【职场菜鸟】工作总结与问题解决
目录
目录
工作总结
一、Linux和java环境相关
二、git操作
三、数据表操作
四、java语言学习
五、实际开发相关
六、基础原理探索
遇到的问题
一、postman测试
二、java语言方面问题
三、实际开发问题
工作总结
一、Linux和java环境相关
- Linux常用命令
echo
find
cut
grep
awk
sed
tr
sort
uniq
uptime
top
free
显示文字 查找文件 按列切分文本 文本搜索 数据流处理工具 文本替换 字符转换 排序 消除重复行 显示运行时间 实时显示进程状态 显示系统内存使用情况 -
为跳板机配置免密登录:
①进入跳板机,根目录:
把 eval `/usr/local/bin/ssh-attach` 复制到文件 /home/用户名/.bashrc 下:
-
光标使用方向键划到最后一行,输入‘o’在当前行下创建一行,输入 eval `/usr/local/bin/ssh-attach`
注意:引号为左上角`,而非回车边上的’
将文件保存退出
③执行.bashrc文件:

二、git操作
-
合并master分支:
①切换分支到master:git checkout master
②将代码pull到本地:git pull
③修改冲突
④提交到本地:git add . git commit -m "merge
⑤切换到你所在分支dev:git checkout dev
⑥merge:git merge master
⑦将本地内容push到dev分支:git push
-
git查看本地分支与远程分支的对应关系:git branch -vv
-
提交本地新分支到远程分支(远程分支不存在):git push origin RBA-2696:RBA-2696
-
本地新分支关联远程分支(远程分支存在):git branch -–set-upstream-to=origin/远程分支名
-
合并分支通过git merge命令合并完后,还需通过git push命令将代码同步到远程合并分支
三、数据表操作
-
对order_main表进行操作:
查询order_main表与address表中address_id相同的数据:
SELECT order_main.order_id, address.city_id, address.region_id, order_main.ref_city_id, order_main.ref_region_id FROM `order_main`, `address` WHERE order_main.address_id = address.address_id ORDER BY order_main.order_id ;
更新order_main表中address_id为2101735的数据:
UPDATE order_main, address SET order_main.ref_city_id=address.city_id, order_main.ref_region_id=address.region_id where order_main.address_id=address.address_id AND order_main.address_id=2101735
查询order_main表中的数据:
SELECT order_main.address_id, order_main.ref_city_id, order_main.ref_region_id, address.city_id, address.region_id FROM order_main, address WHERE order_main.address_id = address.address_id -
mysql查询某个时间段数据:
今天
select * from 表名 where to_days(时间字段名) = to_days(now());
昨天
SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) <= 1
7天
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(时间字段名)
近30天
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 30 DAY) <= date(时间字段名)
本月
SELECT * FROM 表名 WHERE DATE_FORMAT( 时间字段名, '%Y%m' ) = DATE_FORMAT( CURDATE( ) , '%Y%m' ) -
复习了mysql范式:
范式
要求
第一范式 字段不可分 第二范式 有主键,非主键字段依赖主键 第三范式 非主键字段不能相互依赖,不存在传递依赖 -
熟悉SQL和NoSQL的区别以及应用场景
NoSQL应用场景:数据库表schema经常变化;数据库表字段是复杂数据类型;高并发数据库请求;海量数据的分布式存储。
区别:


-
mybatis查询数据库使用sum()标签后,应对其进行重新命名:

-
了解了关联表的时候,若两个表之间的数据存在“一对多”的关系,通常会在“多”的表中添加“一”的主键,进行联表查询。
例如:洗涤厂和服务区域存在一对多的关系,通常会在洗涤厂服务区域表中添加洗涤厂的主键,来进行联表查询:
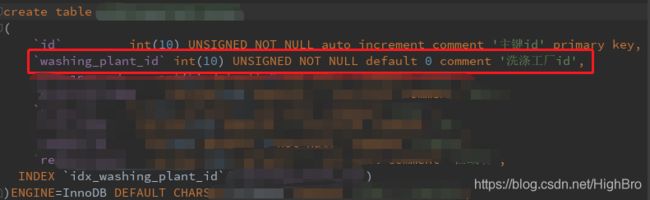
-
SQL优化:EXPLAIN:查看sql执行计划

-
SQL关于索引的优化:
负向查询不能使用索引
select name from user where id not in (1,3,4);应该修改为:
select name from user where id in (2,5,6);前导模糊查询不能使用索引
select name from user where name like '%zhangsan'非前导则可以:
select name from user where name like 'zhangsan%'建议可以考虑使用
Lucene等全文索引工具来代替频繁的模糊查询。数据区分不明显的不建议创建索引
如 user 表中的性别字段,可以明显区分的才建议创建索引,如身份证等字段。
字段的默认值不要为 null
这样会带来和预期不一致的查询结果。
在字段上进行计算不能命中索引
select name from user where FROM_UNIXTIME(create_time) < CURDATE();应该修改为:
select name from user where create_time < FROM_UNIXTIME(CURDATE());最左前缀问题
如果给 user 表中的 username pwd 字段创建了复合索引那么使用以下SQL 都是可以命中索引:
select username from user where username='zhangsan' and pwd ='axsedf1sd' select username from user where pwd ='axsedf1sd' and username='zhangsan' select username from user where username='zhangsan'但是使用
select username from user where pwd ='axsedf1sd'是不能命中索引的。
如果明确知道只有一条记录返回
select name from user where username='zhangsan' limit 1可以提高效率,可以让数据库停止游标移动。
不要让数据库帮我们做强制类型转换
select name from user where telno=18722222222这样虽然可以查出数据,但是会导致全表扫描。
需要修改为
select name from user where telno='18722222222'如果需要进行 join 的字段两表的字段类型要相同
不然也不会命中索引。
四、java语言学习
-
学习了java8中lambda表达式和stream流:
①函数作为参数传递进入方法中;
②Function,Predicate;
③可以和map, filter, limit, sorted, count, min, max, sum, collect 搭配使用;
⑤替代匿名内部类
-
了解了java中泛型的使用,可以根据参数的类型决定调用某个方法。
-
了解熟悉了Clean Code,从文件签名、代码提交、日志、监控、参数检查、异常处理、程序返回值以及Dubbo接口规范等方面熟悉掌握代码规范。
①参数检查使用ParamCheck类,其他可用Preconditions类进行检查;
②监控命名采用 RBA_BASEINFO_QUERY_HOSUEINFO_COUNT (部门_系统_key 的形式)
③日志采用logback进行日志打印,使用占位符输入参数,要有参数,表明上下文
④程序返回值使用了APIResponse进行封装,优先返回空list,而不是NULL
-
过了一遍Code Review,了解了编码过程中可能存在的一些不规范的代码,以后尽量避免:
①文件签名规范
②参数检查采用ParamCheck,而非Preconditions
③代码监控应规范,TMonitorKey采用部门_系统_key 的形式
④Param类应实现toString()方法
⑤返回成功使用APIResponse.returnSuccess()
⑥JSR参数检验使用@Validated注解检验
⑦判断错误后,应决定是否中断方法,返回值
⑧返回空list,而不是NULL
⑨代码逻辑严谨,判断应清晰(较难)
-
代码规范:
阅读了《唯品会Java开发手册》1.0.2版,总结了在项目中经常用到的一些规则,如下:(一) 命名规约
Rule 9. 【推荐】如果使用到了通用的设计模式,在类名中体现,有利于阅读者快速理解设计思想
正例:OrderFactory, LoginProxy ,ResourceObserver(三) 注释规约
Rule 6. 【强制】类、类的公有成员、方法的注释必须使用Javadoc规范,使用/** xxx */格式,不得使用//xxx方式(四) 方法设计
Rule 2. 【推荐】方法的语句在同一个抽象层级上Rule 5. 【推荐】方法参数最好不超过3个,最多不超过7个Rule 7.【强制】所有的子类覆写方法,必须加@Override注解(六) 控制语句
Rule 1. 【强制】if, else, for, do, while语句必须使用大括号,即使只有单条语句Rule 2.【推荐】少用if-else方式,多用哨兵语句式以减少嵌套层次(七) 基本类型与字符串
Rule 1. 原子数据类型(int等)与包装类型(Integer等)的使用原则
1.1 【推荐】需要序列化的POJO类属性使用包装数据类型
1.2 【推荐】RPC方法的返回值和参数使用包装数据类型
1.3 【推荐】局部变量尽量使用基本数据类型
2)集合需要包装类型,除非使用数组,或者特殊的原子类型集合。
3)泛型需要包装类型,如
ResultRule 3. 数值equals比较的原则
3.1【强制】 所有包装类对象之间值的比较,全部使用equals方法比较
3.2【强制】 BigDecimal需要使用compareTo()
3.3【强制】 Atomic* 系列,不能使用equals方法。因为 Atomic* 系列没有覆写equals方法。
Rule 4. 数字类型的计算原则
4.1【强制】数字运算表达式,因为先进行等式右边的运算,再赋值给等式左边的变量,所以等式两边的类型要一致
Rule 6. 字符串拼接的原则
6.1 【推荐】 当字符串拼接不在一个命令行内写完,而是存在多次拼接时(比如循环),使用StringBuilder的append()。
其实每条用
+进行字符拼接的语句,都会new出一个StringBuilder对象,然后进行append操作,最后通过toString方法返回String对象。所以上面两个错误例子,会重复构造StringBuilder,重复toString()造成资源浪费。(八) 集合处理
Rule 1. 【推荐】底层数据结构是数组的集合,指定集合初始大小
Rule 3. 【强制】不要在foreach循环里进行元素的remove/add操作,remove元素可使用Iterator方式
Rule 4. 【强制】使用entrySet遍历Map类集合Key/Value,而不是keySet 方式进行遍历
Rule 6. 【强制】高度注意各种Map类集合Key/Value能不能存储null值的情况
Map
Key
Value
HashMap Nullable Nullable ConcurrentHashMap NotNull NotNull TreeMap NotNull Nullable Rule 11. 【推荐】如果Key只有有限的可选值,先将Key封装成Enum,并使用EnumMap
Rule 12. 【推荐】Array 与 List互转的正确写法
// list -> array,构造数组时不需要设定大小 String[] array = (String[])list.toArray(); //WRONG; String[] array = list.toArray(new String[0]); //RIGHT String[] array = list.toArray(new String[list.size()]); //RIGHT,但list.size()可用0代替。 // array -> list //非原始类型数组,且List不能再扩展 List list = Arrays.asList(array); //非原始类型数组, 但希望List能再扩展 List list = new ArrayList(array.length); Collections.addAll(list, array); //原始类型数组,JDK8 List myList = Arrays.stream(intArray).boxed().collect(Collectors.toList()); //原始类型数组,JDK7则要自己写个循环来加入了(八) 集合处理
Rule 2. 【推荐】尽量使用线程池来创建线程
(十) 异常处理
8.3 【强制】不能在finally块中使用return,finally块中的return将代替try块中的return及throw Exception
(十二) 其他规约
Rule 1. 【参考】尽量不要让魔法值(即未经定义的数字或字符串常量)直接出现在代码中
Rule 2. 【推荐】时间获取的原则
1)获取当前毫秒数System.currentTimeMillis() 而不是new Date().getTime(),后者的消耗要大得多。
Rule 3. 【推荐】变量声明尽量靠近使用的分支
-
tns-csc-provider-base暴露出来的接口是如何被tns-csc-provider或其他项目发现并实现的:明白了tns-csc-provider-base是通过打包jar包的方式被诸如tns-csc-provider等项目引用,而dubbo-provider是将service暴露到zookeeper上,dubbo-customer在zookeeper上进行消费。
-
了解了Param、Vo、md的区别:
Param通常是前端传给后端的参数,定义Param类
Vo通常是后端给前端返回数据,定义Vo类
md通常是后端与数据库进行交互,定义md类
-
学习并使用@Diff和@Not Null注解:

-
查看了设计模式中较常用的单例、工厂、抽象工厂、装饰者、观察者、外观等模式:
设计模式
应用实例
单例模式 多线程的线程池、网络连接池。懒汉式单例,饿汉式单例 工厂模式 有很多种类的畜牧场,如养马场用于养马,养牛场用于养牛 抽象工厂模式 农场中除了像畜牧场一样可以养动物,还可以培养植物,如养马、养牛、种菜、种水果等 装饰模式 Java I/O 标准库的设计。InputStream 的子类 FilterInputStream,OutputStream 的子类 FilterOutputStream,
Reader 的子类 BufferedReader 以及 FilterReader,
还有 Writer 的子类 BufferedWriter、FilterWriter 以及 PrintWriter 等,它们都是抽象装饰类。
观察者模式 “人民币汇率”的升值或贬值对进口公司的进口产品成本或出口公司的出口产品收入以及公司的利润率的影响 外观模式 主要用于降低程序之间的耦合度。 -
判断list方法一般不用list != null,而使用Collectionutils.isNotEmpty(list)。既会判断空,也会判断size不为0
-
了解@Autowired和@Resource:
@Autowired是默认按照类型装配的 @Resource默认是按照名称装配的;
-
学习并总结分页查询的用法:
①直接使用继承了PageCondition的param进行查询,可使用PageHelper.startPage方法进行分页查询,(当不需要处理返回的数据,直接返回给前端使用时):

②使用while循环,并在while循环内部对page和limit进行递增赋值,完成分页查询(适用不与前端交互,直接在后端对数据进行处理的情况):
③使用while循环加PageHelper.startPage方法,(适用于分页是为了后端加快查询与计算速度,并且查出的数据需要进行处理,而传给前端的数据并不需要分页):
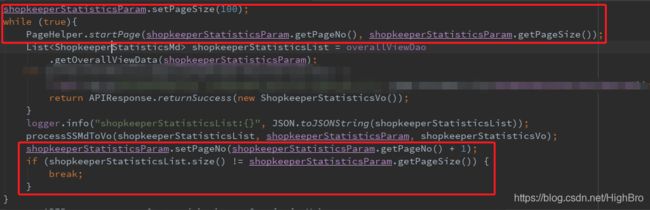
-
在查看物料系统代码时,遇到了toMap方法:

不太明白(oldKey, newKey) → newKey作用,通过查博客明白了:
第一个参数MaterialHouseStockVo::getId表示选择MaterialHouseStockVo的getId作为map的key值;
第二个参数Function.identity()一个输出跟输入一样的Lambda表达式对象,表示选择将原来的对象作为map的value值;
第三个参数(oldKey, newKey) → newKey表示,如果oldKey与newKey的key值相同,选择newKey作为那个key所对应的value值。 -
学习了将数字格式化为固定格式的字符串:

String.format()返回值类型为字符串,也就是格式化的结果"%010d":若deliveryOrderId不足10位,在左边补0,补齐为10位数字。
此外还有:
%3d--可以指定宽度,不足的左边补空格 %-3d--左对齐
五、实际开发相关
-
查询日志快捷键
G:从最新开始搜索
?ERROR:搜索ERROR
n:上翻
N:下翻
q:离开
-
yapi上定义接口
定义接口的请求参数和返回数据:
POST请求参数通常包括Body(form、json、file、raw)、Query、Headers(根据Body的类型而改变)
GET请求参数通常包括Query
返回数据通常包括:ver、ret、errmsg、errcode、data等。
-
自动生成serialVersionUID:进行设置,alt+enter对应类名,Add serialVersionUID field:

-
在与前端联调时,前端访问请求时,出现403访问拒绝错误。
解决:在csc-base项目中EnumBusinessPermission.java中添加权限类型,并在dc项目的DcPermissions.xml中添加接口权限,即可访问成功。
-
监控报错定位:①确定项目,复制监控枚举类型,确定项目中报监控位置。
②堡垒机进入相关项目查看info日志,确定错误(G为定位到日志末尾,:ERROR为搜索ERROR,N为下一个,n为上一个);
grep '吴冰峰' dc-web-error-logfile.log | grep 'saveCleanProvider' dc-web-error-logfile.log
③确定不了,可复制trace id,到info中搜索,找到所做的操作。grep -A 5 "trace id" info.log
-
通过跳板机查看日志时,heli -p 直接进去的是测试日志,开发日志需要通过ssh 192.168.0.0连接开发机器。
-
学习less命令查看日志:
操作键
效果
空格键 向下翻动一页 [PageDown]
向下翻动一页 [PageUp] 向上翻动一页 /字符串 向下查询“字符串”的功能 ?字符串 向上查询“字符串”的功能 n 重复前一个查询 N 反向重复前一个查询 q 离开 -
学习两种根据mybatis-generator插件生成相应的mapper的方法:
使用mybatis-generator-core依赖进行生成,https://blog.csdn.net/qq_38455201/article/details/79194792
-
idea快捷键:
alt+7:查看类结构图:
ctrl+alt+U:查看类继承关系图:
-
判空list使用CollectionUtils.isNotEmpty()
判空Api用ApiResponseUtil.isSuccessWithData()
-
①权限处理(包括登陆人城市区域权限)放在controller层;
参数检验例如ParamCheck放在remoteService的checkParams()方法中,而业务检验一般放在process()中;
业务处理通常放在service层,尤其涉及到事务处理的必须放在service层
②Param、Vo、Md中变量名称应该统一,通常命名为数据库中该字段驼峰类型名称
③传给前端值时一般使用自建Vo,有多少值传多少值,而不使用数据库Vo直接传前端
④一般将不包括数据库交互的数据处理写入util的Build方法中,显得代码整洁
六、基础原理探索
-
观察者模式
意图:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
主要解决:一个对象状态改变给其他对象通知的问题,而且要考虑到易用和低耦合,保证高度的协作。
何时使用:一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都将得到通知,进行广播通知。
观察者模式的主要角色如下:
①抽象主题(Subject)角色:也叫抽象目标类,它提供了一个用于保存观察者对象的聚集类和增加、删除观察者对象的方法,以及通知所有观察者的抽象方法。(ObservableService
②具体主题(Concrete Subject)角色:也叫具体目标类,它实现抽象目标中的通知方法,当具体主题的内部状态发生改变时,通知所有注册过的观察者对象。(OrderChildObservableServiceImpl extends AbstractObservableimplements ObservableService )
③抽象观察者(Observer)角色:它是一个抽象类或接口,它包含了一个更新自己的抽象方法,当接到具体主题的更改通知时被调用。(AbstractObserver)
④具体观察者(Concrete Observer)角色:实现抽象观察者中定义的抽象方法,以便在得到目标的更改通知时更新自身的状态。(OrderChildObserver extends AbstractObserver)
具体应用:回顾rba-datacenter项目中观察者模式:
①在“任务调度中心”配置同步任务,通过“bean模式:syncAllData”对应项目中的注解: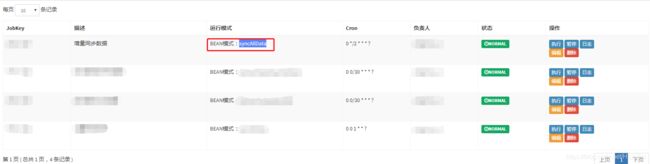
②点击执行,会首先找到项目中task文件注解@MethodJobHandlerAnn("syncAllData"):
③执行父类AbstractTscheduleTask中的doSchedule方法: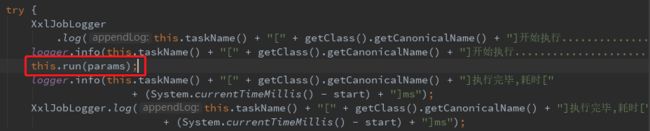
④执行子类run操作,通过param类型确定执行的子类run方法:
⑤子类run方法会首先加载ObservableService,找出其中存在的service,进行循环调用:(抽象主题(Subject)角色)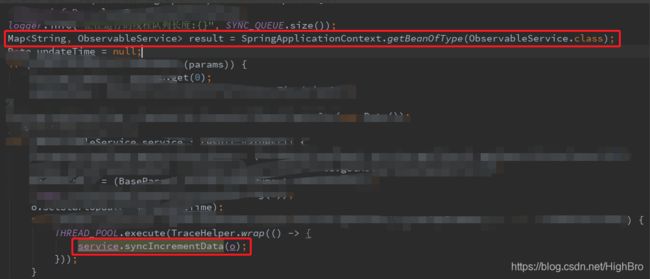
ObservableService中存在的service,是在观察者方法中,初始化加载进去的:
⑥进行各个观察者实现方法中进行同步操作,同样也是根据参数的不同进入不同的方法中:
⑦在方法中,会调用监视观察者方法:(具体主题(Concrete Subject)角色)
⑧进入观察者中去更新数据:(抽象观察者(Observer)角色)
⑨进行数据库的增加或更新操作,完成观察者模式:(具体观察者(Concrete Observer)角色)
-
策略模式
意图:定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换。
主要解决:在有多种算法相似的情况下,使用 if...else 所带来的复杂和难以维护。
具体应用:在rba-material中使用策略模式进行账户类型的区分,完成导入、保存、查询详情等功能:
①在物料库存中需要构建物料信息时,通过类型名调用strategyExecute方法:
②根据账户类型找到对应的构建方法:
③进入统一的接口AccountTypeStrategy,根据参数类型找到对应的实现

④通过实现获取到最终值
遇到的问题
一、postman测试
| 编号 | 问题 | 解决 |
|---|---|---|
| 1 | 接口未授权 | 添加AuthKeyName属性 |
| 2 | No provider available from registry 10.2.3.4:2080 for service devGroup | 修改default.properties中的zookeeper.url |
| 3 | java.lang.NullPointerException | 未传参数,传参后正确 |
| 4 | Internel Server Error | Cookie值过期,重新设置token |
二、java语言方面问题
- 将数据库中某一字段json类型转为Vo时,出现java.util.LinkedHashMap cannot be cast to Vo错误,解决:

-
在新增仓库完成后,需要记录日志,而看代码发现insert返回的是Integer类型,是影响的行数,如何拿到仓库id便成了一个问题,通过查看博客,明白了,mybatis是有方法来返回新插入的数据的主键id的:
通过在mapper.xml文件中insert语句中,添加:useGeneratedKeys="true" keyProperty="id“
即可通过获取实体类(即参数param)的id字段,来得到新插入的数据的主键id。
-
在进行post测试时,卡在了ParamCheck.checkNotNull检验参数处,显示参数验证错误。查看代码后,找到了问题所在,POST接口需要在参数前加@RequestBody注解
-
在项目中使用@Transactional注解来为方法添加事务,保证方法执行一致性
spring支持编程式事务管理和声明式事务管理两种方式:

三、实际开发问题
-
供应商管理列表筛选查询与默认显示顺序不一致
[BUG出现的原因]
①.代码中通过省市id进行排序,当省市id一样的时候可能显示顺序不一致
②.列表筛选查询会默认走缓存,而默认显示顺序是通过查询数据库得到的
[解决方案]
除了对省市id排序外,还添加了主键id降序排序 -
数据库查询时,使用sum标签时,在开发中应将其再次命名赋值:select sum(sold_out_gmv) sold_out_gmv from table
-
启动tomcat时,遇到错误:Error creating bean with name "testDaoImpl",但我的项目中根本不存在testDaoImpl,解决:mvn clean install
-
使用PageHelper.startpage进行分页查询时,若对查询出的数据list进行过处理后为list2,再进行new PageInfo(list2)时,会产生无数据的情况,这是因为使用lambad表达式最后进行toList后,对象类型改变了,导致list instanceof Page为false,就不会进行分页赋值。解决:可在查询出list后,先进行new PageInfo(list)操作,在处理完后,再进行pageInfo.setList(list2)操作。
-
在remoteService中应调用基础service,而不是直接调用dao,破坏分层结构。
-
在测试过程中由于调用了远程的remoteService,出现了如下错误:在远程机器上找不到该方法。这是由于远程服务尚未部署,导致在zookeeper上找不到dubbo服务。
-
与前端联调时,遇到了302错误码,302 redirect: 302 代表暂时性转移(Temporarily Moved )。
意思就是你访问网址A,但是网址A因为服务器端的拦截器或者其他后端代码处理的原因,会被重定向到网址B。解决:修改dc项目filter代码
-
compile时遇到在api中已经存在但是报错:不能识别到Vo或Param的情况,这是因为编译时是从仓库中去找,因此需要先进行api的install操作。
-
rba-datacenter发布相关问题:

解决:将项目中pom文件中的SNAPSHOT删除 
解决:将项目中pom文件中的1.0改为1.0.0 
修改root-pom的版本号 -
将数据库中某一字段json类型转为Vo时,出现java.util.LinkedHashMap cannot be cast to Vo错误,解决:

-