用一些特殊的用法
import spark.implicits._
df.select($"id", 'name)
//或者用spark sql 的内置函数构建col对象
import org.apache.spark.sql.functions._
df.select(col("id"))
//如果想对列进行操作,需要调用col的函数或使用selectexpr
df.select('id, upper('name))
df.selectExpr("id", "upper(name)")
上述代码中df("id")这个方法,其实是调用了df的apply方法,会查找名为id的列并返回他的Column对象;
Where:
//SQL风格和DSL风格对比
df.where("score > '80'")
df.where('score <=> "80")
Group By:
//聚合的三种方式
//直接max
df.groupBy("gender").max("score")
//求最大和最小值
df.groupBy("gender").agg("score" -> "max", "score" -> "min")
df.groupBy("gender").agg('gender, min('score), max("score"))
上述方法中的参数"score" -> "max"是scala中的一个语法糖,这样写就相当于创建了一个元组(score,max)
窗口函数:
//先创建一个window对象,指定partitionBy和orderBy
//然后在select中调用函数row_number()的over方法,把window传入,并取别名
val window = Window.partitionBy('gender).orderBy('score.desc)
df.select('id,'name,'gender,'score,row_number().over(window).as("rn"))
Join:
//df1和df2join,条件是两表id字段相同,结果中仅保留一列 id
df1.join(df2,"id")
//JoinWith ,是针对dataset的特定join,可以保留dataset中原有的数据类型
//注意看返回值DataSet中的类型, 一行返回两个类,而不是多个字段
val dsr: Dataset[(Person, Student)] = ds1.joinWith(ds2,ds1("id") === ds2("id"))
2. Coalesce的使用
coalesce(a,b,c)
返回a,b,c中,第一个不为空的值,这里只能判断是否为null,对于空串或者空格,需要自己额外判断
-项目经验总结
1. Hive建表
ODS层数据建模时:
因为是贴源层, 字段应与来源字段保持一致,不做任何处理;
ODS层建表时:
因为是采用Hive建表,然后直接load parquet文件里面的数据的方式,所以选择建外部表,这样删除表后对外部的parquet文件没有影响; 因为每天都有数据,所以建立分区表按照天分成不同的文件夹存储;
创建ODS层表:
drop table if exists yiee.ods_eventlogs;
create external table if not exists yiee.ods_eventlogs(
--fields..
)
partitioned by (dt string)
stored as parquet
location '/hivedata/eventlogs';
后面三句话的顺序不能错,否则创建失败;这里的路径,是说以后如果往这个表里insert数据的话,产生的parquet文件会生成在哪个目录(insert数据时,会根据目标表的定义,生成相应格式的文件 )
2. 关于建模时的SQL
之前星哥教过一种方法,是把一个需求的每一步自己分析出来的SQL语句记录下来,方便后续需求变更或者维护的时候做修改和查询;今天亲自尝试了一下这种方法,效果非常明显,之前写好的SQL一定是可以运行的,只需要在原来的基础上做一些更改,则可以实现非常快速的实现表重建,数据重新插入,表字段变更等操作;
3. 关于scala中的隐式转换
之前在使用阿里巴巴的FastJson时,调用toJSONString()传入一个AnyRef的对象试图获得字符串时,报二义性错误,分析原因是该方法还有一个重载方法,传入两个参数,第一个参数是AnyRef类型,第二个参数是一个序列化器,sparkSession.implicits._中有该序列化器类型的变量存在,导致编译器不知道该绑定哪个方法;
因此想到了scala中是如何处理这种问题的,进行如下测试:
object Test1 {
implicit val str: String = "参数2"
def main(args: Array[String]): Unit = {
//编译不通过
//println(test1("参数1 "))
}
def test1(str: String)(implicit str2: String): String = {
str + str2
}
def test1(str: String): String = {
str
}
}
对象中定义了两个重载的方法test1,main方法中只传入一个参数的话,编译器是不通过编译的,所以会提醒你cannot resolve overloaded method test1,此时可以选择1:将test1两个参数的方法列表的第二个列表中的implicit关键字去掉,骗过编译器,但执行时仍然会报二义性错误(跟之前json解析时的一样)2:将一个参数的方法注释掉,运行不会报错;
4. 关于hive 中的 字段别名
在select表达式中想要对某些字段起别名,比如 date 但是date又是hive中的关键字,直接写 as date就会报错
Error: Error while compiling statement: FAILED: ParseException line 1:79 cannot recognize input near ‘as’ ‘date’ ‘from’ in selection target (state=42000,code=40000)
这时需要将表别名使用反单引号引起来 "``"(引号里面这两个键盘1左边)
-项目知识点补充
- hive 的客户端命令行中可以直接输入hdfs的命令(如 dfs -ls);
- 加载hive表数据时,load的方式会移动原数据文件到表定义的数据文件夹中,如果使用修改表定义add partition的方式,则相当于只是把这个表的这个partition的路径属性更改了,所以不会移动数据文件;
- 建hive表时 在字段后紧跟 COMMENT ‘…’ 可以在查看表结构的时候看到这个注释;
- Apache 有一个atlas元数据管理系统,用来记录目前有哪些表,表的模型信息,各个表之间的血统关系,但对于hadoop生态圈中各个组件的版本要求比较严格;
2019.8.30
需求2:日新日活流量统计
整体流程
- 日活表创建
- 日活表数据导入
- 历史用户数据表创建
- 日新表数据创建
- 日新表数据导入
- 历史用户数据表更新
项目技能提升
1. 临时表创建
插入数据时,有时想要对表进行简单的过滤之后再作为子表,但是不想写子查询,那么就可以先声明一个临时表和这个表的别名,下面sql中直接使用这个别名即可:
with dau as (select * from t1 where xxx)
insert into table t2
select
*
from dau;
2. OLAP多维数据分析(Hive高阶聚合函数)
背景:对于有多个维度的明细表,有时业务可能需要不同维度的组合来进行多维度的分析,那么如果将数据每个维度都新建一张表会建立大量的表,不利于维护,所以需要将这些不同维度的数据都插入到同一张表中;
原理:建立一张最细粒度的表,然后插入数据,当遇到更粗粒度的数据时,被忽略的维度给null值,即可实现所有数据都在同一张表汇总;
实现:现实中,表虽然有了,但是如果每种维度都需要手动去插入数据,那么效率还是极低,所以引入了hive高阶函数,(一键)生成想要的维度的数据:
- with cube
select
...
from t1
group by c1,c2,c3
with cube;
上述代码相当于查询出了group by 后面的所有维度的所有组合 (一共8种,从000到111);
- grouping sets
select
...
from t1
group by c1,c2,c3
grouping sets((c1,c2),(c1,c3),(c2),());
grouping sets 不像with cube, 会生成所有的维度的所有可能性的组合,而是可以手动地指定想要生成哪些维度的组合, 没有指定的组合将不被生成;
- with rollup
select
...
from t1
group by c1,c2,c3
with rollup;
有时数据是按照层级关系存储的,需要的就是下到上的越来越粗的粒度的数据,没有交叉维度的分析,那么就可以使用rollup, 将维度从右到左卷起,上述代码相当于 grouping sets ((c1,c2,c3),(c1,c2),(c1),()) -> 粒度由细到粗
项目经验总结
1. sparkSession的Encoder问题
现象:使用sparkSession.createDataset()创建Dataset时,如果传入的Seq类型是Map类型,那么编译时会报错,提示没有对应的encoder
解释: reateDataset()是一个科里化方法,需要传入第二个参数Encoder,sparkSession的隐式转换类中有基本数据类型和case class 的encoder,但是没有Map的encoder,所以会报错,如果想正常运行,需要使用 Encoder.kryo(Classof[T]) 这个方法构建一个encoder 并传入
2. 关于Hive的窗口函数
结论:
当over()中指定了order by 字段,但未指定窗口规格时,默认的窗口规格是 range between unbounded preceeding and current rows
当over()中未指定order by 字段,也未指定窗口规格时,默认的窗口规格是 row between unbounded preceeding and unbounded following
关于range 和 row 区别的理解:
首先明确,窗口函数是逐行运算时,也能返回聚合的结果,那么窗口规格,则是决定了聚合时的数据范围; 比如同样是1 preceeding and 1 following,如果前面是range,则是聚合时,将所有与该行数据数值差距正负不大于1 的所有行的数据聚合,而如果前面是row,则是聚合时,将该行和前一行和后一行的数聚合
项目知识点补充
- hive建表时,如果不指定store as 的文件类型,则默认为textFile类型
- 设置Hive底层执行MR时的运行模式为本地模式(不提交到yarn上):
set hive.exec.mode.local.auto = true - 插入数据时,
insert into table是数据追加,insert overwrite table是数据覆盖
2019.9.1
项目需求
- 用户留存分析
- 用户新鲜度分析
项目技能提升
1 留存分析
背景:这是一个围绕某日新增用户的度量,想要计算的是某日新增的用户中,过了几天仍然活跃的有多少人,占哪一天新增用户的比例是多少
方案:数据取自hisu表,按照首登日分组,将每个首登日的人数(当天新增用户)计算出来,然后求出这个首登日据计算日的差值,则为这个首登日对应的留存时间,然后再求出该组中末登日为计算日的个数,这个值即为留存人数;每个首登日每天都要更新一次,更新的是最新的数据,采用插入而不是覆盖写的方式,让最新的数据和历史数据都保存,方便业务以时间作为维度进行分析;
实现:
insert into dws_user_retention_dtl
select
first_login as dt, --首登日
count(1) as dnu_cnts, --首登日总新增人数
datediff('2019-06-16',first_login) as retention_days, --留存时间
count(if(last_login='2019-06-16',1,null)) as retention_cnts --是否计算日活跃(是否留存)
from dwd_hisu_dtl
where datediff('2019-06-16',first_login) between 1 and 30 --限制分析范围
group by first_login;
2.新鲜度分析
背景:这是一个围绕某日活跃用户的度量,想要计算的是某日活跃用户中,用户的新鲜度分层(新鲜度按照注册时间进行分层)
方案:数据同样取自hisu表,先过滤出末登日等于计算日的数据,这些数据是我们需要的“某日活跃用户”的数据;然后count求出总的活跃用户,再按照首登日进行分组,组内count得到每层新鲜度的人数
实现:
with tmp as (
select
uid,
first_login,
last_login,
datediff(last_login,first_login) as fresh
from demo_hisu_dtl
where last_login='2019-08-30' and datediff('2019-08-31',first_login) between 1 and 30
) --过滤出需要的数据
insert into table dws_active_fresh_dtl
select
b.dt, -- 计算日期
a.dau_amt, -- 活跃总数
b.fresh, -- 新鲜度
b.fresh_cnts -- 新鲜人数
from
(
select count(1) as dau_amt from tmp --当日总活跃用户
) a
join --a表只有一行数据,而且b表也只有一个日期,所以直接join无需加条件
(
select
'2019-08-30' as dt, -- 计算日期
fresh, -- 新鲜度
count(1) as fresh_cnts -- 该新鲜度下的人数
from tmp
group by fresh
) b
;
3.关于成绩查询
一道思考题:现有表test_score数据如下:
张三 语文 80
张三 数学 60
张三 地理 90
李四 物理 50
李四 化学 80
李四 政治 0
需要将竖表转成横表,但学生未修的科目需要体现出来
思考过程:
原本的思考很简单,只需要select 多写几个表达式就好了,以科目作为sum的过滤条件,当不符合条件时给0;但是这个方法无法正确的区分真的得了0分还是未修该课程,因此进一步思考:区分不出来是因为当不符合条件时,给了0,这个0和真的得了0分时是同样的返回值,因此当不符合条件时,给别的返回值就可以了; 这里可以给null,null跟任何数相加都等于任何数,全都是null相加, 结果还是null,因此可以将未修课程和得0分的课程区分出来;
select
name,
sum(if(subject = '语文',score,null)) as `语文` ,
sum(if(subject = '数学',score,null)) as `数学` ,
sum(if(subject = '地理',score,null)) as `地理` ,
sum(if(subject = '物理',score,null)) as `物理` ,
sum(if(subject = '化学',score,null)) as `化学` ,
sum(if(subject = '政治',score,null)) as `政治` ,
sum(if(subject = '历史',score,null)) as `历史`
from test_score
group by name
4.hive实现map的聚合函数
对于set和list,hive中有聚合函数collect_set 和collect_list让数据聚合时被收集到一个集合里,针对于想让数据聚合时被收集到一个map里这种需求,可以借助如下方法:
思路:先将每一行的kv进行字符串拼接(拼接符“:”),然后进行聚合,将每一行的字符串收集到一个list中去,然后用函数将数组中的数据进行字符串拼接拼成一个大长串(拼接符“,”),然后用函数将字符串转化为map;
实现:
select
dt,
dnu_cnt,
str_to_map(concat_ws(',',collect_set(concat_ws(':',cast(retention_days as string),cast(retention_cnts as string)))),',',':') as info
from demo_retention_dtl
group by dt,dnu_cnt
//逐层分析
//L1 首先将每行的kv使用冒号拼接成一个字符串
concat_ws(':',cast(retention_days as string),cast(retention_cnts as string)) as L1
//L2 然后将数据聚合,收集到一个set中去
collect_set(L1) as L2
//L3 将数组使用逗号进行拼接(字符串拼接函数可以传入一个数组)
concat_ws(',',L2) as L3
//L4 最后,指定分隔符,将拼接好的字符串转成map
str_to_map(L3,',',':') as L4
项目经验总结
1. 关于数仓建模
数仓设计分为两大领域,一种是OLTP领域,这一领域,数据经常随机单条更新,所以要保证更改一条数据,其他需要改动的地方尽量少,因此数仓设计遵循三范式(多用雪花型模型设计),尽量减少数据的冗余;另一个领域是数据分析领域,这一领域,数据是稳定的,但是需要跨大量的数据进行计算,因此不讲究三范式,容许数据的冗余(多用星型设计模型),因为大量数据join非常的耗费性能。
2. hive 的优化
count(distinct id)这种写法肥肠的耗费性能,因为他会将所有的id都发送给同一个reducer,reducer在将所有的id放入set中求这个set的size;相较之下,select count(*) from (select id from _ group by id) t这种方法, 会根据ID将id发给不同的reducer进行去重,然后将去重好的id再发给同一个reducer,性能上会好很多,不会造成数据倾斜- 在join时,当某个表小于阈值时,hive会自动选择map端join
- 在join时,当两个表都很大时,如果两个表是按照相同的逻辑
分桶并且分桶数一致时,hive会只join桶号相同的两个文件; - 关于需要分多少桶,需要具体情况具体分析,原则上倾向于将每个任务切片的大小保持在100M左右,这样可以保证一个任务只从一台机器上拉取数据,而且任务会被发送到数据所在的机器,所以相当于从本地拉取数据,不会占用网络资源
5. 关于新鲜度的优化
技能提升中的求新鲜度的sql执行有些缓慢,因为创建了临时表,子查询还会join,尝试了不进行join的写法,使用了窗口函数,得到了相同的结果;但是其中某些用法比如sum(count(1))没有找到官方的解释,不知道是否只是恰巧可以这样用,只找到了一个国内的博客上面记录了相同的现象;这里我理解直接count(1) over()的话,count的是分组去重过后的数据,因此30号按照首登日去重后,只有15条数据,count(1) over()的话得到的数据是15, 但是sum(count(1)) over()是将按照首登日去重后的count出的每个首登日的条数相加得到总和;
另外还发现,如果表达式中不在前面事先出现count(1) 这个表达式的话,sum(count(1)) over()这个表达式会报错,说没有count()这个udaf
select
last_login, --首登日
concat(datediff(last_login,first_login),'天') as days, --新鲜度
concat(substr(count(1) * 100 / sum(count(1)) over(partition by last_login ),0,5 ),'%')as rate -- 某新鲜度人数/总活跃人数
from
demo_hisu_dtl
group by last_login,first_login;
6. 临时表创建
--临时表中不能有对其他临时表的引用
with tmp1 as () ,tmp2 as (), tmp3 as ()
7. sum(if())
select 表达式中,根据条件求和时要将条件写在sum()里面,否则的话,用于做来判断的列将暴露在聚合函数之外,会提示这个列需要group by
2019.9.2
项目进展
- 针对之前编写的SQL和spark程序编写sh调用脚本
- 使用Azkaban进行任务调度
项目技能提升
1. 编写shell 脚本
执行spark程序:
#!/bin/bash
#将日期预设成当前天减一天
dt=`date -d'-1 day' +'%Y-%m-%d'`
#判断用户执行脚本时是否传入了参数,若传入了参数,使用传入的参数作为日期
if [ $1 ]
then
dt=$1
fi
echo "正在计算${dt}数据"
#执行spark程序,并引用变量
spark-submit...... /data/eventlog/${dt}
执行sql语句:
#!/bin/bash
#一样的逻辑判断日期参数取值
dt=`date -d'-1 day' +'%Y-%m-%d'`
if [ $1 ]
then
dt=$1
fi
echo "准备生成dws层dws_traffic_agg_session表数据......"
#注意未切换库的情况下,要指明表属于哪个库
SQL="
insert into ...
select
...
from yiee.dwd_traffic_dtl
where dt='${dt}'
"
#hive -e 后面的双引号要保留(注意配置hive_home环境变量)
$HIVE_HOME/bin/hive -e "${SQL}"
2.Azkaban任务调度
是一个任务调度工具,由元数据库建表语句,web界面,和executor三部分组成,可以按照顺一定的顺序执行job,每个job都可以是一个命令,命令通过参数配置在每个job的配置文件中,可以单纯打印一句话,也可以执行某个jar包中的类,也可以运行某个sh脚本,多个job组成一个project,这个project所依赖的所有job配置文件,和资源必须都被打进一个zip文件夹中,通过web页面上传到azkaban服务器,进行调度或者执行;
具体安装步骤,使用方法,经验总结今天略,明天仔细研究;
项目经验总结
1. 关于环境
建立的maven的父子工程,想要打包,于是在父模块上使用maven的install命令,试图全部打包,但是一直不成功,看日志像是一直无法获取一个阿里云上的scala-lang 的jar包,在父模块的pom文件中手动引入这个jar包后重新install还是报同样的错误; 于是先尝试在子模块dw中使用install命令,不报错,然后在父模块中使用install命令,也不报错了;
2.关于spark程序
- 如果spark在运行时报
"no such method"等错误,多半是版本不兼容 - spark 提交到yarn上的任务,可以查看日志文件,日志的位置在
hadoop_home的logs目录下的userlogs中,找到对应的appid和容器id - 使用yarn 的
logs命令可以dump出日志,但需要配置history server - 程序代码中想要使用hdfs的路径的话直接在path上加上前缀
hdfs://host:port/.... - spark on yarn需要配置
hadoop_conf_dir变量
3.关于shell脚本
- 如果脚本里面使用
hive -e写sql 的话,要注意本来有双引号单引号的地方,要保留双引号和单引号 - sql中的表如果不是默认的库,注意加上库名
date -d'-1 day' +'%Y-%m-%d'获得当前日期减一天的日期;date -d"-1 day $1" +'%Y-%m-%d'获得输入第一个参数的日期减一天(这里将单引号替换成双引号因为单引号会把$1解释成一个普通的字符串而不是第一个参数)
项目知识点补充
- which + 命令 可以查看这个命令所在的目录
vi一个文件后,gg到文首,dG删除一直到文末的内容(删除全部内容);IDEA可以直接连接HIVE,需要启动hiveserver,安装插件并重启idea,然后只需要hostname,端口号和用户名即可
2019.9.3
项目需求
- 使用Azkaban调度任务
- 计算活跃用户留存
项目技能提升
1. azkaban 调度器
安装部署步骤比较繁琐,建议按照文档一步一步进行
注意时区的配置,复制证书,修改配置文件,启动mysql数据库,导入mysql数据库的表到azkaban库中;
注意启动webserver时,会在启动路径下(编写命令的当前路径)寻找证书文件,所以要在根目录下执行启动命令;
2. 活跃用户留存
活跃用户留存概念: 某日活跃的用户中,过了几天又活跃了的人占某日总活跃人数的比例,这里强行去join的话可以做,但是考虑到效率和性能问题,使用拉链表来完成这个需求;
拉链表记录用户,首登日,连续活跃期间起始日期,连续活跃期间结束日期
能够非常明确地求相应天数之前活跃的人中,在今天仍然活跃的有多少,结合历史数据,就能求出图中右下角的一层数据,每日数据累加,就能求出表中所有数据
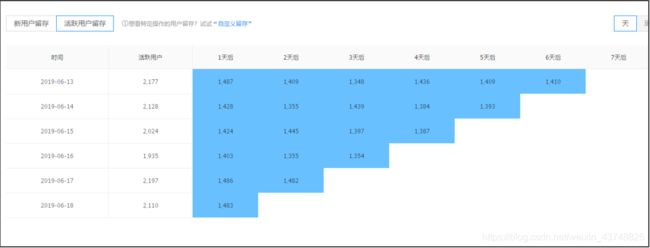
- 为什么之前设计的历史表不能满足需求(在不强行join的情况下)?
- 因为拿到今天的活跃用户时,无法判断每个用户n天前是否是活跃的状态,只记录首登日和末登日,无法判断中间几天到底是什么状态;
项目经验总结
1. 关于拉链表
拉链表的思想:
针对状态很长时间不变的数据,使用状态区间来代替每日重复的状态快照,节省空间;当状态不改变时,表就无需改变,当状态改变时,就将原来的区间封闭 (拉链),然后生成新的状态区间,已经封闭的区间就不会再改变了;
前提:数据变化的频率不高,如果每天都变化,那么拉链表的意义就不大了(每天都会产生新的状态区间)
2. 关于后台运行命令
- 命令后面加上
&字符, 将进程在后台运行,(但是输出还是会输出到控制台) - 进程运行时按
ctrl+z这个操作会将进程挂起(暂停),并不是在后台运行;使用命令fg+job号将后台程序拉到前台 - 在
&字符前加上1>/root/std.out 2>/root/err.out使程序在后台运行并将标准输出输出到std.out文件,错误输出输出到err.out; 这里补充:任何一个程序,都有两个输出(1.标准输出,2.错误输出)和一个输入(0.键盘输入),两个输出默认是输出到控制台上,如果将输出重定向到1>/dev/null则是将输出抛弃;
2019.9.5
项目经验提升
-
访问间隔分析
分析的是一段时间范围内,中间隔了n天才由下一次访问的人数分布情况
-
窗口函数
- lead(c,n) over() 取出c字段n行之后的值(over里面指定
拆分依据(如果什么字段改变了,就重新计算顺序;)和排序依据(所谓n行之后的后是按照什么顺序而来的;)) - lag(c,n) over() 取出c字段n行之前的值
- first_value( c ) over() 某字段在窗口中的第一个数
- last_value( c ) over()某字段在窗口中的最后一个数(要指定order by,否则就是这个数本身,因为不指定order by 默认是
ranges over unbounded preceding and current row, 即窗口规格为所有不比自己大的数) - sum() over()
- count() over()
- row_number() over() 排序,无并列排名
- rank() over() 排序,有并列排名,排名数字不连续
- dense_rank() over() 排序,有并列排名,排名数字连续
- ntile(n) over([partition by ] order by) 有一个有序的数据集和按大小平均分配到n桶中。(序号从1 到 n,若不能平均分配,则优先分配编号较小的桶,且各桶号的行数差不超过1)
2019.9.6
项目需求
-
业务路径转化率,按照标准2: 判断是否满足业务C步骤,只要求C事件发生前,前面发生过 B ,B前面发生过A,不要求紧邻的规则来求出完成某业务的某步骤的人数有多少
* 比如,业务定义的步骤事件分别为: A B C D * 假如,某个人的行为记录为: * 张三: A A B A B C * 李四: C D A B C E D * 王五: A B B C E A D * 赵六: B C E E D
项目技能提升
- 规则引擎
企业级管理者对企业IT系统的开发有着如下的要求:
1.为提高效率,管理流程必须自动化,即使现代商业规则异常复杂。
2.市场要求业务规则经常变化,IT系统必须依据业务规则的变化快速、低成本的更新。
3.为了快速、低成本的更新,业务人员应能直接管理IT系统中的规则,不需要程序开发人员参与。
项目经验总结
- 业务路径转化率代码设计知识点众多,列出完整代码,在代码中根据步骤再做详细的思考总结
def routeMatch(userActions: List[String], transSteps: List[String]): List[Int] = {
// 首先定义一个算法,传入用户的操作顺序,和业务的步骤;
// 求出该用户完成的业务的步骤的list
// userActions : A B B D A C F
// transSteps: A B C D
// 返回: List[1,2,3]
val ints = new ListBuffer[Int]
var index: Int = 0
var flag = true
//这里因为想要取出业务步骤中对应的编号,所以定义角标i
//这里后面发现需要控制条件当某条件达到时跳出循环;
//因为scala中没有break,因此使用for循环的守卫,将达成需要跳出的条件时,将守卫条件改为false
for (i <- transSteps.indices if flag) {
//每次找到元素后,都要记录这个元素的位置,下一次继续从这个位置找
index = userActions.indexOf(transSteps(i), index)
if (index != -1) {
//角标从0开始,但步骤从1开始
ints.+=(i+1)
} else {
flag = false
}
}
ints.toList
}
//...省略前面导入用户数据和字典数据
// 将业务路径定义变成hashmap格式
/**
* Map(
* "t101" -> list[(1,A),(2,B),(3,C),(4,D)]
* "t102" -> list[(1,D),(2,B),(3,C)]
* )
*/
val routeMap: collection.Map[String, List[(Int, String)]] = routeDefine
// 这里拿到的rdd 的格式是row,里面装了四个字段
// T101 1 步骤1 A null
.rdd
.map(row => {
val t_id = row.getAs[String]("tid")
val t_event = row.getAs[String]("event_id")
val t_step = row.getAs[Int]("step")
// 这里是想将row格式,转换为元组模式,有kv,方便分组
// 取序号出来是为了保证顺序不错
// (T101,(1,A))
(t_id, (t_step, t_event))
})
// 这里就真的进行分组了,分组后,每个key的value 是一个迭代器
// T101,(1,A)
.groupByKey()
// 拿到每个迭代器,将这个迭代器直接转换为一个list,并按照指定顺序排序
// T101,List((1,A),(2,B),(3,C),(4,D))
.mapValues(iter => iter.toList.sortBy(_._1))
//将这个字典数据收集到driver端,准备当做广播变量发送出去
.collectAsMap()
// 广播
val bc = spark.sparkContext.broadcast(routeMap)
// 处理用户行为
val x: RDD[((String, String), String)] = userActionRoute
//这里返回一个df[Row]
.select("uid", "sid", "step", "url")
// 这里拿到的rdd是一个row类型的一列value
// Row(u01,session1,1,A)
.rdd
// 将row类型转换为元组类型,把其中的步骤转成数字
// Row(u01,session1,1,A)
.map(row => {
val uid = row.getAs[String]("uid")
val sid = row.getAs[String]("sid")
val step = row.getAs[String]("step")
val url = row.getAs[String]("url")
(uid, sid, step.toInt, url)
})
//这里groupby,是将同样uid和sid,即同一用户的数据放在一组,这个用户的所有行为信息将被放入一个迭代器
//(u01,session1),(u01,session1,1,A)
//(u01,session1),(u01,session1,2,B)
.groupBy(tp => (tp._1, tp._2))
//而这里的mapValues, 又是将这个迭代器中的所有元素按照顺序排好序;
//并将list中的元组map成一个步骤的字符串(从元组中只取出字符串)之后将这个list通过mkString直接变成字符串
.mapValues(iter => {
// 这里就是一个人的一次会话中所有行为事件,并且按次序排好序了
val actList = iter.toList.sortBy(tp => tp._3)
// 将这个人的这些事件中的url拿来拼一个字符串
val actStr = actList.map(_._4).mkString("")
//(u01,session1),"ABSJDUWGS"
actStr
})
// 现在这个RDD就变成一个用户一条了(后面跟他的操作步骤)
// 拿处理好的用户行为记录,去比对业务路径,看满足哪些业务的哪些步骤
// 业务字典:
/**
* bc:
* Map(
* "t101" -> list[(1,A),(2,B),(3,C),(4,D)]
* "t102" -> list[(1,D),(2,B),(3,C)]
* )
*/
// 用户行为 x
//((u01,s01),XYABCBO)
//((u02,s02),ACABDBC)
// TODO 套算法
val res = x
//这里是因为一个tp想对应多行,所以输入tp返回一个list,使用flatmap就会自动分成多行
//输入((u01,s01),XYABCBO)
//输出 (u01,T101,1)
// (u01,T101,2)
.flatMap(tp => {
// 用户id "u01"
val uid = tp._1._1
// 不toString的话拿到的是个char数组
// 用户的行为事件序列 List("X","Y","A","B","C","B","O")
val userActions: List[String] = tp._2.toList.map(c => c.toString)
//业务步骤字典数据
//因为字典中有多条业务的业务步骤,因此,需要遍历这个MAP中的所有业务依次求出用户满足的所有步骤
val transRoutes: collection.Map[String, List[(Int, String)]] = bc.value
// 构造一个listbuff来装结果(uid,t_id,t_step)
val resList = new ListBuffer[(String, String, Int)]
// 遍历每一项业务
// 遍历map的方法, 拿到里面的每个entry
//"t102" -> list[(1,D),(2,B),(3,C)]
for ((k, v) <- transRoutes) {
// 业务中的步骤事件序列
// list(D,B,C) ---> 这是T102(k) 的业务步骤
val transSteps = v.map(_._2)
// 调算法
// 这里拿到的是 该用户 k业务的 完成步骤List
// List(1,2,3)
val okSteps: List[Int] = TransactionRouteMatch.routeMatch(userActions, transSteps)
//那么我们顺势将用户信息和业务信息加上(这个即为最终想要的输出格式)
//List[(u01,T102,1),(u01,T102,2),(u01,T102,3)]
val resOneTrans = okSteps.map(okStep => (uid, k, okStep))
//将该用户的每一个业务list都添加到这个用户的resList中去,
resList ++= resOneTrans
}
//List{List[(U1T1S1),(U1T1S2),(U1T1S3)],List[(U1T2S1),(U1T2S2)]}
//打平后会将每个元组作为一行,即为所求
resList
})
.toDF("uid", "tid", "stepid")
res.show(20, false)
spark.close()
项目知识点补充
- 可以使用ListBuffer来构造一个可变的list,不需要用mutable arryalist
- mkString将list变成String
- string.tolist 得到一个char数组 .map(_.toString()) 后得到String数组
- 使用groupBy算子将RDD 分组,这样即可以得到一个value的迭代器,方便后面针对迭代器里面的内容进行聚合
- 关于不能再foreach中调用list.remove方法
进行上述操作时会抛出ConcurrentModificationException,原因是迭代器在调用next方法是会调用checkModification方法,检查modCount(集合被修改的次数)和expectedModCount(迭代器期待集合被修改的次数)是否相等;modCount为Arraylist的成员变量(继承自父类AbstractList),expectedModCount为Arraylist的内部类Itr的成员变量,被初始化时会被modCount赋值; 当调用Arraylist的remove方法时,只会修改modCount,而不会修改expectedModCount,所以当Itr调用next方法时,就会抛出异常; 而Itr自己的remove方法中对二者进行了赋值处理,保证两者相同,而且对cursor属性进行了lastRet赋值,保证了cursor(Itr的属性) 和size(ArrayList的属性)相等;
另外,即使是在集合的最后一个元素时执行的删除,也会使Itr调用next方法,原因是Itr的hasNext方法中判断了ArrayList的成员变量cursor和size的值是否相等,若不相等则返回true,而通过Arraylist的remove方法删除数据时,size会被减1,但cursor不会更改,导致两者不相等,hasNext方法返回true,还是会调用next方法;