深度学习与神经网络-吴恩达(Part2Week2)-优化算法
一、Mini-batch梯度下降法
前面介绍的向量化方法能够让我们高效的处理m个样本数据,模型输入的也就是m个样本按列堆叠而成的矩阵X,同样地,输入数据的标签也是m个样本标签按列堆叠而成的矩阵Y。但是以海量训练样本(m很大,几百万甚至几千万的数据量)作为输入的话,这样做的计算成本依然会很高。因为只有处理完所有的训练样本才能进行一次梯度下降法,然后还需要重新处理所有的训练数据才能进行下一步梯度下降法。那么我们能不能在处理完所有训练样本之前,先让梯度下降法处理一部分呢?

为了达到上面的目的,我们可以把训练样本集分割为小一点的子训练集(Mini-batch)。例如对于一个含有五百万样本的的训练集,我们依次取1000个样本作为子训练集,这样就可以得到5000个子训练集。

将整个训练集拆分为5000个子训练集后,我们依次对每个子训练集进行梯度下降法(也称为Mini-batch gradient descent),过程如下:

下面对Mini-batch梯度下降法做进一步的讲解,包括其和Batch梯度下降法的异同以及Mini-batch梯度下降法中Mini-batch size的选择。首先我们来看看两种梯度下降法成本函数的变化趋势。

从上图中可以看出,当使用Batch梯度下降法时,每次迭代都需要遍历整个训练集,可以预期每次迭代的成本都会下降,所以成本函数J是迭代次数的函数,并保持下降趋势。但使用Mini-batch梯度下降法时,并不是每次迭代都是下降的。如果我们要做出成本函数J{t}的图,因为其只与X{t},Y{t}有关,也就是每次迭代下你都在训练不同的样本集,我们得到的应该是如上图右部分所示,走向朝下,但有更多的噪声,噪声较多的原因在于样本中每个子训练集的计算难易程度不一样(有的子训练集可能是残缺的样本,成本函数较大)。
对于Mini-batch梯度下降法我们唯一需要确定的是Mini-batch梯度下降法的size,当Mini-batch size=m时,那么就等同于Batch梯度下降法;当Mini-batch size=1时,那么就等同于stochastic梯度下降法(也就是随机梯度下降法);那接下来让我们分析下这两种极端下成本函数的优化情况,batch度下降法从某个初始点开始下降,相对噪声低些,幅度也大一点(图中蓝线所示)。相反,在stochastic梯度下降法中,从某一点开始,每次迭代只对一个样本进行梯度下降,大部分时候都朝着全局最小值靠近,有时候会远离最小值,原因在于根据某个样本所计算的梯度项所代表的方向不对,因此tochastic梯度下降法是有很多噪音的(图中紫线所示);当然这两种极端算法也有各自的弊端,Batch梯度下降法弊端在于单次迭代耗时太长,stochastic梯度下降法则会失去向量化所带来的加速,因此效率低下。Mini-batch梯度下降法则介于两者之间,一方面采用了向量化的方法进行加速,另一方面还不需要等待整个训练集被处理完就可以进行后续工作,上面的例子中,对训练样本进行一次遍历我们可以执行5000次梯度下降。Mini-batch梯度下降法从某个初始点开始,虽然它不会总朝着最小值靠近,但它比随机梯度下降更持续地靠近最小值的方向(图中绿线所示),它也不一定在很小的范围内收敛或者波动(通过减小学习率可以解决)。
对于Mini-batch size的选取一般有以下几个原则:如果训练集较小(m<=2000),Mini-batch size=m,即直接使用Batch梯度下降法。如果训练集较大,Mini-batch size=64,128,256,512......2^n,根据实际的GPU/CPU内存上限来确定,最好为2的次方倍。

# GRADED FUNCTION: random_mini_batches
import numpy as np
import math
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
np.random.seed(seed) # To make your "random" minibatches the same as ours
m = X.shape[1] # number of training examples
mini_batches = []
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation]
shuffled_Y = Y[:, permutation].reshape((1,m))
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = int(math.floor(m/mini_batch_size)) # number of mini batches of size mini_batch_size in your partitionning
for k in range(0, num_complete_minibatches):
### START CODE HERE ### (approx. 2 lines)
mini_batch_X = shuffled_X[:, k*mini_batch_size : (k+1)*mini_batch_size]
mini_batch_Y = shuffled_Y[:, k*mini_batch_size : (k+1)*mini_batch_size]
### END CODE HERE ###
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
### START CODE HERE ### (approx. 2 lines)
mini_batch_X = shuffled_X[:, num_complete_minibatches*mini_batch_size : m]
mini_batch_Y = shuffled_Y[:, num_complete_minibatches*mini_batch_size : m]
### END CODE HERE ###
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches二、指数加权平均

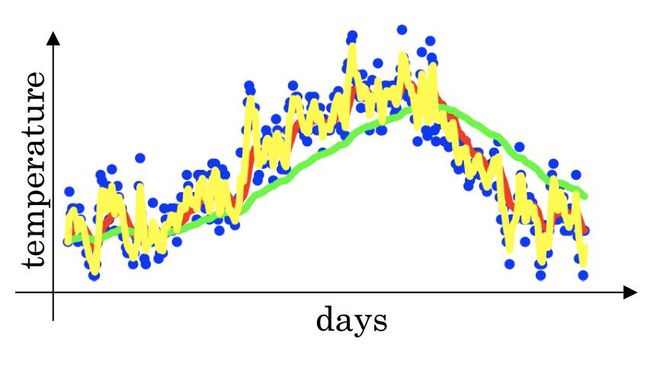
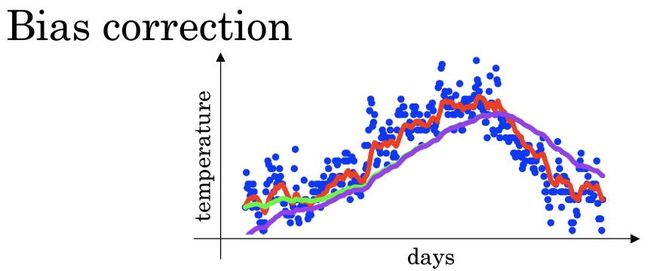
那么上图中的红色曲线是如何计算的呢?我们这里给出详细过程,公式里具体的数值后面会做详细讲解,大家先理解大致流程:

没错,红色曲线中每个具体的值就与Vi相对应,接下来我们对上面的公式进行一个归纳:
![]()
接下来我们对式子里的各个变量的定义进行讲解,Vt可视为1/(1-Betal)的每日温度的平均值,当Betal=0.9时,Vt也就对应10天的平均值,指数加权平均曲线对应图中红线。当Betal=0.98时,Vt也就对应50天的平均值,指数加权平均曲线对应图中绿线。对于Betal较大的情况,其波动更小,更加平坦,缺点是曲线进一步右移,因为现在所平均的温度值更多。接下来让我们看看比较极端的情况,Betal=0.5,曲线如黄线所示,由于仅平均了两天的温度,平均的数据较少,得到的曲线含有较多噪音和异常值。
为什么上面的做法可以起到一个取平均值的作用了,我们不妨以下面的一个例子来说明:

我们将V100按最上面的公式展开,可以得到最下面的式子,将该式子分为两部分:数据项(也就是具体的温度值theta),权重系数项(和Betal相关的项)。可以看到最终指数加权平均的结果其实就是对应数据项和系数项乘积的累加和,我们将这两部分分别画在两个坐标系中。
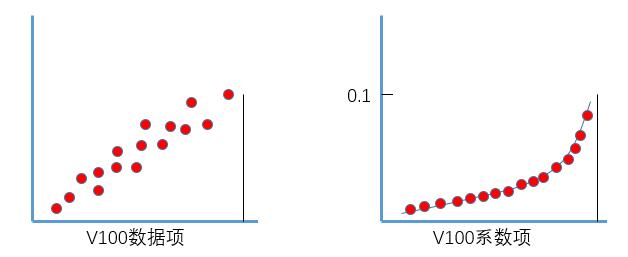
分析上图中系数项的变化趋势,呈指数衰减,从(1-Betal)开始随着天数逐渐衰减,当Belta=0.9,大概经过10天权重下降到当日权重的三分之一(0.1*0。9^10近似等于0.035,大概为0.1的三分之一),超过10天权重下降到不到当日权重的三分之一,由于该部分权重系数很小,对最终的加权平均贡献很小,所以当Belta=0.9就近似认为是前10天的温度平均数。同理,当Belta=0.98,大概经过50天权重下降到当日权重的三分之一(0.1*0.98^50=0.036),只有当日往前50天的权重系数有效,所以为是前50天的温度平均数。
三、指数加权平均的偏差修正
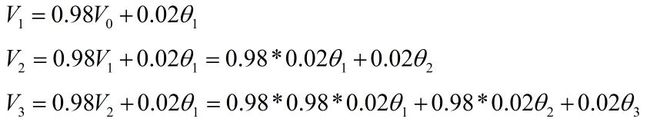
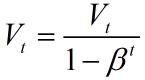
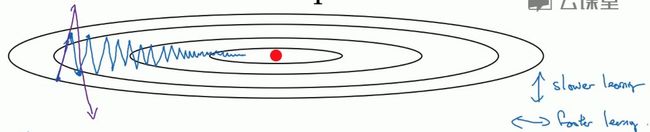
四、Momentum梯度下降法

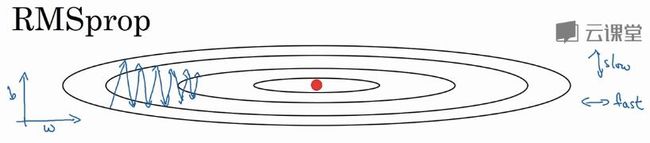
五、RMSprop梯度下降法

六、Adam梯度下降法

七、超参数设置(经验值)

八、学习率衰减

基于以上分析,我们可以在每次迭代时对学习率进行一次衰减,这里引入了新的超参数decay_rate,epoch-num表示迭代的次数,具体公式如下:

当然还有另外一些经验公式:
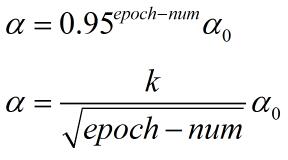
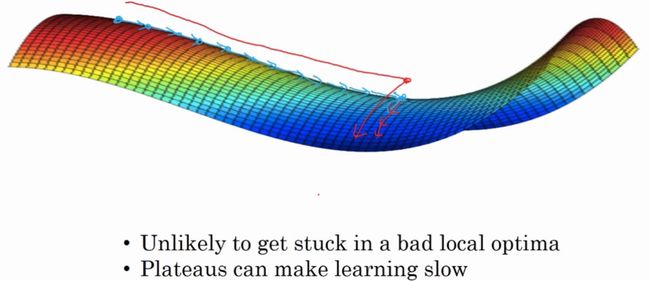
九、局部最优的问题

通过上面的分析我们可知,训练神经网络,尤其是深度神经网络,不太可能困在局部最优中,而鞍点往往对我们的优化有影响。平稳段会减缓学习,因为平稳段是一块平坦区域,其中导数长时间接近0。