匈牙利算法
首先来说明一下匈牙利算法是解决什么问题的
简单来说匈牙利算法是寻找通过增广路,并通过扩展增广路找出二分图的最大匹配数的算法。
从上面一句话我们可以得到几个关键词,二分图,二分图的匹配,二分图的最大匹配数,增广路。
接下来我会一一解释这几个关键词(概念)的具体含义;
二分图:
二分图又称作二部图,是图论中的一种特殊模型。 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的
子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G
为一个二分图。
这是百度百科上的解释,也就是说在一个图中,如果可以把这个图中的点集分成两部分,而边集中的每条边连接的
两个顶点必须分别是这两部分点集中的一个点。那么这个图就是二分图。
如下图就能转换成一个二分图。
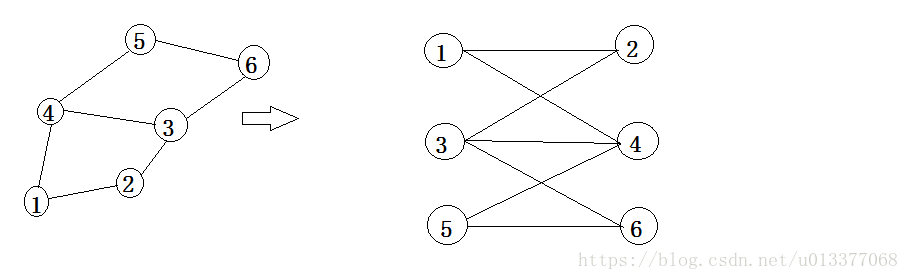
图g 图G
一个图为二分图的充分必要条件是至少有两个点,并且如果存在回路的话,那么回路的长度(长度指的是该回路连接
的点的数目)必须为偶数。
二分图的匹配:
给定一个二分图G,在G的一个子图M中,M的边集{E}中的任意两条边都不依附于同一个顶点,则称M是一个匹配。
如下图:
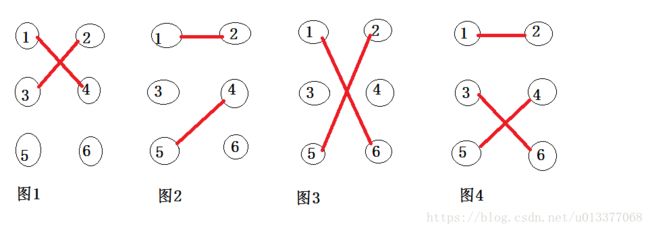
例如图1,图2,图3,图4中任意两条边的连接的顶点都没有相同的(换句话说,n条边必须连接2 * n个不相同的顶点)。
所以他们都是图G的匹配。
极大匹配(Maximal Matching)是指在当前已完成的匹配下,无法再通过增加未完成匹配的边的方式来增加匹配
的边数。最大匹配(maximum matching)是所有极大匹配当中边数最大的一个匹配。选择这样的边数最大的
子集称为图的最大匹配问题。(匈牙利算法就是找出这样一个最大匹配的边数);
如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。
如图4就是二分图的一个完全匹配(同时也是最大匹配),但是最大匹配不总是完全匹配。
接下来我们就要讲解匈牙利算法的思路,增广路的概念也会在其中解释。
在介绍增广路之前,还要明白交替路的概念。
交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边...形成的路径叫交替路。
增广路:从一个未匹配点出发,走交替路,如果途径另一个未匹配点,则这条交替路称为增广路。
如图。
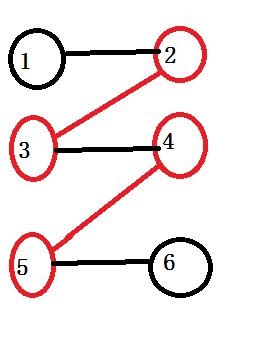
1 -> 2->3->4->5->6
显然增广路的一个性质就是非匹配的边比已经匹配的边多一条。如果我们将增广路的匹配边换成非匹配边,
将非匹配边换成匹配边,那么经过这一番操作后匹配边就增加了了一条。
所以匈牙利算法的核心是:不断寻找增广路,并扩展增广路。不断重复这一过程直到找不到增广路为止。
匈牙利算法大致就是上述过程。
用文字描述就是:
1.首先从左边第一个点出发,寻找增广路 1->2(没错,这个也是增广路),然后翻转关系变为1->2。
2.从左边第二个点出发,寻找增广路3->1->2->4,然后翻转关系变为3->1->2->4。
3.从左边第三个点出发,寻找增广路5->4->1->2->3->6,然后翻转关系5->4->1->2->3->6。
4.至此我们已经找到二分图G的最大匹配数(同时这个也是完全匹配)。
以上就是匈牙利算法的讲解
—————————————————————————————————————————
例题:
poj 3041 Asteroids
点击打开链接
该题的大致意思:
在小行星区域中,存在很多小行星,为了行驶方便,需要将小行星全部消灭,但是激光炮一次
只能消灭一行或一列的小行星。给你一个N*N的地图,和小行星分布情况,问最小发射几次激
光炮才能消灭所有的小行星。
我们可以将每行,每列看做一个点,对于每个小行星(x,y),我们可以把x和y连接起来。这样
我们就构建了一个二分图。
如题中给的样例:
3 4
1 1
1 3
2 2
我们可以构建一个二分图G
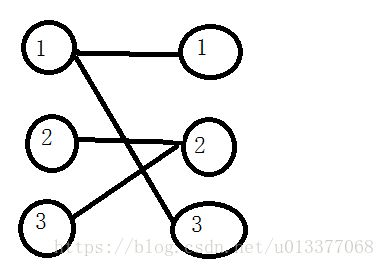
图G中的每一个点相当于原图中的一行,或一列,而图G中的每一个边相当于原图中的小行星。
这样消灭所有的小行星==消灭所有的边。
所以该问题可以转换为怎样用最小点覆盖所有的边。也就是最小点覆盖问题。
在样例中,左边第一个点,右边第二个点可以覆盖所有的边,所以激光炮需要发射两次,分别向
第一行,第二列发射,就能消灭所有的小行星了。
而根据König定理最小点覆盖数=最大匹配数,我们可以转换为求二分图的最大匹配数。这样我们就
可以用匈牙利算法解题了。
代码如下:
#include
#include
const int INF = 505;
int dfs(int u); //搜索以u点为起点的增广路经,如果能搜到返回1,不能返回0;
int edge[INF][INF]; //以邻接矩阵的形式建立二分图。
int n, k;
int vx[INF], vy[INF]; //vy存的是在y集合中已经匹配过的x点,所以匹配边i->j的表示方法为vy[i]=j;
int vis[INF]; //用来标记在搜索过程中某点是否已经在增广路中,如果已经在就不用在向增广路添加了。
/*
3 4
1 1
1 3
2 2
3 2
Sample Output
2
*/
int main()
{
scanf("%d %d",&n, &k);
memset(edge, -1, sizeof(edge));
for(int i=1; i <= k; i++)
{
int x, y;
scanf("%d %d", &x, &y);
edge[x][y] = 1;
}
memset(vx, -1, sizeof(vx));
memset(vy, -1, sizeof(vy)); //一开始,二分图中没有点匹配。
int result = 0; //一开始二分图匹配数为0;
for(int u = 1; u <= n; u++) //对二分图中左边的每个点寻找增广路。
{
memset(vis, 0, sizeof(vis));
result += dfs(u) ; //如果知道增广路,那么 匹配数+1;
}
printf("%d\n", result) ;
return 0;
}
int dfs(int u)
{
for(int v = 1; v <= n; v++)
{
if(edge[u][v] == 1 && vis[v] == 0) //如果u,v两点之间有边(也就是两点可以匹配),
//并且v不再增广路中
{
vis[v] = 1; //将 v点加入增广路。
if(vy[v] == -1 ||dfs(vy[v]) == 1) //如果该点为为非匹配点
//或者能根据该点匹配的x中点找到未匹配点
{
vx[u] = v; //翻转关系
vy[v] = u;
return 1;
}
}
}
return 0;
}