广告点击率预测
广告点击率预测项目,目的是通过广告和用户信息预测一个广告是否被点击。数据来自Kaggle竞赛(https://www.kaggle.com/c/avazu-ctr-prediction),源数据比较大,选取前400000条。
1. 数据读取和分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#数据读取
data_df = pd.read_csv('train_subset.csv')
#展示头部数据,分两次展示或者调整python设置达到一次展示所有特征的效果
#data_df.iloc[:, :12].head()
#data_df.iloc[:, 12:].head()
pd.set_option('display.max_columns', None)
data_df.head(20)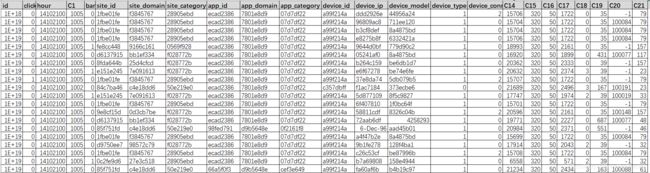
大致推断一下一些关键特征的业务含义(源数据已经脱敏):
| 特征名称 |
业务含义推断 |
| id | 数据唯一的ID |
| click | 是否点击广告 |
| hour | 数据收集时间(yymmddhh) |
| banner_pos | 广告投放位置信息 |
| site_id | 广告客户网站(某个游戏网站 vs 商家网站) |
| site_domain | 网站某种大类(游戏 vs 电商) |
| site_category | 网站某种小类(手游 vs 零食) |
| app_id | 广告提供商APP |
| app_domain | APP大类(社交类 vs 内容类) |
| app_category | APP类别(微博 vs 头条) |
| device_id | 设备硬件地址(可能是电脑mac地址 vs 手机 IMEI,每个设备唯一) |
| device_ip | 设备互联网地址(可能多个设备公用) |
| device_model | 设备型号 |
| device_type | 设备类型(手机 vs 电脑) |
| device_conn_type | 设备连接类型(Wifi vs 4G) |
| C14 |
- |
| C15 | - |
| C16 | - |
| C17 | - |
| C18 | - |
| C19 | - |
| C20 | - |
| C21 | - |
对于前面四个特征 - id、 click、hour、 banner_pos, 其中,每条数据id都不一样,是没有意义的,显然可以直接删除。
click是标签,对标签分布的理解是必不可少的。
pos_counts = data_df[data_df.click==1].count()['click']
neg_counts = data_df[data_df.click==0].count()['click']
print("positive rate: ", pos_counts/data_df.count()['click'])
print("negtive rate: ", neg_counts/data_df.count()['click'])通过上述的数据,可以很容易看出被点击的次数要远小于没有被点击的次数,所以数据是不平衡的,但这个不平衡还没有严重到像1000:1那么夸张。
由于样本的不平衡,使用准确率是不明智的,所以评估指标我们选用F1-score.
hour特征
时间特征有可能对我们帮助,比如是否凌晨点击率要低于早上的,是否早上的要低于下午的?
#先把hour的格式调整一下
data_df['hour'] = pd.to_datetime(data_df['hour'],format = '%y%m%d%H',errors = 'raise')
#打印一下hour特征
data_df.hour.describe()
其实从上述的结果中可以看到,时间的区间为10-21的00点到10-21的02点,也就是2个小时的间隔。所以在使用这个特征的时候,可以把小时的特征提取出来,因为日期都是一样的
banner_pos特征
这是广告投放的位置,从直观上来看对广告点击的结果影响比较大,所以做一下可视化的分析并更好地理解这个特征。
groups_click = data_df[data_df.click==1].groupby('banner_pos').count()
groups_no_click = data_df[data_df.click==0].groupby('banner_pos').count()
plt.title('Visualization of Banner Position and Click Events')
plt.bar(range(len(groups_no_click)),list(groups_no_click['click']),label = '0',width = 0.5)
plt.bar(range(len(groups_click)),list(groups_click['click']),bottom = list(groups_no_click['click']), tick_label =list(groups_click.index), label = '1',width = 0.5)
plt.legend(title = 'click')
plt.xlabel('banner_pos')
plt.xticks(rotation=90)
plt.show()生成完上面的图之后能感觉到这个特征还是蛮重要的,而且由于banner_pos=2,4,5,7的样本比较少,在图里不那么直观。所以我们就尝试打印一下一个表格。
#calculate total amount for a row
row_total = data_df.groupby('banner_pos').count()['click']
#calculate amount for zero & one
zero_total = data_df[data_df.click==0].groupby('banner_pos').count()['click']
one_total = data_df[data_df.click==1].groupby('banner_pos').count()['click']
#calculate result
zero_result = zero_total / row_total
one_result = one_total / row_total
#create DataFrame and add column values from above
rate_df = pd.DataFrame(index = groups_click.index.values,columns=['0','1'])
rate_df['0'] = list(zero_result)
rate_df['1'] = list(one_result)
rate_df.index.name = 'banner_pos'
rate_df.columns.name = 'click'
rate_df
site特征
site_features = ['site_id', 'site_domain', 'site_category']
data_df[site_features].describe()
app特征
app_features = ['app_id', 'app_domain', 'app_category']
data_df[app_features].describe()重点研究一下app_category特征是否跟标签有较强的关系,为了直观一些,画出app_category的直方图。
category_click = data_df[data_df.click==0].groupby('app_category').count()['click']
category_no_click = data_df[data_df.click==1].groupby('app_category').count()['click']
category_total = data_df.groupby('app_category').count()['click']
zero_result2 = category_click/category_total
one_result2 = category_no_click/category_total
plt.title('CTR for app_category feature')
plt.bar(np.array(
.index),zero_result2,label = '0',width = 0.5)
plt.bar(np.array(category_click.index),one_result2,bottom = zero_result2, tick_label =np.array(category_click.index), label = '1',width = 0.5)
plt.legend(title = 'click')
plt.xlabel('app_category')
plt.xticks(rotation=90)
plt.show()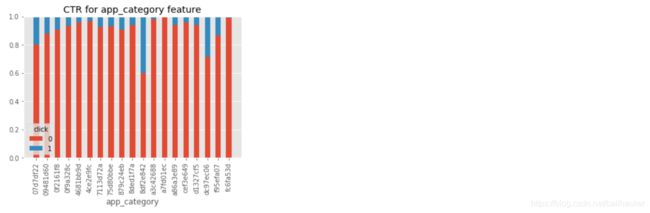
device特征
device_features = ['device_id', 'device_ip', 'device_model', 'device_type', 'device_conn_type']
data_df[device_features].astype('object').describe()
同样,画出device_conn_type的直方图(device_type类似)
device_conn_type_click = data_df[data_df.click==0].groupby('device_conn_type').count()['click']
device_conn_type_no_click = data_df[data_df.click==1].groupby('device_conn_type').count()['click']
device_conn_type_total = data_df.groupby('device_conn_type').count()['click']
zero_result3 = device_conn_type_click/device_conn_type_total
one_result3 = device_conn_type_no_click/device_conn_type_total
plt.title('CTR for device_conn_type feature')
plt.bar(np.array(device_conn_type_click.index),zero_result3,label = '0',width = 0.5)
plt.bar(np.array(device_conn_type_click.index),one_result3,bottom = zero_result3, tick_label =np.array(device_conn_type_click.index), label = '1',width = 0.5)
plt.legend(title = 'click')
plt.xlabel('device_conn_type')
plt.xticks(rotation=90)
plt.show()其他特征:C1, C14-C21
c_features = ['C1', 'C14', 'C15', 'C16', 'C17', 'C18', 'C19', 'C20', 'C21']
data_df[c_features].astype('object').describe()
拿C1为例,数据集里共有6个不同的类别,同样看一下C1和点击率的直方图。
c1_click = data_df[data_df.click == 0].groupby('C1').count()['click']
c1_no_click = data_df[data_df.click == 1].groupby('C1').count()['click']
c1_total = data_df.groupby('C1').count()['click']
one_result4 = c1_click / c1_total
zero_result4 = c1_no_click / c1_total
plt.bar(np.array(c1_click.index),zero_result4,label = '0',width = 0.5)
plt.bar(np.array(c1_click.index),one_result4,bottom = zero_result4,label = '1',tick_label=np.array(c1_click.index),width = 0.5)
plt.title('CTR for C1 feature')
plt.xlabel('C1')
plt.legend(title = 'click')
plt.show()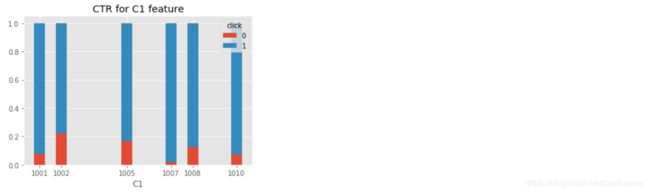
2. 特征构造
这里的特征有必要构造的不多,hour是一个。可以根据上面显示的hour特征情况,将其变成离散变量:也就是2014-10-21 00点对应到0, 2014-10-21 01点对应到1, 2014-10-21 02点对应到2。
data_df['hour'] = data_df['hour'].dt.hour3. 特征转化
将类别型特征独热编码,并删除原始特征。为此,需要先删除稀疏特征。
data_df.drop('device_id', axis=1, inplace=True)
data_df.drop('device_ip', axis=1, inplace=True)
data_df.drop('site_id', axis=1, inplace=True)
data_df.drop('app_id', axis=1, inplace=True)
one_hot_columns = data_df.columns.values.tolist()
one_hot_columns.remove('click')
data_df=pd.get_dummies(data_df,columns = one_hot_columns)构建训练数据和测试数据
feature_names = np.array(data_df.columns[data_df.columns != 'click'].tolist())
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
data_df[feature_names].values,
data_df['click'].values,
test_size=0.2,
random_state=42
)
print (X_train.shape, X_test.shape, y_train.shape, y_test.shape)
(319999, 1076) (80000, 1076) (319999,) (80000,)
4. 特征选择
独热编码之后,特征一下子变得非常多,需要做一下特征选择,这里使用了逻辑回归+L1正则。
from sklearn.linear_model import LogisticRegression
from sklearn.feature_selection import SelectFromModel
from sklearn.metrics import f1_score
from sklearn.model_selection import KFold, cross_val_score
import warnings
params_c = np.logspace(-4, 1, 11)
warnings.filterwarnings('ignore')
cv_score=[]
for c in params_c:
lr_clf = LogisticRegression(penalty='l1', C=c)
scores = cross_val_score(lr_clf,X_train,y_train,cv=10,scoring='f1')
cv_score.append(scores.mean())
c_best = params_c[cv_score.index(max(cv_score))]通过最优超参c_best,重新训练训练集数据,并选出特征。
# 通过c_best值,重新在整个X_train里做训练,并选出特征。
lr_clf = LogisticRegression(penalty='l1', C=c_best)
lr_clf.fit(X_train, y_train) # 在整个训练数据重新训练
select_model = SelectFromModel(lr_clf, prefit=True)
selected_features = select_model.get_support() # 被选出来的特征重新构造训练数据和测试数据。
# 重新构造feature_names
feature_names = feature_names[selected_features]
# 重新构造训练数据和测试数据
X_train = X_train[:, selected_features]
X_test = X_test[:, selected_features]5. 模型训练与评估
这里使用决策树算法做分类。
from sklearn.tree import DecisionTreeClassifier
params_min_samples_split = np.linspace(5, 20, 4)
params_min_samples_leaf = np.linspace(2, 10, 5)
params_max_depth = np.linspace(4, 10, 4)
#构造决策树并做交叉验证。
model = GridSearchCV(estimator =DecisionTreeClassifier(),param_grid={'max_depth':params_max_depth},cv=10)
model.fit(X_train,y_train)
#在测试数据上预测,打印在测试集上的结果
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))

说明一下,因为这里只选取了源数据的前400000条,一些关键特征作用被弱化了。像hour特征或许跟标签有很大关系,但是选取的数据里只有三个值,训练过程发现不了这层关系,导致最终的预测结果不太理想。