个性化广告推荐系统(实战)-1-协同过滤篇
一. 数据集介绍与实现分析
1. 数据集介绍
本项目使用天池数据集,淘宝广告展示/点击数据集 – Ad Display/Click Data
raw_sample
淘宝网站中随机抽样了114万用户8天内的广告展示/点击日志(2600万条记录)构成原始的样本数据:
| 字段 | 描述 |
|---|---|
| user_id | 脱敏过的用户ID |
| adgroup_id | 脱敏过的广告单元ID |
| time_stamp | 时间戳 |
| pid | 资源位(资源展示位置,如:侧边和底部) |
| noclk | 为1代表没有点击;为0代表点击 |
| clk | 为0代表没有点击;为1代表点击 |
ad_feature
本数据集涵盖了raw_sample中全部广告的基本信息(约80万条):
| 字段 | 描述 |
|---|---|
| adgroup_id | 脱敏过的广告ID |
| cate_id | 脱敏过的商品类目ID |
| campaign_id | 脱敏过的广告计划ID |
| customer_id | 脱敏过的广告主ID |
| brand_id | 脱敏过的品牌ID |
| price | 商品的价格 |
user_profile
本数据集涵盖了raw_sample中全部用户的基本信息(约100多万用户):
| 字段 | 描述 |
|---|---|
| userid | 脱敏过的用户ID |
| cms_segid | 微群ID |
| cms_group_id | cms_group_id |
| final_gender_code | 性别 1:男,2:女 |
| age_level | 年龄层次; 1234… |
| pvalue_level | 消费档次,1:低档,2:中档,3:高档 |
| shopping_level | 购物深度,1:浅层用户,2:中度用户,3:深度用户 |
| occupation | 是否大学生 ,1:是,0:否 |
| new_user_class_level | 城市层级 |
behavior_log
本数据集涵盖了raw_sample中全部用户22天内的购物行为(共七亿条记录):
1.user:脱敏过的用户ID;
2.time_stamp:时间戳;
3.btag:行为类型, 包括以下四种:
类型 | 说明
pv | 浏览
cart | 加入购物车
fav | 喜欢
buy | 购买
4.cate_id:脱敏过的商品类目id;
5.brand_id: 脱敏过的品牌id;
2. 项目实现分析
1.数据to业务
- 广告点击的样本数据 raw_sample.csv:体现的是用户对不同位置广告点击、没点击的情况
- 广告基本信息数据 ad_feature.csv:体现的是每个广告的类目(id)、品牌(id)、价格特征
- 用户基本信息数据 user_profile.csv:体现的是用户群组、性别、年龄、消费购物档次、所在城市级别等特征
- 用户行为日志数据 behavior_log.csv:体现用户对商品类目(id)、品牌(id)的浏览、加购物车、收藏、购买等信息
- 我们是在对非搜索类型的广告进行点击率预测和推荐(没有搜索词,没有广告的内容特征信息)
2.推荐业务处理流程
召回 --> 排序 --> 过滤
-
离线处理业务流:
- raw_sample.csv ==> 历史样本数据
- ad_feature.csv ==> 广告特征数据
- user_profile.csv ==> 用户特征数据
- raw_sample.csv + ad_feature.csv + user_profile.csv ==> CTR点击率预测模型
- behavior_log.csv ==> 评分数据 --> user-cate/brand评分数据 -->协同过滤 --> top-N cate/brand --> 关联广告
- 协同过滤召回 ==> top-N cate/brand -->关联对应的广告完成召回
-
在线处理业务流:
- 数据处理部分:
- 实时行为日志 ==> 实时特征 --> 缓存
- 实时行为日志 ==> 实时商品类别/品牌 --> 实时广告召回集 --> 缓存
- 推荐任务部分:
- CTR点击率预测模型 + 广告/用户特征(缓存) + 对应的召回集(缓存) ==> 点击率排序 --> top-N广告推荐结果
- 数据处理部分:
3.图示实现流程
- 离线计算:

- 实时计算:
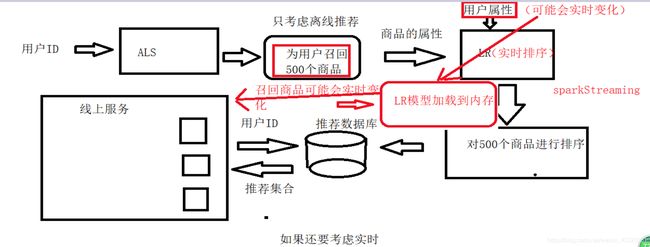
- 实时计算:
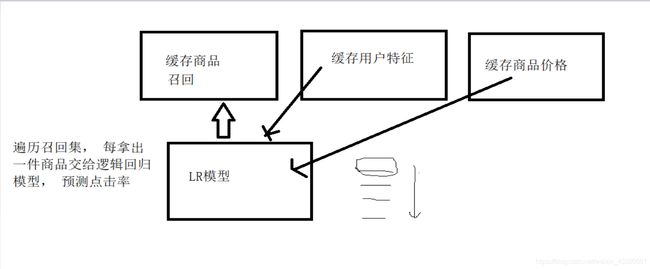
4.涉及技术
- Flume:日志数据收集
- Kafka: 实时日志数据处理队列
- HDFS: 分布式存储数据
- Spark SQL: 离线处理
- Spark ML/MLlib:模型训练
- Redis: 缓存(数据集非常大使用HBase)
二. 环境准备
三. ALS-召回
3.0 用户行为数据拆分
- 为了方便读者练习,特写一个函数,用于从海量数据中读取一部分数据
import pandas as pd
# 读取数据集
reader = pd.read_csv('/behavior_log.csv',chunksize=100,iterator=True)
# 划取100000条数据
count = 0
for chunk in reader:
count += 1
if count == 1:
chunk.to_csv('test_behavior_log.csv', index = False)
elif count>1 and count<=1000:
chunk.to_csv('test_behavior_log.csv', index=False, mode='a', header=False)
else:
break
pd.read_csv('test_behavior_log.csv')
3.1 预处理behavior_log数据集
- 1.创建spark session
import os
# 配置spark driver和pyspark运行时,所使用的python解释器位置
PYSPARK_PYTHON = '/home/hadoop/miniconda3/envs/data/bin/python'
JAVA_HOME = '/home/hadoop/app/jdk1.8.0_191'
# 当存在多个版本时,不指定很可能会导致出错
os.environ['PYSPARK_PYTHON'] = PYSPARK_PYTHON
os.envirom['PYSPARK_DRIVER_PYTHON'] = PYSPARK_PYTHON
os.envirom['JAVA_HOME'] = JAVA_HOME
# spark配置信息
from pyspark import SparkConf
from pyspark.sql import SparkSession
# 名字任意
SPARK_APP_NAME = 'preprocessingBehaviorLog'
SPARK_URL = 'spark://192.168.199.188:7070'
conf = SparkConf()
# 创建spark config对象
config = (
("spark.app.name", SPARK_APP_NAME),
("spark.executor.memory", "6g"), # 设置该app启动时所占用的内存,默认1g
("spark.master", SPARK_URL),
("spark.executor.cores", "4"), # 设置spark executor使用的CPU核心数
)
# 查看更详细配置及说明:https://spark.apache.org/docs/latest/configuration.html
config.setAll(config)
# 利用config对象,创建spark session
spark = SparkSession.builder.config(conf=conf).getOrCreate()
- 2.从hdfs中加载csv文件为DataFrame,并设置结构
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, LongType
# 构建结构对象
schema = StructType([
StructField('userId', IntegerType()),
StructField('timestamp', LongType()),
StructField('btag', StringType()),
StructField('cateId', IntegerType()),
StructFiedl('brandId', IntegerType())
])
# 从hdfs加载数据为DataFrame,并设置结构
behavior_log_df = spark.read.csv('/datasets/behavior_log.csv', header=True, schema=schema)
# 查看DataFrame,默认显示前20条
behavior_log_df.show()
# 查看一下数据类型,结构
behavior_log_df.printSchema()
+------+----------+----+------+-------+
|userId| timestamp|btag|cateId|brandId|
+------+----------+----+------+-------+
|558157|1493741625| pv| 6250| 91286|
|558157|1493741626| pv| 6250| 91286|
|558157|1493741627| pv| 6250| 91286|
|728690|1493776998| pv| 11800| 62353|
|332634|1493809895| pv| 1101| 365477|
|857237|1493816945| pv| 1043| 110616|
|619381|1493774638| pv| 385| 428950|
|467042|1493772641| pv| 8237| 301299|
|467042|1493772644| pv| 8237| 301299|
|991528|1493780710| pv| 7270| 274795|
|991528|1493780712| pv| 7270| 274795|
|991528|1493780712| pv| 7270| 274795|
|991528|1493780712| pv| 7270| 274795|
|991528|1493780714| pv| 7270| 274795|
|991528|1493780765| pv| 7270| 274795|
|991528|1493780714| pv| 7270| 274795|
|991528|1493780765| pv| 7270| 274795|
|991528|1493780764| pv| 7270| 274795|
|991528|1493780633| pv| 7270| 274795|
|991528|1493780764| pv| 7270| 274795|
+------+----------+----+------+-------+
only showing top 20 rows
root
|-- userId: integer (nullable = true)
|-- timestamp: long (nullable = true)
|-- btag: string (nullable = true)
|-- cateId: integer (nullable = true)
|-- brandId: integer (nullable = true)
- 3.分析数据集字段的类型和格式
- 查看是否有空值
- 查看每列数据的类型
- 查看每列数据的类别情况
print('查看userId的数据情况:', behavior_log_df.groupBy('userId').count().count())
print("查看btag的数据情况:", behavior_log_df.groupBy("btag").count().collect()) # collect会把计算结果全部加载到内存,谨慎使用
# 只有四种类型数据:pv、fav、cart、buy
# 这里由于类型只有四个,所以直接使用collect,把数据全部加载出来
print("查看cateId的数据情况:", behavior_log_df.groupBy("cateId").count().count())
print("查看brandId的数据情况:", behavior_log_df.groupBy("brandId").count().count())
print("判断数据是否有空值:", behavior_log_df.count(), behavior_log_df.dropna().count())
# 约7亿条目723268134 723268134
# 得知:本数据集无空值条目,可放心处理
# 统计每个用户对各类商品的pv、fav、cart、buy数量
cate_count_df = behavior_log_df.groupBy(behavior_log_df.userId, behavior_log_df.cateId).pivot("btag",["pv","fav","cart","buy"]).count()
cate_count_df.printSchema()
cate_count_df.first()
查看user的数据情况: 1136340
查看btag的数据情况: [Row(btag='buy', count=9115919), Row(btag='fav', count=9301837), Row(btag='cart', count=15946033), Row(btag='pv', count=688904345)]
查看cateId的数据情况: 12968
查看brandId的数据情况: 460561
判断数据是否有空值: 723268134 723268134
root
|-- userId: integer (nullable = true)
|-- cateId: integer (nullable = true)
|-- pv: integer (nullable = true)
|-- fav: integer (nullable = true)
|-- cart: integer (nullable = true)
|-- buy: integer (nullable = true)
Row(userId=1061650, cateId=4520, pv=2326, fav=None, cart=53, buy=None)
3.2 根据用户对类目偏好打分训练ALS模型
- 1.打分规则,函数封装,处理每一行数据
def process_row(r):
"""
偏好评分规则:
m:用户对应的行为次数
该偏好权重比例,根据业务调参,上线评测获得进一步权重分配:
pv: if m<=20: score=0.2*m; else score=4
fav: if m<=20: score=0.4*m; else score=8
cart: if m<=20: score=0.6*m; else score=12
buy: if m<=20: score=1*m; else score=20
注意:全部设成浮点数,spark运算时,对数据比较敏感,要保持数据类型都一致
"""
pv_count = r.pv if r.pv else 0.0
fav_count = r.fav if r.fav else 0.0
cart_count = r.cart if r.cart else 0.0
buy_count = r.buy if r.buy else 0.0
pv_score = 0.2*pv_count if pv_count<=20 else 4.0
fav_score = 0.4*fav_count if fav_count<=20 else 8.0
cart_score = 0.6*cart_count if cart_count<=20 else 12.0
buy_score = 1.0*buy_count if buy_count<=20 else 20.0
rating = pv_score + fav_score + cart_score + buy_score
# 返回用户ID,分类ID,用户对分类的偏好打分
return r.userId, r.cateId, rating
- 2.用户对商品类别的打分数据
cate_rating_df = cate_count_df.rdd.map(process_row).toDF(['userId', 'cateId', 'rating'])
cate_rating_df
DataFrame[userId: bigint, cateId: bigint, rating: double]
- 3.使用pyspark中的ALS矩阵分解方法实现CF评分预测
from pyspark.ml.recommendation import ALS
# 利用打分数据训练ALS模型
als = ALS(userCol='userId', itemCol='cateId', ratingCol='rating',checkpointInterval=2)
model = als.fit(cate_rating_df)
- 4.模型训练好后,调用方法使用
# 为所有用户推荐Top-N个类别
ret = model.recommendForAllUsers(3)
ret.show()
+------+--------------------+
|userId| recommendations|
+------+--------------------+
| 148|[[3347, 12.547271...|
| 463|[[1610, 9.250818]...|
| 471|[[1610, 10.246621...|
| 496|[[1610, 5.162216]...|
| 833|[[5607, 9.065482]...|
| 1088|[[104, 6.886987],...|
| 1238|[[5631, 14.51981]...|
| 1342|[[5720, 10.89842]...|
| 1580|[[5731, 8.466453]...|
| 1591|[[1610, 12.835257...|
| 1645|[[1610, 11.968531...|
| 1829|[[1610, 17.576496...|
| 1959|[[1610, 8.353473]...|
| 2122|[[1610, 12.652732...|
| 2142|[[1610, 12.48068]...|
| 2366|[[1610, 11.904813...|
| 2659|[[5607, 11.699315...|
| 2866|[[1610, 7.752719]...|
| 3175|[[3347, 2.3429515...|
| 3749|[[1610, 3.641833]...|
+------+--------------------+
only showing top 20 rows
- 5.模型保存
model.transform
model.save('/models/userCateRatingALSModel.obj')
## 从hdfs中加载模型的代码
# from pyspark.ml.recommendation import ALSModel
# als_model = ALSModel.load('/models/userCateRatingALSModel.obj')
- 6.召回到redis
# 召回之前,先开启redis服务,在此不做赘述
import redis
host j= '192.168.199.188'
port = 6379
def recall_cate_by_cf(partition):
# 建立redis连接池
pool = redis.ConnectionPool(host=host, post=port)
# 建立redis客户端
client = redis.Redis(connection_pool=pool)
for row in partition:
client.hset('recall_cate', row.userId, [i.cateId for i in row.recommendations])
# 对每个分片的数据进行处理
result.foreachPartition(recall_cate_by_cf)
# 总的条目数,查看redis中总的条目数是否一致
result.count()
1136340
3.3根据用户对品牌偏好打分训练ALS模型
- 1.对品牌的偏好打分
# 代码同3.2部分
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
schema = StructType([
StructField("userId", IntegerType()),
StructField("brandId", IntegerType()),
StructField("pv", IntegerType()),
StructField("fav", IntegerType()),
StructField("cart", IntegerType()),
StructField("buy", IntegerType())
])
# 从hdfs加载预处理好的品牌的统计数据
brand_count_df = spark.read.csv("/preprocessing_dataset/brand_count.csv", header=True, schema=schema)
# brand_count_df.show()
def process_row(r):
# 处理每一行数据:r表示row对象
# 偏好评分规则:
# m: 用户对应的行为次数
# 该偏好权重比例,次数上限仅供参考,具体数值应根据产品业务场景权衡
# pv: if m<=20: score=0.2*m; else score=4
# fav: if m<=20: score=0.4*m; else score=8
# cart: if m<=20: score=0.6*m; else score=12
# buy: if m<=20: score=1*m; else score=20
# 注意这里要全部设为浮点数,spark运算时对类型比较敏感,要保持数据类型都一致
pv_count = r.pv if r.pv else 0.0
fav_count = r.fav if r.fav else 0.0
cart_count = r.cart if r.cart else 0.0
buy_count = r.buy if r.buy else 0.0
pv_score = 0.2*pv_count if pv_count<=20 else 4.0
fav_score = 0.4*fav_count if fav_count<=20 else 8.0
cart_score = 0.6*cart_count if cart_count<=20 else 12.0
buy_score = 1.0*buy_count if buy_count<=20 else 20.0
rating = pv_score + fav_score + cart_score + buy_score
# 返回用户ID、品牌ID、用户对品牌的偏好打分
return r.userId, r.brandId, rating
# 用户对品牌的打分数据
brand_rating_df = brand_count_df.rdd.map(process_row).toDF(["userId", "brandId", "rating"])
- 2.训练模型并根据品牌爱好推荐
from pyspark.ml.recommendation import ALS
als = ALS(userCol='userId', itemCol='brandId', ratingCol='rating', checkpointInterval=2)
# 利用打分数据,训练ALS模型
# 此处训练时间较长
model = als.fit(brand_rating_df)
# model.recommendForAllUsers(N) 给用户推荐TOP-N个物品
model.recommendForAllUsers(3).show()
# 将模型进行存储
model.save("/models/userBrandRatingModel.obj")
# 测试存储的模型
from pyspark.ml.recommendation import ALSModel
# 从hdfs加载模型
my_model = ALSModel.load("/models/userBrandRatingModel.obj")
my_model
# model.recommendForAllUsers(N) 给用户推荐TOP-N个物品
my_model.recommendForAllUsers(3).first()