1、常见文本相似度计算方法
常见的短文本相似度计算方法目前有很多中,但这些短文本相似度计算方法都只是提取了短文本中的浅层特征,而无法提取短文本中的深层特征。目前常见的文本相似度计算方法有:
1)简单共有词。对文本分词之后,计算两本文本中相同词的数量,然后除以更长的文本中词的数量。
2)编辑距离。简单理解就是指两个字符串之间,由一个字符串转成另一个字符串所需的最少编辑操作次数。
3)TF-ITF +余弦相似度/距离计算方法。利用TF-ITF提取关键词,将文本转换成向量空间模型,然后计算两个文本在向量空间中的余弦相似度或者之间的距离(常见的距离有曼哈顿距离、欧几里得距离)。
4)Jaccard系数。对文本分词后,对两个文本进行交集和并集的处理,用交集中词的数量除以并集中词的数量来表示两个文本之间的相似度。
5)主题模型。基于LDA和LSA主题模型提取文档的主题(推荐基于统计的LDA主题模型),然后根据主题向量的余弦相似度来表示两个文本之间的相似度。
对于短文本除了所具有的浅层特征之外,还有很对深层特征,比如句子的语义,语法等。基于目前很火的 word2vec 可以很好的计算两个词之间的相似度,目前也有将word2vec运用到句子相似度计算上来。比如常见的方法有:
1)对句子进行分词,得到每个词的向量表示,然后将这些向量进行叠加生成一个新的向量,将这个新的向量作为该句子的向量。通过余弦相似度或者欧几里得距离来计算相似度。
2)针对第1种,在向量叠加时还可以给每个词加上权重系数,以此来区分重要词和非重要词。
3)将句子当做词放入到word2vec模型中直接训练出句子的向量表示。
2、skip-thought vectors 论文解读
2.1 skip-thought模型结构
skip-thought模型结构借助了skip-gram的思想。在skip-gram中,是以中心词来预测上下文的词;在skip-thought同样是利用中心句子来预测上下文的句子,其数据的结构可以用一个三元组表示 $(s_{t-1}, s_t, s_{t+1})$ ,输入值 $s_t$ ,输出值 $(s_{t-1}, s_{t+1})$ ,具体模型结构如下图:

途中 $
$s_{t}\quad I\;could\;see\;the\;cat\;on\;the\;steps$
$s_{t-1}\quad I\;got\;back\;home$
$s_{t+1} \quad This\;was\;strange$
2.2 神经网络结构
skip-thought模型的神经网络结构是在机器翻译中最常用的 Encoder-Decoder 架构,而在 Encoder-Decoder 架构中所使用的模型是GRU模型(具体GRU模型见这篇)。因此在训练句子向量时同样要使用到词向量,编码器输出的结果为句子中最后一个词所输出的向量。具体模型实现的公式如下:
编码阶段:
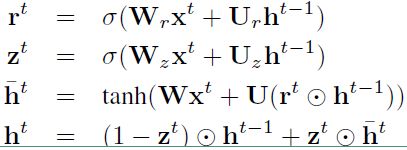
公式和GRU网络中的公式一模一样。$h_t$ 表示 $t$ 时刻的隐层的输出结果。
解码阶段:以 $s_{t+1}$ 为例,$s_{t-1}$ 相同:
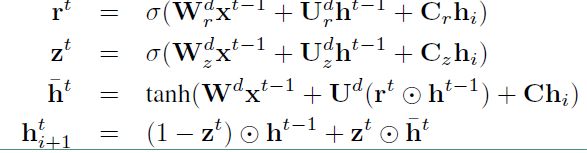
其中 $C_r, C_z, C$ 分别用来对重置门,更新门,隐层进行向量偏置的。
2.3 词汇扩展
词汇扩展主要是为了弥补我们的 Decoder 模型中词汇不足的问题。具体的做法就是:
1)我们用 $V_{w2v}$ 表示我们训练的词向量空间,用 $V_{rnn}$ 表示我们模型中的词向量空间,在这里 $V_{w2v}$ 是远远大于 $V_{rnn}$ 的。
2)引入一个矩阵 $W$ 来构建一个映射函数:$f: V_{w2v} -> V_{rnn}$ 。使得有 $ v^{'} = Wv $ ,其中 $ v \in V_{w2v}, v^{'} \in V_{rnn} $ 。
3)通过映射函数就可以将任何在 $V_{w2v}$ 中的词映射到 $V_{rnn}$ 中。
3、Tensorflow实现skip-thought
skip-thought已经添加到Tensorflow models中,只需要安装TensorFlow models就可以使用,具体安装流程:
1)在GitHub上下载源码:git clone --recurse-submodules https://github.com/tensorflow/models
2)将源码放到相应的位置:例如我是在Anaconda3中的虚拟环境下安装的tensorflow,则相应的路径:C:\Users\jiangxinyang\Anaconda3\envs\jiang\Lib\site-packages\tensorflow
具体GitHub地址:https://github.com/tensorflow/models/tree/master/research/skip_thoughts