《FlowNet3D》(CVPR2019)--直接从点云中估计场景流
暴走兔学习了CVPR 2019的论文:《FlowNet3D: Learning Scene Flow in 3D Point Clouds》,为了更好的理解该论文(年纪大了容易忘),在此做个总结性的阅读笔记,争取言简意赅、简单粗暴地描述出论文作者们所作的工作,如果能对相关研究方向的小伙伴有借鉴意义,那就更好了。不喜勿喷,直接移步就好了~
项目地址:https://github.com/xingyul/flownet3d
一句话介绍:
FlowNet3D----是一种点云的端到端的场景流估计网络,能够直接从点云中估计场景流。
输入:连续两帧的原始点云;
输出:第一帧中所有点所对应的密集的场景流。
如图所示:

flownet3d网络为第一帧中的每个点估计一个平移流向量,以表示它在两帧之间的运动。
FlowNet3D架构
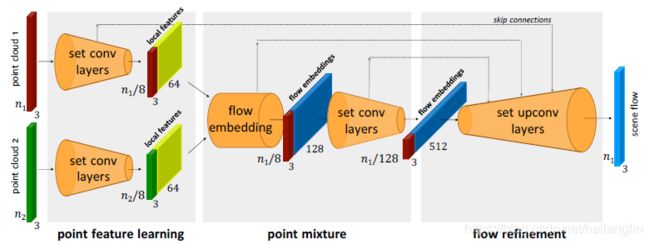
如图所示(图是从论文截的,试了几次也不知道怎么去掉博客水印,抱歉啊),该模型具有三个关键模块,分别为:
(1)点特征学习(point feature learning)-- 作用:分层点云特征学习。
(2)点混合(point mixture)--作用:混合两个点云。
(3)流细化(flow refinement)--作用: 将与中间点关联的流嵌入上采样到原始点,并在最后一层预测所有原始点的流。
向上采样的步骤是通过一个可学习的新层--set upconv层来实现的。
点云处理层
在这些模块下是三个可训练的点云处理层:

4个set conv层--作用: 学习深度点云功能;
1个flow embedded层--作用: 流嵌入层,学习两个点云之间的几何关系,推断运动;
4个set upconv层(对应于四个set conv层)--作用: 以一种可学习的方式向上采样和传播点特性。
每个可学习层对函数h采用多层感知器,用几个线性层宽来参数化Linear-BatchNorm-ReLU层。详细的层参数如表1所示。
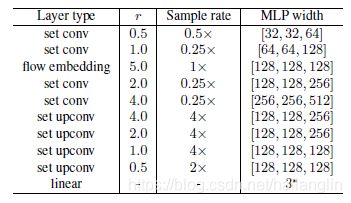
(这个表格也是论文中的,同不知道怎么去博客水印,抱歉)
因为点云自身的不规则性和无序性,传统的用于2d图像的卷积并不适合对其进行直接处理。在2017年,学术界提出了pointnet以及后来改进的pointnet++,是可以直接处理3d点云的神经网络,所以这篇论文是延用了pointnet++的网络结构。
<具体公式这里就不贴了,请移步论文看公式>
数据集
FlyingThings3D及kitti
额,FlyingThings3D的这些数据集中,有一个100G的,一个80多G的,我下了半个月还没下完,下载链接为:
https://lmb.informatik.uni-freiburg.de/resources/datasets/SceneFlowDatasets.en.html

数据集由stereo和从ShapeNet中采样的具有多个随机移动对象的场景中呈现的RGB-D图像。
有大约32k的立体图像与地面真视差和光流图。作者们随机选取2万个作为训练集,2000个作为测试集。不使用RGB图像,而是通过视差图到3D点云和光流到场景流来预处理数据。
测试结果
在flying things3d数据集的测试结果

度量指标为:
端点误差(End-point-error, EPE)
流量估计精度(Acc)(<0.05或5%,<0.1或10%)。
<补充说明:EPE(endpoint error):评价光流法的一种方法。
指所有像素点的gound truth和预测出来的光流之间差别距离(欧氏距离)的平均值,越低越好。>在KITTI场景流数据集上的场景流估计。
度量指标为:
EPE,ACC.

使用KITTI sceneflow数据集进行场景流估计。(前100帧用于调整我们的模型。所有方法都在剩下的50帧上求值。)
